随着人工智能和大数据的爆炸式增长,如何合理地组织和表示海量的知识变得至关重要。知识图谱作为图数据,积累和传递现实世界的知识。知识图谱可以有效地表示复杂信息;因此,近年来迅速受到学术界和工业界的关注。为了加深对知识图谱的理解,对该领域进行了系统综述。具体来说,关注知识图谱的机遇和挑战。首先从两个方面回顾了知识图谱的发展机遇: (1)基于知识图谱构建的人工智能系统; (2)知识图谱的潜在应用领域。然后,深入讨论了该领域面临的知识图谱表示、知识获取、知识补全、知识融合和知识推理等技术挑战;本综述将为知识图谱的未来研究和发展提供新的思路。 https://www.zhuanzhi.ai/paper/93a14b6709974a3bbd86c10302053fea1. 引言
知识在人类的生存和发展中起着至关重要的作用。学习和表示人类知识是人工智能(AI)研究中的关键任务。虽然人类能够理解和分析周围环境,但AI系统需要额外的知识才能获得相同的能力并解决现实场景中的复杂任务(Ji et al, 2021)。为了支持这些系统,我们已经看到了根据不同的概念模型来表示人类知识的许多方法的出现。在过去十年中,知识图谱已经成为这一领域的标准解决方案,也是学术界和工业界的研究趋势(Kong et al, 2022)。 **知识图谱被定义为积累和传递真实世界知识的数据图谱。知识图谱中的节点表示感兴趣的实体,边表示实体之间的关系(Hogan et al, 2021;Cheng et al, 2022b)。**这些表示利用了形式化语义,这使得计算机能够高效且无歧义地处理它们。例如,实体“比尔·盖茨”可以与实体“微软”联系起来,因为比尔·盖茨是微软的创始人;因此,他们在现实世界中是有关系的。 由于知识图谱在机器可读环境下处理异构信息方面的重要意义,近年来对这些解决方案持续开展了大量研究(Dai et al, 2020b)。所提出的知识图谱最近被广泛应用于各种人工智能系统(Ko等,2021;Mohamed et al, 2021),如推荐系统、问答系统和信息检索。它们也被广泛应用于许多领域(例如教育和医疗保健),以造福人类生活和社会。(Sun et al, 2020;Bounhas et al, 2020)。 因此,知识图谱通过提高人工智能系统的质量并应用到各个领域,抓住了巨大的机遇。然而,知识图谱的研究仍然面临着重大的技术挑战。例如,现有的从多个来源获取知识并将其集成到典型的知识图谱中的技术存在很大的局限性。因此,知识图谱在现代社会中提供了巨大的机遇。然而,它们的发展存在着技术上的挑战。因此,有必要对知识图谱进行机遇与挑战的分析,以更好地理解知识图谱。 为深入了解知识图谱的发展历程,全面分析了知识图谱面临的机遇和挑战。首先,从知识图谱显著提升人工智能系统性能和受益于知识图谱的应用领域两个方面讨论了知识图谱的机遇;然后,考虑到知识图谱技术的局限性,分析了知识图谱面临的挑战;本文的主要贡献如下:
**知识图谱研究综述。**对现有的知识图谱研究进行了全面的调研。详细分析了知识图谱的最新技术和应用进展。
**知识图谱机遇。**本文从利用知识图谱的基于知识图谱的人工智能系统和应用领域的角度,研究了知识图谱的潜在机会。研究了知识图谱对人工智能系统的好处,包括推荐系统、问答系统和信息检索。然后,通过描述知识图谱在教育、科研、社交媒体、医疗等各个领域的当前和潜在应用,探讨了知识图谱对人类社会的深远影响。
**知识图谱挑战。**本文对知识图谱面临的重大技术挑战提供了深入的见解。特别地,从知识图谱表示、知识获取、知识图谱补全、知识融合和知识推理等5个方面,分析了目前具有代表性的知识图谱技术的局限性。
论文的其余部分组织如下。第2节对知识图谱进行概述,包括知识图谱的定义和现有研究的分类。第3节和第4节分别介绍了相关的AI系统和应用领域,探讨了知识图谱的机遇。第5节详细介绍了基于这些技术的知识图谱面临的挑战。最后,在第6节对本文进行总结。
2 概述
首先给出知识图谱的定义;然后,对该领域的重要最新研究进行了分类。 2.1 什么是知识图谱?
知识库是一种典型的数据集,它以三元组的形式表示现实世界中的事实和语义关系。当三元组被表示为一个边为关系、节点为实体的图时,它被认为是一个知识图谱。通常,知识图谱和知识库被视为同一个概念,可以互换使用。此外,知识图谱的模式可以定义为一个本体,它显示了特定领域的属性以及它们之间的关系。因此,本体构建是知识图谱构建的一个重要阶段。
2012年,谷歌首次提出了知识图谱,介绍了他们的知识库谷歌知识图谱(Ehrlinger and W¨oß, 2016)。随后,引入并采用了许多知识图谱,例如:
DBpedia,一个知识图谱,它试图从维基百科中发现有语义意义的信息,并将其转化为DBpedia中一个有效的结构良好的本体知识库(Auer et al, 2007)。 * Freebase,一个基于多个来源的知识图谱,提供结构化和全球性的信息资源(Bollacker et al, 2008)。 * Facebook的实体图(entity graph),这是一个知识图谱,可以将用户配置文件的非结构化内容转换为有意义的结构化数据(Ugander et al, 2011)。 * Wikidata,一个跨语言的面向文档的知识图谱,支持许多网站和服务,如维基百科(Vrande ci´c and Kr¨otzsch, 2014)。 * Yago,是一个高质量的知识库,包含大量的实体及其对应关系。这些实体是从维基百科和WordNet等多个来源提取的(Rebele et al, 2016)。 * WordNet,是一个衡量单词之间语义相似度的词汇知识库。该知识库包含许多层次概念图来分析语义相似度(Pedersen et al, 2004)。
知识图谱是由节点和边组成的有向图,其中一个节点表示一个实体(真实对象或抽象概念),两个节点之间的边表达了两个实体之间的语义关系(Bordes et al, 2011)。资源描述框架(Resource Description Framework, RDF)和标签属性图(Labeled Property Graphs, LPGs)是两种典型的知识图谱表示和管理方法(F¨arber等,2018;博肯,2020)。知识图谱的基本单位是三元组(主语、谓语、宾语)(或(头、关系、尾)),即(比尔·盖茨,创始人,微软)。由于关系不一定是对称的,所以链接的方向很重要。因此,知识图谱也可以看成是头部实体通过关系边指向尾部实体的有向图
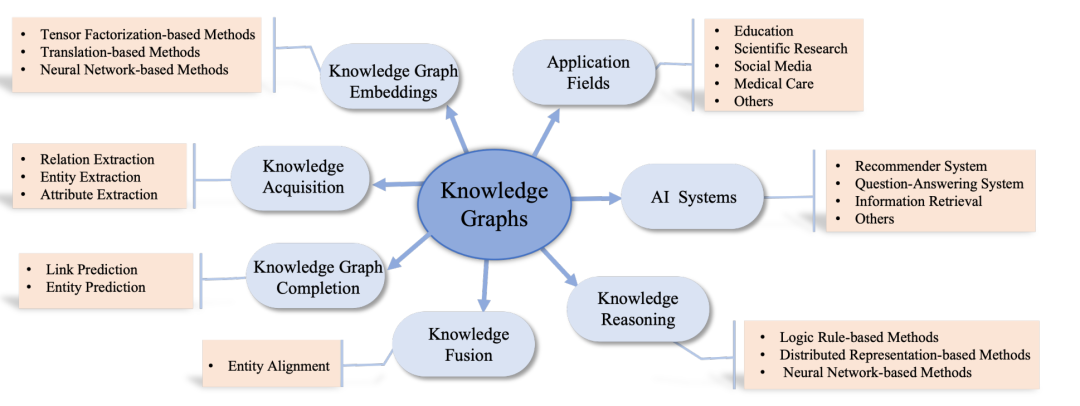
图2知识图谱研究
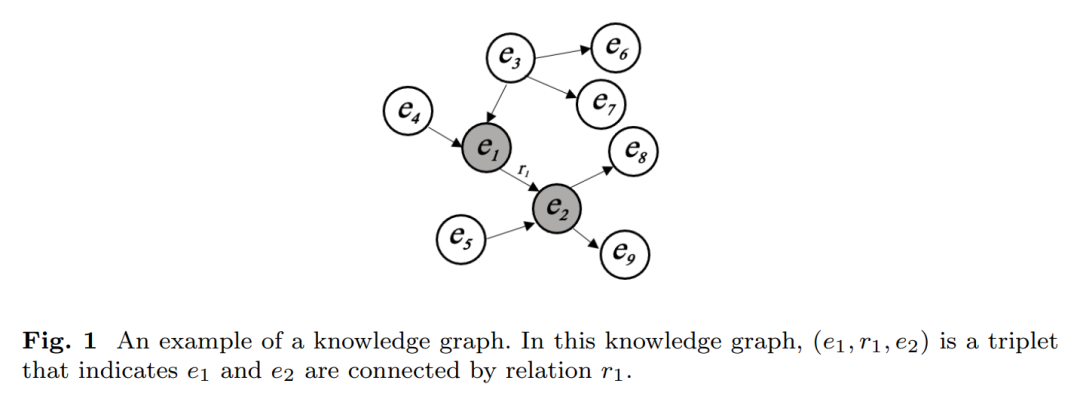
图1描绘了一个简单知识图谱的例子。如图1所示,图中颜色变暗2 的节点e1 and通过关系r连接,关系r从e1到e2。因此,e1、e2、r1可以形成三元组(e1、r1、e2),其中eand分别2 是头实体1 和尾实体。 近年来,知识图谱得到了广泛的研究兴趣。大量的研究集中在对知识图谱的探索上。对知识图谱进行了全面的综述,列出了当前该领域的7类重要研究。图2显示了关于知识图谱的最流行的研究路线的模式。其中,人工智能系统是利用知识图谱作为基础的服务,应用领域是知识图谱所触及的领域。列出这两条研究方向是为了探讨知识图谱的发展机遇。另外5个研究方向是5个主要的知识图谱技术,对应5个任务。对这5种技术进行了介绍,并强调了它们的局限性,为知识图谱面临的主要挑战提供了有益的启示。 * 知识图谱嵌入:知识图谱嵌入是知识图谱嵌入研究的中心问题之一。该任务旨在将知识图谱中的实体和关系映射到低维向量空间,从而高效地捕捉知识图谱的语义和结构(Dai等,2020b)。然后,通过机器学习模型可以有效地学习得到的特征向量。三种主要的基于三元组事实的嵌入方法如下:(a)基于张量因子分解的,(b)基于翻译的,和(c)基于神经网络的方法(Dai et al, 2020b)。 * **知识获取:**知识获取主要是对知识图谱进行建模和构建,是知识图谱研究的另一个重要研究方向。通常,知识是通过使用映射语言(如R2RML)从结构化来源导入的(Rodriguez- Muro and Rezk, 2015)。此外,知识可以从
非结构化文档(如新闻、研究论文和专利),采用关系、实体或属性提取方法(Liu et al, 2020;Yu et al, 2020;Yao et al, 2019)。 * 知识图谱完备性:尽管构建知识图谱的方法有很多,但要建立一个领域内所有知识的全面表示仍然是不可实现的。大多数知识图谱仍然缺乏大量的实体和关系。因此,对完备的知识图谱进行了大量的研究。知识图谱补全技术旨在通过预测新增的关系和实体来提高知识图谱的质量。第一个任务通常采用链接预测技术生成三元组,然后对三元组的可信度评分进行分配(Ji et al, 2021)。第二个任务采用实体预测方法来获取和整合来自外部来源的进一步信息。
**知识融合:**知识融合也是一个重要的研究方向,专注于捕获不同来源的知识,并将其集成到知识图谱中(Nguyen et al, 2020)。知识融合方法对于知识图谱的生成和完善都有重要意义。最近,实体对齐已经成为实现知识融合任务的主要方法。 * **知识推理:**通过推理来丰富知识图谱,旨在基于现有数据推断新的事实(Minervini et al, 2020),是目前的研究热点。特别是,在两个不相连的实体之间推断出新的关系,形成新的三元组。而且,通过推理出虚假的事实,知识推理具有识别错误知识的能力。知识推理的主要方法包括基于逻辑规则的方法、基于分布式表示的方法和基于神经网络的方法(Chen et al, 2020b)。 * 人工智能系统:如今,知识图谱被推荐、问答系统和信息检索工具等人工智能系统(Liang et al, 2022)广泛使用。通常情况下,知识图谱中丰富的信息可以提高解决方案的性能。因此,许多研究侧重于利用知识图谱来提高人工智能系统的性能。 * **应用领域:**知识图谱在教育、科学研究、社交媒体和医疗保健等各个领域都有众多应用(Li et al, 2020b)。提高人类生活水平,需要各种智能应用。
与其他工作不同,重点关注知识图谱的机遇与挑战。特别是,随着人工智能服务质量的提高,知识图谱在各个领域的应用将迎来巨大的机遇。相反,认为知识图谱技术的局限性是其面临的挑战。因此,讨论知识图谱表示、知识获取、知识图谱补全、知识融合、知识推理等方面的技术局限性。 3 面向人工智能系统的知识图谱
本节通过分析知识图谱对提高人工智能系统的功能所带来的优势,来说明它所带来的机遇。具体来说,有几个系统,包括推荐系统、问答系统和信息检索工具(Guo et al, 2020;邹,2020),将知识图谱用于输入数据,并从知识图谱中获益最大。除了这些系统外,其他人工智能系统,如图像识别系统(Chen et al, 2020a),也开始考虑知识图谱的特征。然而,知识图谱在这些系统中的应用并不广泛。此外,这些系统并没有直接利用知识图谱对输入数据进行性能优化。因此,详细讨论了知识图谱为推荐系统、问答系统和信息检索工具带来的优势,分析了知识图谱的发展机遇。通常,这些解决方案可以从采用知识图谱中获益,这些图谱提供了高质量的领域知识表示。表1展示了我们将在下面讨论的AI系统的摘要。
推荐系统 * 问答系统 * 信息检索
4 应用和潜力
在本节中,我们将讨论知识图谱在教育、科学研究、社会网络和健康/医疗保健四个领域的应用和潜力。尽管一些研究人员试图利用知识图谱开发其他领域的有益应用,如金融(Cheng et al, 2022c),但基于知识图谱的智能服务在这些领域相对模糊,仍然需要探索。因此,本节主要围绕教育、科研、社会网络、医疗等方面,对知识图谱的机遇进行总结。表2给出了知识图谱在这些领域的几个最新应用。 5 技术挑战
虽然知识图谱为各种服务和应用提供了极好的机会,但仍有许多挑战有待解决(Noy等,2019)。具体而言,现有知识图谱技术的局限性是推动知识图谱发展的关键挑战(Hogan et al, 2021)。因此,本节从知识图谱嵌入、知识获取、知识图谱补全、知识融合和知识推理这5种热门知识图谱技术的局限性出发,讨论知识图谱面临的挑战。 5.1 知识图谱的嵌入
知识图谱嵌入的目标是在低维向量空间中有效表示知识图谱,同时仍保留其语义(Xia et al, 2021;Vashishth et al, 2020)。首先,将实体和关系嵌入到给定知识图谱的稠密维空间,并定义评分函数衡量每个事实(三元组)的可信性;然后,最大化事实的似然性以获得实体和关系的嵌入(Chaudhri等人,2022;Sun et al, 2022)。知识图谱的表示为下游任务带来了诸多好处。基于三元组事实的知识图谱嵌入方法主要有3类:基于张量因子化的方法、基于翻译的方法和基于神经网络的方法(Rossi et al, 2021)。 5.1.1 基于张量因子分解的方法
基于张量因子分解方法的核心思想是将知识图谱中的三元组转化为3D张量(Balazevi´c et al, 2019)。如图5所示,张量X∈Rm×m×n,其中m和n分别表示实体和关系的数量,包含n个切片,每个切片对应一种关系类型。当满足条件Xijk = 1时,知识图谱中存在三元组(ej i, rk, e),其中e和r分别表示实体和关系。否则,当Xijk = 0时,表示知识图谱中不存在这样的三元组。那么,张量由由实体和关系的向量组成的嵌入矩阵表示。 5.1.2 基于翻译的方法
基于翻译的方法利用了基于翻译不变性的评分函数。翻译不变性解释两个词的向量之间的距离,这是由它们的语义关系的向量表示的(Mikolov等人,2013)。Bordes et al. (Bordes et al., 2013)首先利用基于翻译不变性的评分函数进行度量
嵌入结果。他们创造性地提出了TransE模型,该模型将知识图谱中所有的实体和关系转换到一个连续的低向量空间中。具体来说,三元组中头部和尾部实体的向量由它们关系的向量连接起来。因此,在向量空间中,每个三元组的语义含义都被保留了下来。形式上,给定一个三元组(头、关系、尾),头实体、关系、尾实体的嵌入向量分别是h、r、t。在向量空间中,三元组(h, r, t)的似真度由基于平移不变性的评分函数计算,以确保它遵循几何原理:h + r≈t。 在TransE之后,相关的扩展不断被提出,如TransH (Wang et al, 2014)和TransR (Lin et al, 2015),以提高基于翻译的知识图谱表示的性能。
5.1.3 基于神经网络的方法
目前,深度学习已经成为知识图谱表示的流行工具,有相当多的研究提出使用神经网络表示知识图谱的三元组(Dai et al, 2020a)。在本节中,以SME、ConvKB和R-GCN这3个代表性的工作为例,对基于神经网络的知识图谱表示进行简要介绍。 SME (Bordes et al, 2014)设计了一个能量函数来进行语义匹配,该能量函数利用神经网络来度量知识图谱中每个三元组(h, r, t)的置信度。SME的评分函数定义如下:
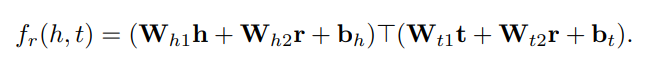
SME (bilinear)的评分函数为:
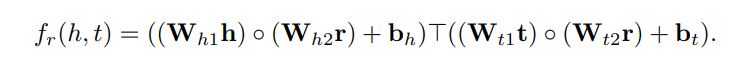
5.1.4 现有方法的局限性
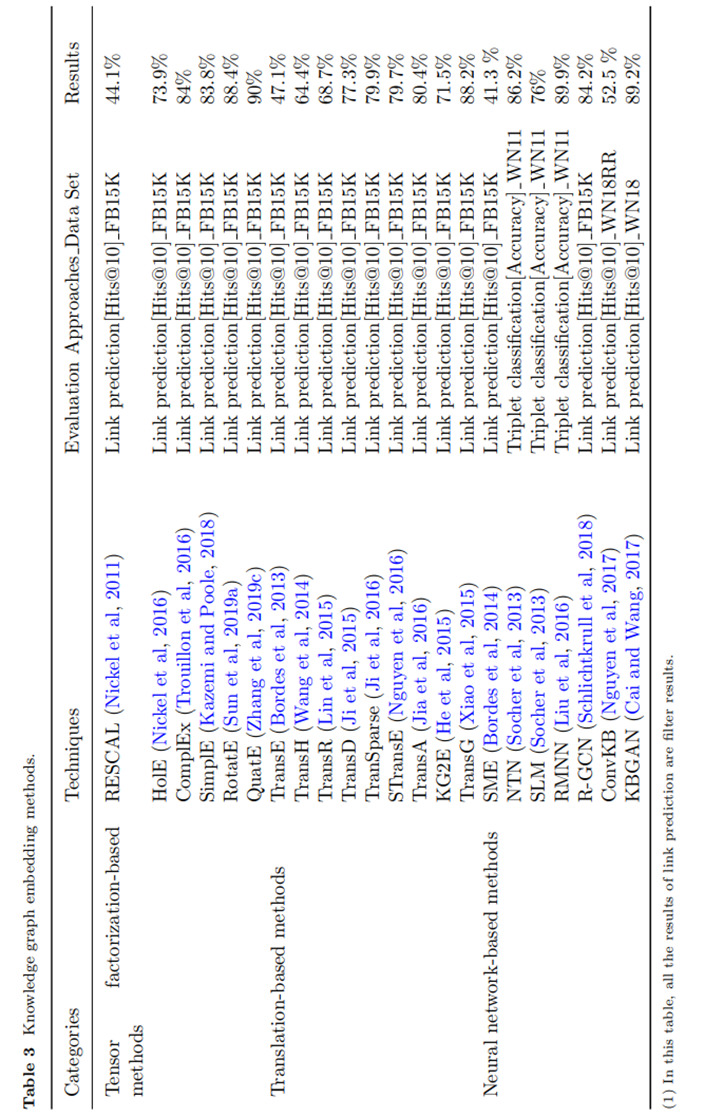
现有的知识图谱嵌入方法仍然存在严重的局限性。许多已有的方法只考虑知识图谱的表面事实(三元组)。然而,忽略了实体类型和关系路径等附加信息,这些信息可以进一步提高嵌入精度。大多数不考虑附加信息的传统方法的性能并不令人满意。表3列出了不考虑附加信息的嵌入方法。在表3中,性能评估是基于链接预测和三元组分类任务。用于评估结果的指标是命中率为10 (Hits@10)和准确率。如表3所示,只有少数模型有令人印象深刻的结果,包括QuatE(90%)、RMNN(89.9%)和KBGAN(89.2%)的结果。近年来,一些研究人员开始将附加信息与知识图谱结合起来,以提高模型嵌入的效率。例如,Guo et al. (Guo et al, 2015)利用附加的实体类型信息,即每个实体的语义类别,来获得实体之间的相关性,并解决数据稀疏问题。因此,知识图谱的表示更加准确。不仅是实体类型,有些其他信息,包括关系路径(Li et al, 2021)、动态图的时间信息(Messner et al, 2022)和实体的文本描述(An et al, 2018),近年来也得到了研究人员的关注。然而,如何有效利用丰富的附加信息来提高知识图谱表示的准确性仍然是一个艰巨的挑战。 一般附加信息不能充分表示三元组的语义。例如,实体类型与三元组的语义信息无关。此外,可以纳入三元组特征的附加信息的类型现在受到了严重的限制。因此,为了提高现有知识图谱嵌入方法的性能,需要在三元组特征中融入多元信息(如关系的分层描述、实体类型与文本描述的结合)。 就我们所知,复杂关系路径仍然是一个开放的研究问题(Peng et al, 2021)。例如,内在关系,指的是两个不相连的实体之间的间接关系,没有被有效地表示出来。虽然通过知识图谱中的关系链可以挖掘实体间的内在关系,但实体间的内在关系复杂多样。因此,有效地表示这些关系并不是一件直接的事情。 5.2 知识获取
知识获取是融合不同来源的数据并生成新的知识图谱的关键步骤。知识从结构化和非结构化数据中提取。知识获取的三种主要方法是关系抽取、实体抽取和属性抽取(Fu et al, 2019)。这里,属性抽取可以看作是实体抽取的一种特例。Zhang等人(Zhang et al, 2019b)利用知识图谱嵌入和图卷积网络提取长尾关系。Shi等人(Shi et al, 2021)提出实体集扩展构建大规模知识图谱。 然而,现有的知识获取方法仍然面临准确率低的挑战,这可能导致知识图谱不完整或噪音大,阻碍下游任务的完成。因此,第一个关键问题是知识获取工具及其评估的可靠性。此外,特定于领域的知识图谱模式是面向知识的,而构建的知识图谱模式是面向数据的,以覆盖所有数据特征(Zhou等,2022)。因此,从原始数据中抽取实体和属性来生成特定领域的知识图谱是低效的。因此,如何通过生成面向特定领域的知识图谱来高效地完成知识获取任务是一个至关重要的问题。 此外,现有的知识获取方法大多针对特定语言构建知识图谱。然而,为了使知识图谱中的信息更丰富、更全面,需要进行跨语言实体抽取。因此,给予更多是至关重要的 关注跨语言实体抽取和多语言知识图谱的生成。例如,Bekoulis et al.(Bekoulis et al, 2018)提出了一种跨语言(英语和荷兰语)实体和关系抽取的联合神经模型。然而,由于非英语训练数据集有限,语言翻译系统并不总是准确的,并且跨语言实体抽取模型必须针对每一种新语言重新训练,多语言知识图谱构建仍然是一项艰巨的任务。 多模态知识图谱构建被认为是知识获取的另一个具有挑战性的问题。现有的知识图谱多采用纯符号表示,导致机器理解现实世界的能力较差(Zhu et al, 2022b)。因此,许多研究人员关注于包含文本、图像等多种实体的多模态知识图谱。多模态知识图谱的构建需要探索具有不同模态的实体,使得知识获取任务复杂且效率低下。
5.3 知识图谱补全
知识图谱通常是不完整的,即缺少几个相关的三元组和实体(Zhang et al, 2020b)。例如,在Freebase,最著名的知识图谱之一,超过一半的人实体没有关于他们的出生地和父母的信息。一般情况下,可用于保证知识图谱质量的半自动化和人工利用机制是知识图谱完成度评价必不可少的工具。具体而言,人类监督目前被认为是知识图谱完成中的金标准评价(Ballandies和Pournaras, 2021年)。
知识图谱补全旨在利用链接预测技术,通过添加新的三元组来扩展现有的知识图谱(Wang et al, 2020b;Akrami et al, 2020)和实体预测(Ji et al, 2021)。这些方法通常在知识图谱上训练机器学习模型,以评估新的候选三元组的合理性。然后,他们将具有高可信度的候选三元组添加到图谱中。例如,对于一个不完整的三元组(Tom, friendOf, ?),可以评估尾巴的范围,并返回更可信的,以丰富知识图谱。这些模型成功地利用了许多不同领域的知识图谱,包括数字图书馆(Yao等,2017年)、生物医学(Harnoune等,2021年)、社交媒体(Abu-Salih, 2021年)和科学研究(Nayyeri等,2021年)。一些新的方法能够处理每个三元组与置信值相关联的模糊知识图谱(Chen et al, 2019)。
然而,现有的知识图谱补全方法仅关注于从封闭世界的数据源中抽取三元组。这意味着生成的三元组是新的,但三元组中的实体或关系需要已经存在于知识图谱中。例如,对于不完整的三元组(Tom, friendOf, ?),只有当实体Jerry已经在知识图谱中,才有可能预测三元组(Tom, friendOf, Jerry)。由于这一限制, 这些方法无法向知识图谱中添加新的实体和关系。为了解决这个问题,我们开始看到知识图谱补全的开放世界技术的出现,这些技术从现有的知识库之外提取潜在的对象。例如,ConMask模型(Shi和Weninger, 2018)被提出用于预测知识图谱中未见实体。然而,开放世界知识图谱的补全方法仍存在准确率不高的问题。主要原因是数据源通常比较复杂和嘈杂。此外,预测的新实体与现有实体的相似性可能会误导结果。换句话说,两个相似的实体被视为有联系的实体,而它们可能没有直接关系。
知识图谱补全方法假设知识图谱是静态的,无法捕捉知识图谱的动态演化。为了获得随时间变化的准确事实,考虑反映知识有效性的时态信息的时态知识图谱补全技术应运而生。与静态知识图谱补全方法相比,时序知识图谱补全方法将时间戳融入到学习过程中。因此,它们探索了时间敏感的事实,并显著提高了链路预测精度。时序知识图谱补全方法在取得优异性能的同时,也面临着严峻的挑战。由于这些模型认为时间信息的效率较低(Shao et al, 2022),时序知识图谱补全的关键挑战是如何有效地将事实的时间戳纳入学习模型,并适当地捕获事实的时序动态。
5.4 知识融合
知识融合旨在将来自不同数据源的知识进行组合和整合。它往往是知识图谱生成的必要步骤(Nguyen et al, 2020;Smirnov和Levashova, 2019)。知识融合的主要方法是实体对齐或本体对齐(Ren et al, 2021),旨在从多个知识图谱中匹配同一实体(Zhao et al, 2020)。由于数据的复杂性、多样性和大数据量,实现高效、准确的知识图谱融合是一项具有挑战性的任务。
虽然在这个方向已经做了大量的工作,但仍然有几个有趣的研究方向值得在未来进行研究。这通常用于支持跨语言推荐系统(Javed et al, 2021)。例如,Xu et al. (Xu et al., 2019)采用图匹配神经网络实现跨语言实体对齐。然而,由于来自不同语言的匹配实体的准确率相对较低,跨语言知识融合的结果仍然不尽人意。因此,探索跨语言知识融合仍然是一项艰巨的挑战。
另一个主要挑战是实体消歧(Nguyen et al, 2020)。作为自然语言的一词多义问题,同一个实体在不同的知识图谱中可能有不同的表达方式。因此,在进行实体对齐之前,需要对实体进行消歧。现有的实体消歧方法主要集中在基于从包含丰富语境信息的文本中提取知识来判别和匹配歧义实体(Zhu and Iglesias, 2018)。然而,当文本较短且上下文信息有限时,这些方法无法精确衡量实体的语义相似度。只有少数工作专注于解决这个问题。例如,Zhu和Iglesias (Zhu and Iglesias, 2018)提出了用于实体消歧的SCSNED。SCSNED同时基于知识图谱中实体的含信息量词和短文本中的上下文信息来度量语义相似度。虽然SCSNED在一定程度上缓解了上下文信息有限的问题,但还需要更多的努力来提高实体消歧的性能。
此外,许多知识融合方法只注重匹配具有相同模态的实体,忽略了知识以不同形式呈现的多模态场景。具体而言,仅考虑单模态知识图谱场景的实体对齐,由于不能充分反映现实世界中实体之间的关系,性能不显著(Cheng等,2022a)。最近,为了解决这一问题,一些研究提出了多模态知识融合,将具有不同模态的实体进行匹配,生成多模态知识图谱。例如,HMEA (Guo et al, 2021)通过将多模态表示映射到双曲空间,将实体与多种形式对齐。尽管许多研究人员已经在多模态知识融合方面进行了研究,但这仍然是一项关键任务。多模态知识融合主要是通过整合它们的多模态特征来寻找等价实体(Cheng et al, 2022a)。然而,如何有效地合并具有多模态的特征仍然是当前方法面临的棘手问题。
5.5 知识推理
知识推理的目标是推理新的知识,如两个实体之间的隐式关系(Liu等人,2021;Wang et al, 2019c),基于现有数据。对于给定的知识图谱,其中存在两个不相连的实体h和t,表示为h, t∈G,这里G表示知识图谱,知识推理可以发现这些实体之间的潜在关系r,形成新的三元组(h, r, t)。知识推理方法主要分为基于逻辑规则的方法(De Meester et al, 2021)、基于分布式表示的方法(Chen et al, 2020b)和基于神经网络的方法(Xiong et al, 2017)。基于逻辑规则的知识推理旨在根据随机游走和逻辑规则发现知识,而基于分布式表示的知识推理则将实体和关系嵌入到向量空间中以获得分布式表示(Chen et al, 2020b)。 基于网络的知识推理方法在给定图中的知识体的情况下,利用神经网络来推断新的三元组(Xian et al, 2019)。 在知识推理中有两个任务:单跳预测和多跳推理(Ren et al, 2022)。单跳预测为给定的两个元素预测三元组中的一个元素,而多跳推理预测多跳逻辑查询中的一个或多个元素。换句话说,在多跳推理场景中,找到一个典型问题的答案并形成新的三元组,需要对多个边和节点进行预测和填补。与单跳预测相比,多跳推理实现了更精确的三元组形成。因此,多跳推理受到越来越多的关注,成为近年来知识图谱发展的迫切需求。尽管已有许多相关工作,但知识图谱上的多跳推理仍处于起步阶段。值得注意的是,海量知识图谱上的多跳推理是具有挑战性的任务之一(Zhu et al, 2022a)。例如,最近的研究主要集中在知识图谱上的多跳推理,而这类图谱只有63K个实体和592K个关系。对于数百万个以上实体的海量知识图谱,现有模型无法有效学习训练集。此外,多跳推理需要遍历知识图谱中的多个关系和中间实体,这可能导致指数计算代价(Zhang et al, 2021)。因此,探索多跳知识推理仍然是一项艰巨的任务。 此外,对推断出的新知识的验证也是一个关键问题。知识推理丰富了现有的知识图谱,给下游任务带来了好处(Wan等,2021)。然而,推断出的新知识有时是不确定的,新三元组的准确性需要验证。此外,还需要检测新知识与现有知识之间的冲突。为了解决这些问题,一些研究提出了多源知识推理(Zhao et al, 2020),可以检测错误知识和冲突知识。总的来说,应该更多地关注多源知识推理和错误知识约简。
6. 结论
知识图谱在为各个领域创建许多智能服务和应用方面发挥了重要作用。本文从知识图谱发展的机遇与挑战两个方面对其进行综述。首先介绍了知识图谱的定义和现有的研究方向,对知识图谱进行了介绍性分析;之后,我们讨论了利用知识图谱的人工智能系统。然后,给出了知识图谱在多个领域中的代表性应用;进一步,分析了现有知识图谱技术存在的局限性和面临的严峻技术挑战。我们期待该调研为未来涉及知识图谱的研发活动激发新的想法和有洞察力的视角。