
人工智能系统落地应用不仅需要考虑准确性,还需考虑其他维度,如鲁棒性、可解释性等,即要构建负责任的人工智能。CMU的Nicholas Gisolfi的博士论文《Model-Centric Verification of Artificial Intelligence》探究训练模型的正式验证是否可以回答关于真实世界系统的广泛现实问题。提出方法适用于那些在特定环境中最终负责确保人工智能安全运行的人。值得关注!

摘要:
这项工作展示了如何在人工智能(AI)系统的背景下使用可证明的保证来补充概率估计。统计技术测量模型的预期性能,但低错误率并不能说明错误表现的方式。对模型是否符合设计规范的正式验证可以生成证书,该证书明确地详细说明了违规发生时的操作条件。这些证书使人工智能系统的开发人员和用户能够按照合同条款对其训练的模型进行推理,消除了由于不可预见的故障导致模型失效而造成本可以很容易预防的伤害的机会。为了说明这个概念,我们展示了名为Tree Ensemble itor (TEA)的验证流程。TEA利用我们的新布尔可满足性(SAT)形式,为分类任务的投票树集成模型提供支持。与相关的树集合验证技术相比,我们的形式化产生了显著性的速度增益。TEA的效率允许我们在比文献中报道的更大规模的模型上验证更难的规范。
在安全背景下,我们展示了如何在验证数据点上训练模型的局部对抗鲁棒性(LAR)可以纳入模型选择过程。我们探索了预测结果和模型鲁棒性之间的关系,允许我们给出最能满足工程需求的LAR定义,即只有当模型做出正确的预测时,它才应该是鲁棒的。在算法公平的背景下,我们展示了如何测试全局个体公平(GIF),包括数据支持内和数据支持外。当模型违反GIF规范时,我们列举了该公式的所有反例,以便揭示模型在训练过程中所吸收的不公平结构。在临床环境中,我们展示了如何简单地通过调整树集合的预测阈值来满足安全优先工程约束(SPEC)。这促进了预测阈值的帕累托最优选择,这样就不能在不损害系统安全性的情况下进一步减少误报。
本论文的目标是探究训练模型的正式验证是否可以回答关于真实世界系统的广泛的现有问题。我们的方法适用于那些在特定环境中最终负责确保人工智能安全运行的人。通过对训练过的树集合进行验证(V&V),我们希望促进AI系统在现实世界的落地应用。
https://www.ri.cmu.edu/publications/model-centric-verification-of-artificial-intelligence/
动机
人工智能领域前景广阔,我们的共同目标是确保尽可能多的人释放其潜力,解决许多不同应用领域的新问题。我们发现有一个共同的障碍限制了AI系统的采用速度,这通常归结为信任问题。许多最终负责AI系统输出的人对他们的模型的信任程度不足以保证将AI部署到某个新领域。
考虑到艾萨克·阿西莫夫的机器人第一定律:机器人不能伤害人类,也不能坐视人类受到伤害。这是AI系统关键设计规范的一个很好的例子。一个人工智能系统并不局限于物理机器人,它也可以是一个黑盒子,机器学习(ML)模型。伤害不需要仅仅描述身体上的伤害,它也可能涉及由人工智能系统提出的违反人类直觉的建议所导致的混乱。这就是人们开始信任人工智能系统的地方。我们知道,人工智能有时会做一些与人类对模型应该如何运作的直觉相悖的事情。令人担心的是,在这些情况下,人工智能系统可能会造成人类决策者永远不会造成的容易预防的伤害。如果我们不确定AI系统是否遵守了关键的设计规范(如阿西莫夫第一定律),我们还能相信它吗?
目前将人工智能系统视为用以数据为中心的统计方法来审问的黑匣子解决该问题。模型行为的概率估计需要一定的置信度,该置信度取决于应用领域中可接受的不确定性边际。如果我们考虑一个电影推荐系统,可接受的不确定性是很高的,因为一部糟糕的电影最多会浪费一天中的几个小时。如果我们考虑的是自动驾驶汽车环境或任何其他关键应用领域,可接受的不确定性幅度要低得多。即使统计方法反复检验模型以提高其估计的置信界限,也不可能提供真正全面的评估并实现绝对的确定性。我们所能说的是,在许多测试过程中,我们从未观察到特定的故障,这使我们有理由相信,一旦部署模型,同样的故障非常不可能发生。对于更长时间的任务,比如为深空栖息地开发半自主生命支持系统,即使是很小的模型失败的机会也会有大量的机会出现。
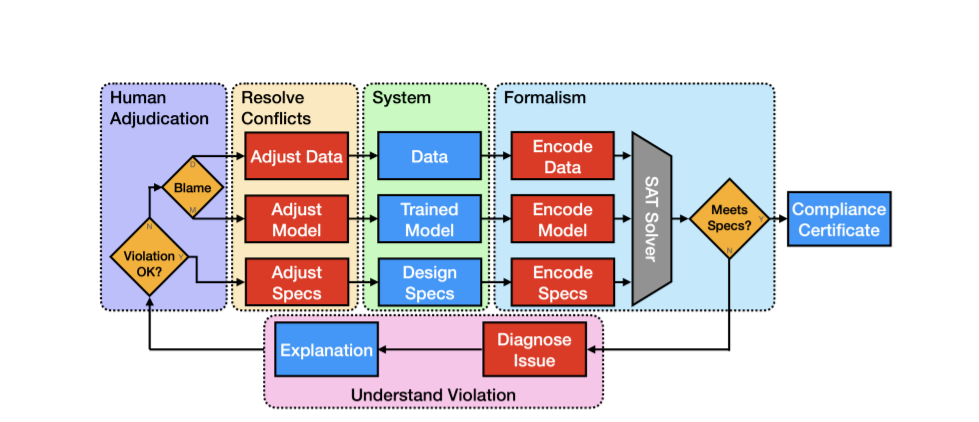
Tree Ensemble itor (TEA),我们的认证流程
统计技术本身并不能很好地适应关键系统所需要的信任水平。这是因为低错误率只告诉我们关键错误发生的频率很低;我们想知道这些关键的错误将如何表现。本文的研究范围集中在容易造成可预防伤害的关键错误上。我们将在整个工作中探索的关键错误类型包括健壮性、公平性和安全性的概念。为了增强鲁棒性(见第3章),我们测试了一个模型在特定输入的属性值存在难以察觉的扰动时输出的一致性。为了公平起见(见第4章),我们测试了一个模型,以确定它是否总是以相似的方式对待相似的个体。为了安全起见(见第5章),我们测试了一个模型,以确保没有从输入到输出的可理解映射代表人类永远不会做出的违反直觉的、有害的建议。值得注意的是,这个列表中缺少分类错误,这在很多情况下并不一定是一个关键的错误。人类的决策在硬边界情况下会产生错误,所以AI应该被允许犯同样类型的错误。相反,我们关注的是人工智能表现出人类没有表现出的不受欢迎的决策逻辑的情况,比如在两个难以区分的输入之间设置决策边界,对两个相似的输入产生截然不同的输出,以及在人类最容易判断的情况下犯错误。
AI系统实际上并不是黑盒,我们也不需要这么对待它们。相反,它们是由一组离散的组件定义的,这些组件相互作用,以产生看似智能的模型行为。正是这些组件的行为决定了模型实现其预测的方式。解决询问训练模型内部组件的挑战的一种方法涉及逻辑和统计技术的结合。统计机器学习擅长于从数据中学习有用的策略,而形式逻辑和自动推理则擅长于确定是否可以从一组前提条件中得出结论。
我们的工作弥合了人工智能领域历史上两大成功理念之间的鸿沟。在早期,人工智能系统由符号逻辑、规则和专家知识组成;专家系统很容易用形式逻辑进行测试。现代人工智能系统由组件和元结构组成,这些组件和元结构承担优化过程,以使模型适合数据。目前流行的统计学ML易于用统计方法进行检验。人工智能领域焦点的转变,在一定程度上是由于对人类大脑内部工作方式的不同看法。符号主义认为人类的智力是通过逻辑推理获得的,这一观点逐渐被连接主义的观点所取代,连接主义认为,在人类大脑的相互连接的结构中,招募成群的神经元会产生智能行为。我们今天构建的人工智能系统反映了这种思维方式的转变。这两个框架各有优缺点;例如,统计模型可以更好地概括尚未见过的数据,但符号模型可能更易于解释。我们将逻辑和统计方法的优势结合起来,认为这是构建成功的、值得信赖的人工智能系统的最佳方法。如果用纯逻辑检验统计技术产生的模型,那么我们就可以提供证据,证明模型确实符合设计规范、工程需求,甚至专家知识。这使得对于将在现实世界中部署的模型的契约推理和概率推理都成为可能。
虽然我们的方法是否会增加人类对人工智能系统的信任感的问题超出了本文的范围,但我们确实声称,我们的工作增加了人工智能系统的可信度。一个正式的证明和伴随的证书是一种解释。它们描述了模型结构满足或违反关键设计规范的操作条件。对模型结构的推理提供了当前实践无法获得的洞察力。这些关于模型的优势和劣势的附加信息使所有涉众都更加了解情况。我们表明,模型符合关键设计规范的正式验证补充了通常用于在构建AI系统时告知决策的概率估计。证书使AI系统的开发者和用户能够根据合同条款对他们的模型进行推理,从而实现AI系统的规格驱动设计。我们将展示如何结合这些信息来回答关于现实世界的AI系统的现有问题。


