如何将因果干预用于提升模型公平性?

©PaperWeekly 原创 · 作者 | 张一帆
学校 | 中科院自动化所博士生
研究方向 | 计算机视觉

Algorithmic fairness
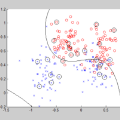
Algorithmic fairness 作为一个更大众也是被研究更多的任务,发现和纠正自动化决策系统潜在的歧视性行为。给定一个数据集,该数据集包含来多个群体(例如,根据年龄、性别或种族定义)的个人,以及经过训练以进行决策的二元分类器(例如,这些人是否被批准使用信用卡)。
一个直观的例子是,如果我们的训练数据存在一些年龄的歧视。日常生活中老年人可能更小概率被批准使用,所以我们的数据隐含着这种先验,因此最后分类器可能也会被个体的年龄所误导。但是真实情况是,我们并不希望分类器被这些保护属性,而是希望它尽可能公平(fairness),即只根据财政状况本身进行分类。

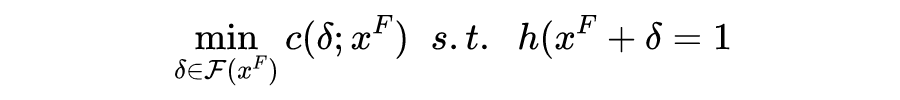

论文标题:
论文链接:
这篇文章提出了 causal recourse,主要的改进在于:
1. 提出将 recourse 的问题在 SCM(结构化因果模型)的框架下进行处理;
2. 在传统的 recourse 中,我们关注的是距离 最近的那个正例样本,而在 causal recourse 中,我们关注最小干预。
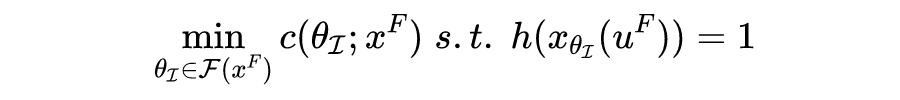

Equalizing Recourse across Groups

Equalizing Recourse across Groups
https://arxiv.org/abs/1909.03166

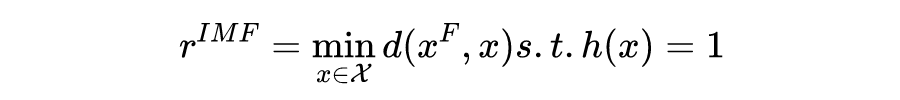



论文标题:
论文链接:
Equalizing recourse 这样的 formulation 忽略了 recourse 从根本上是一个因果问题,因为在现实世界中个人为了改变自己的处境而采取的行动可能会产生下游效应。IMF 由于没有对特征之间的因果关系进行推理,这种基于距离的方法 (i) 不能准确反映真实的(差异)recourse cost,并且 (ii) 仅限于经典的以预测为中心的方法,即改变分类器(将 group recourse cost 作为训练约束)来处理 discriminatory recourse。
本文与 IMF 最直观的差异在于,考虑了多个变量之间的相互影响即所谓的因果关系。
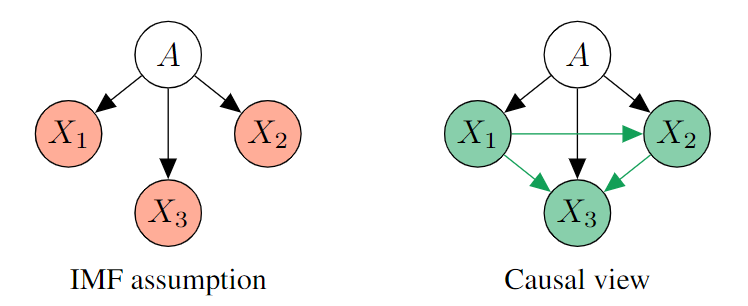
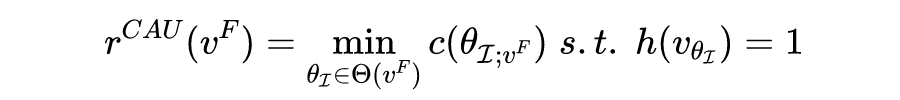
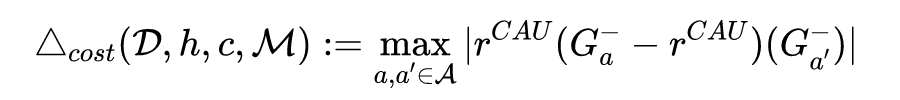
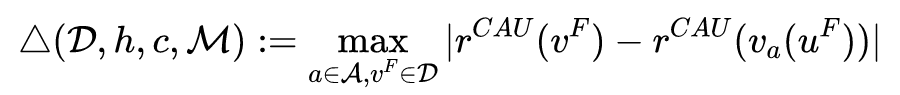
文章举出了一些例子,验证了前面定义的所有 group-level 的 fairness 都不是 individual fairness 的充分条件。
到了这里,我们已经定义完了 metric,那么如何在算法中进行优化呢?
实验部分,causality 的文章基本上都会有生成数据的实验。作者准备了两种数据集
Independently-manipulable features(IMF):特征之间相互独立。
-
Causally-dependent features(CAU):特征之间相互依赖并且依赖于 ,SCM 模型如下 ,当 是线性函数时称为 ,非线性时称为 。
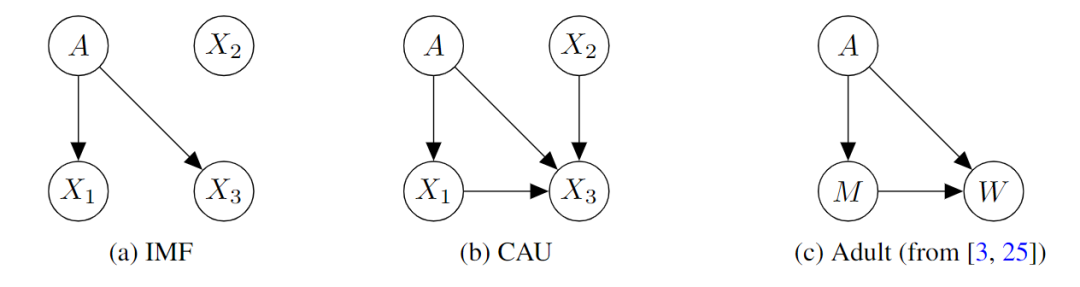
然后是不同的 baseline:
-
LR/SVM(X,A):使用所有特征进行训练; -
LR/SVM(X):只使用非保护的特征进行训练; -
FairSVM(X,A):前文的 Equalizing recourse,平衡不同保护群体到决策边界的平均距离; -
LR/SVM(X ):只使用 的非后代特征进行训练; -
LR/SVM(X , ):使用 的非后代特征与外生变量一起进行训练。
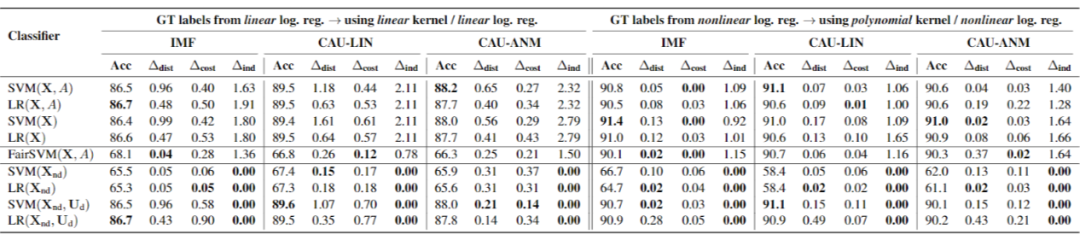
除了合成数据,作者还在 Adult 数据集上进行了实验,数据集的具体介绍可以参照原文,这是一个专门用于 Causal 的数据集,提供了各个属性的名称以及相应的因果关系。
特别鸣谢
感谢 TCCI 天桥脑科学研究院对于 PaperWeekly 的支持。TCCI 关注大脑探知、大脑功能和大脑健康。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧