

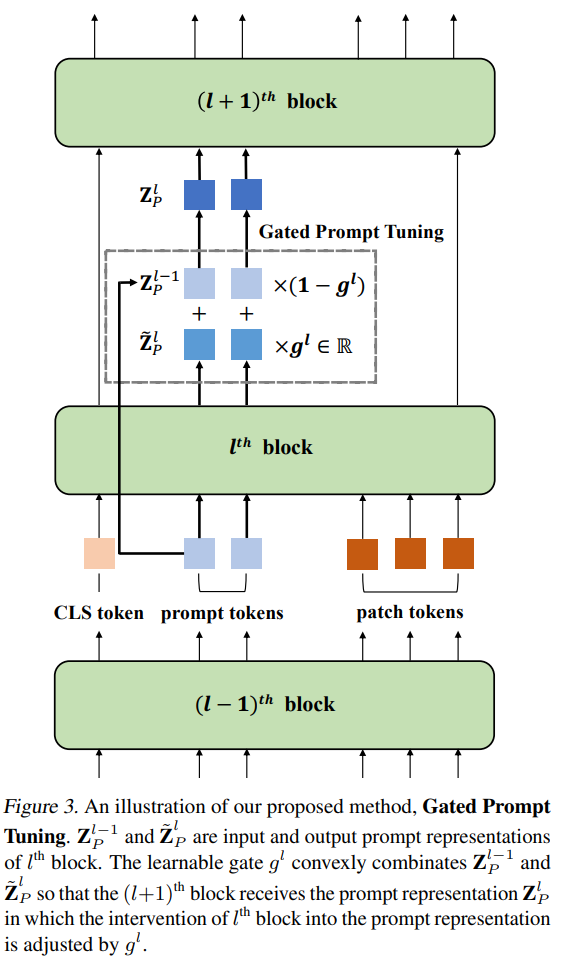
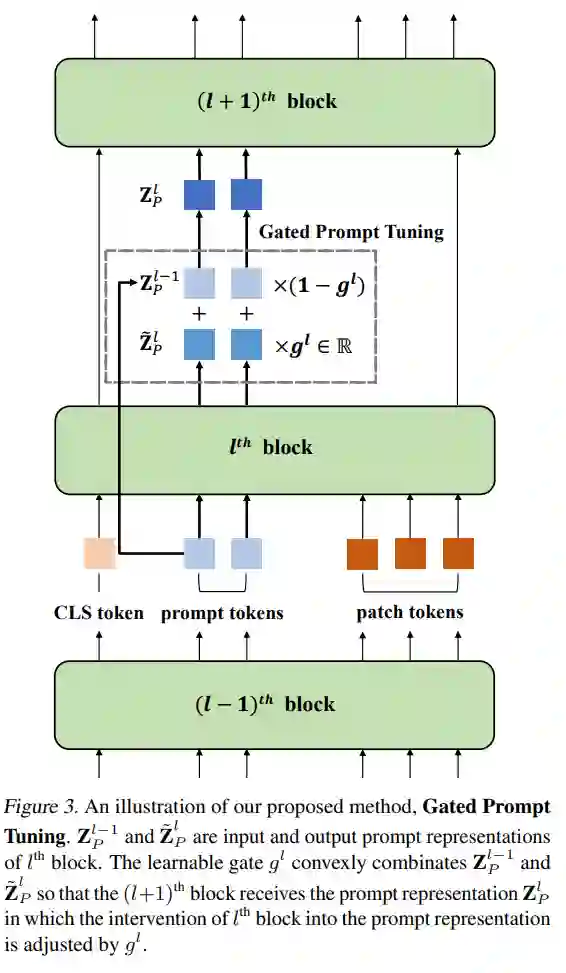
视觉提示调优(VPT)是一种有效的调整方法,用于将预训练的Vision Transformers (ViTs)适应到下游任务。它利用额外的可学习的标记,称为提示,来引导冻结的预训练的ViTs。尽管VPT已经证明了其在监督视觉变换器中的应用性,但在自我监督的视觉变换器中常常表现不佳。通过实证观察,我们推断出VPT的有效性在很大程度上取决于提示标记与之交互的ViT块。具体来说,当提示标记插入到后面的块而不是第一个块时,VPT在图像分类任务中的性能有所提高,例如MAE和MoCo v3。这些观察表明,存在一个插入提示标记的块的最优位置。不幸的是,确定每个自我监督ViT中提示的最佳块以适应多样的未来场景是一个成本高昂的过程。为了缓解这个问题,我们提出了一种简单而有效的方法,该方法学习每个ViT块的一个门,以调整其对提示标记的干预。通过我们的方法,提示标记被选择性地受到需要进行任务适应的块的影响。我们的方法在FGVC和VTAB图像分类以及ADE20K语义分割中优于VPT变体。代码可在
https://github.com/ryongithub/GatedPromptTuning 获取。
成为VIP会员查看完整内容

相关内容

Arxiv
12+阅读 · 2021年5月30日
相关主题

相关VIP内容
相关资讯