【NeurIPS2022】不用微调的加速大规模视觉Transformer的密集预测

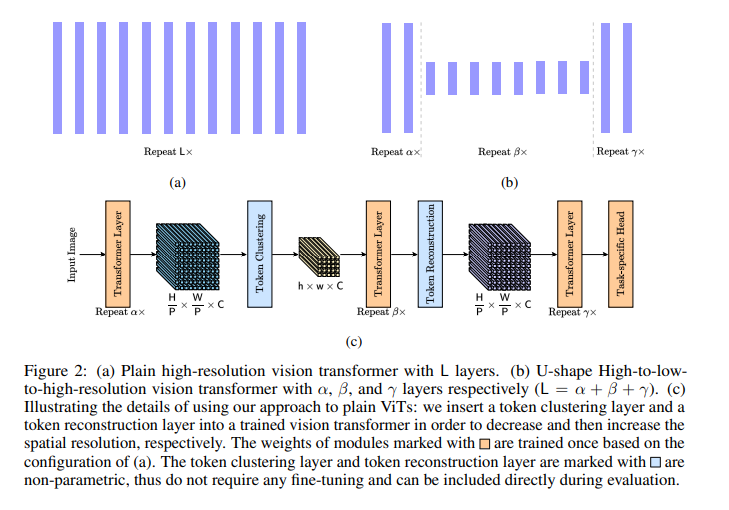
视觉transformer最近在各种视觉任务中取得了有竞争力的结果,但在处理大量token时仍然存在很大的计算成本。许多先进的方法已经开发出来,以减少大规模视觉transformer中的token总数,特别是对于图像分类任务。通常,他们根据与 [class]标记的相关性选择一组基本标记,然后微调视觉transformer的权重。这种微调对于密集预测来说不太实用,因为与图像分类相比,计算量和GPU内存成本要高得多。在本文中,我们关注一个更具挑战性的问题,即在不进行任何额外的再训练或微调的情况下,加速大规模视觉transformer进行密集预测。针对高密度预测需要高分辨率表示的事实,我们提出了两个非参数运算符,一个是减少token数量的token聚类层,一个是增加token数量的token重构层。为了实现这一目标,我们执行了以下步骤:(i)我们使用token聚类层将相邻的token聚在一起,从而产生保持空间结构的低分辨率表示;(ii)仅将以下transformer层应用于这些低分辨率表示或集群token;(iii)我们使用token重构层从精炼的低分辨率表示重新创建高分辨率表示。该方法在目标检测、语义分割、泛视分割、实例分割和深度估计等五种密集预测任务中取得了良好的效果。因此,该方法在不微调官方权重的情况下,在ADE20K上保持99.5%的性能的同时,加速了40%↑FPS并节省了30%↓GFLOPs的“Segmenter+ViT-L/16”。
https://www.zhuanzhi.ai/paper/d7612e394722b9aa764f35a645789efe
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“DPWF” 就可以获取《【NeurIPS2022】不用微调的加速大规模视觉Transformer的密集预测》专知下载链接





