

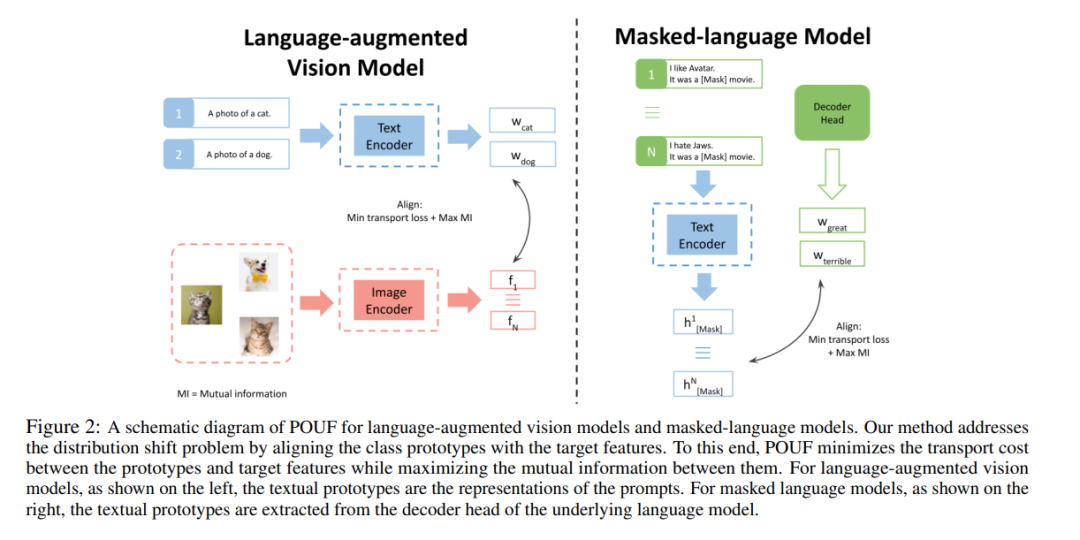
通过提示,大规模预训练模型变得更具表达力和威力,在近年来受到了显著的关注。尽管这些大型模型具有零射击能力,但总的来说,仍需要标签数据来使它们适应下游任务。为了克服这个关键的限制,我们提出了一个无监督的微调框架,直接在未标记的目标数据上微调模型或提示。我们演示了如何通过对齐从提示和目标数据中提取的离散分布,将我们的方法应用于语言增强视觉和掩蔽语言模型。为了验证我们的方法的适用性,我们在图像分类、情感分析和自然语言推理任务上进行了大量实验。在13个与图像相关的任务和15个与语言相关的任务中,我们的方法都取得了比基线更好的一致性改善。PyTorch的代码可以在https://github.com/korawat-tanwisuth/POUF上找到。
成为VIP会员查看完整内容
相关内容

Arxiv
1+阅读 · 2023年6月30日
Arxiv
0+阅读 · 2023年6月30日
Arxiv
11+阅读 · 2019年10月30日

相关VIP内容
相关资讯
相关论文
Arxiv
1+阅读 · 2023年6月30日
Arxiv
0+阅读 · 2023年6月30日
Arxiv
11+阅读 · 2019年10月30日