MM-REACT
·



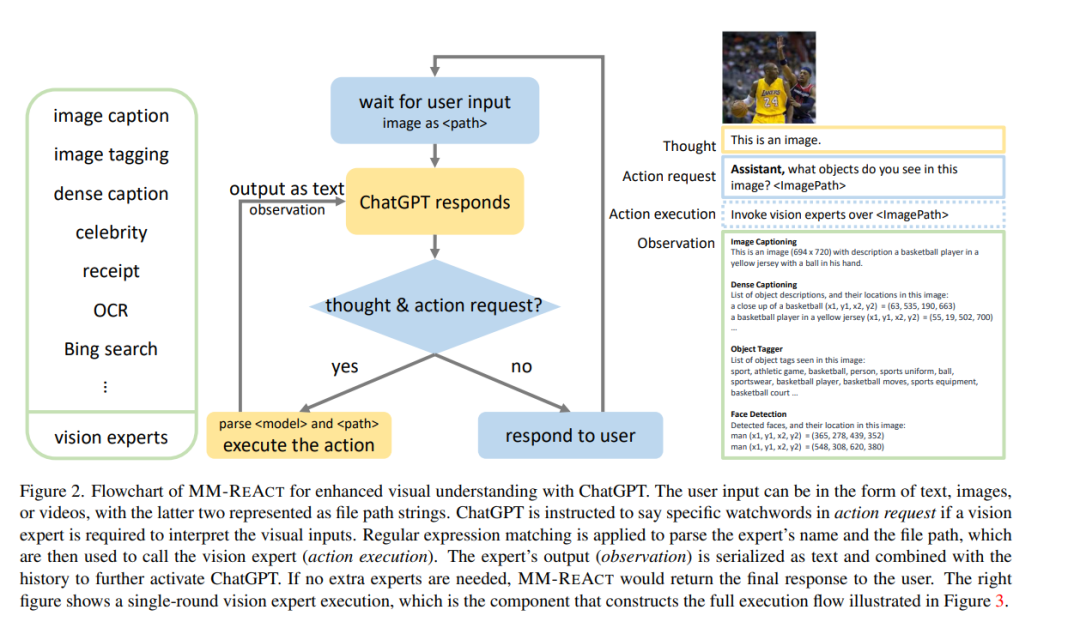
本文提出MM-REACT,一种将ChatGPT与视觉专家池集成的系统范式,以实现多模态推理和行动。本文定义并探索了一个高级视觉任务的全面列表,这些任务令人感兴趣地解决,但可能超过现有的视觉和视觉-语言模型的能力。为了实现这种先进的视觉智能,MM-REACT引入了一个文本提示设计,可以表示文本描述、文本化空间坐标和密集视觉信号(如图像和视频)的对齐文件名。MMREACT的提示符设计允许语言模型接受、关联和处理多模态信息,从而促进ChatGPT和各种视觉专家的协同结合。零样本实验证明了MM-REACT在解决兴趣的特定能力方面的有效性,以及在需要高级视觉理解的不同场景中的广泛应用。讨论和比较了MM-REACT的系统范式与一种通过联合微调为多模态场景扩展语言模型的替代方法。代码、演示、视频和可视化可在https://multimodal-react.github.io/上获得。
成为VIP会员查看完整内容
相关内容
专知会员服务
34+阅读 · 2020年5月20日
Arxiv
36+阅读 · 2023年4月19日
Arxiv
75+阅读 · 2023年3月21日
相关主题
相关VIP内容
专知会员服务
34+阅读 · 2020年5月20日
相关资讯
相关论文
Arxiv
36+阅读 · 2023年4月19日
Arxiv
75+阅读 · 2023年3月21日