
ChatGPT系列报告地址:https://www.zhuanzhi.ai/topic/tpcac5a15a1c8b5293bfc970b97839eaf7
OpenAI于2023年3月14日发布最新版本多模态大模型GPT-4及其API;国内百度于3月16日发布生成式大模型“文心一言”并开放邀请测试。为对比国内外大模型在各领域的性能差异,我们对文心一言、GPT-3.5(ChatGPT的原模型)和GPT-4的问答表现分别进行了测评。测评涉及常识和创作(文学/图片)、归纳和推理(演绎推理/情感推理/逻辑推理/主体信息抽取)、数学和代码、应用(AI助手/客服/办公协同/推荐/诗词理解)等方面。
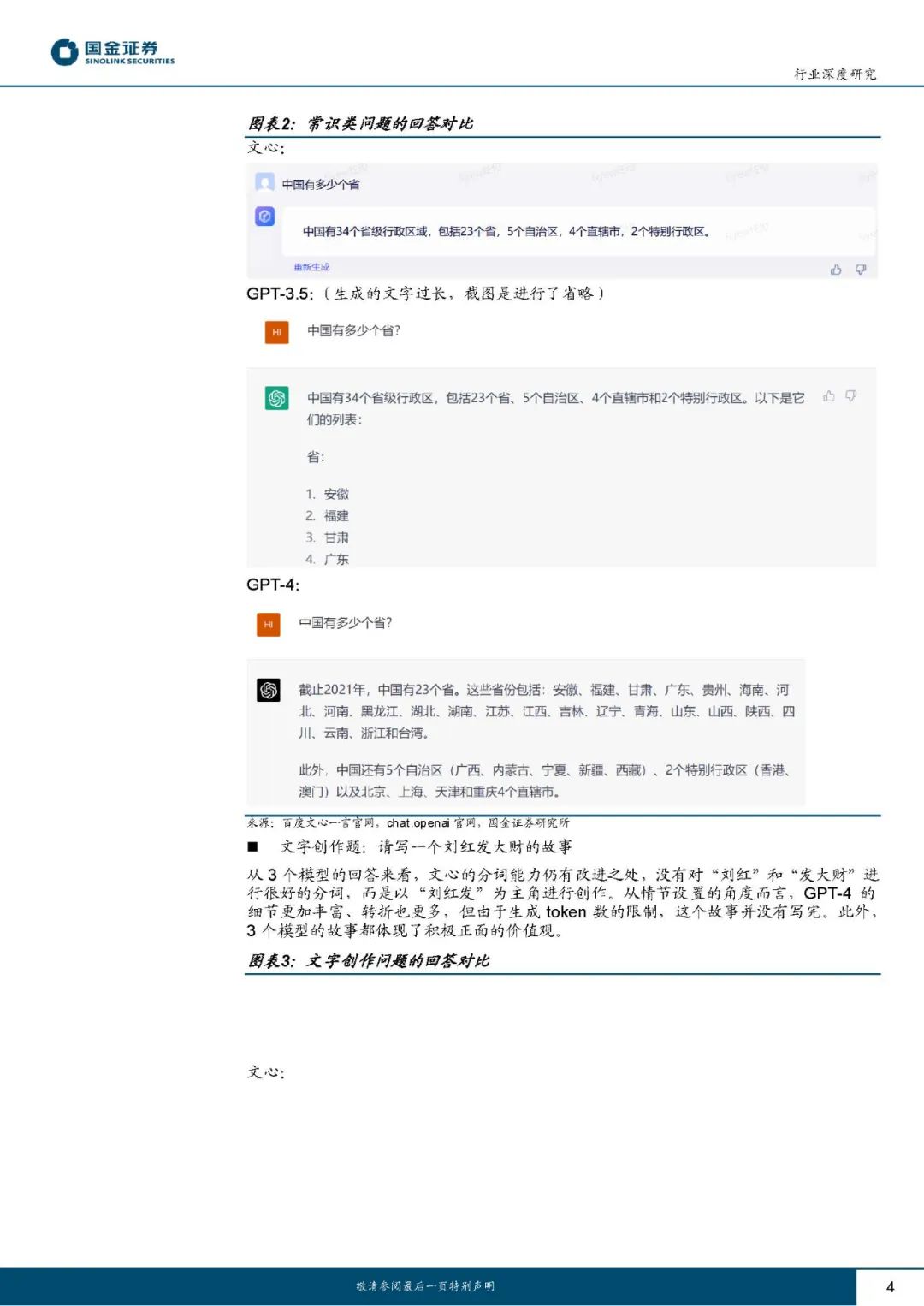
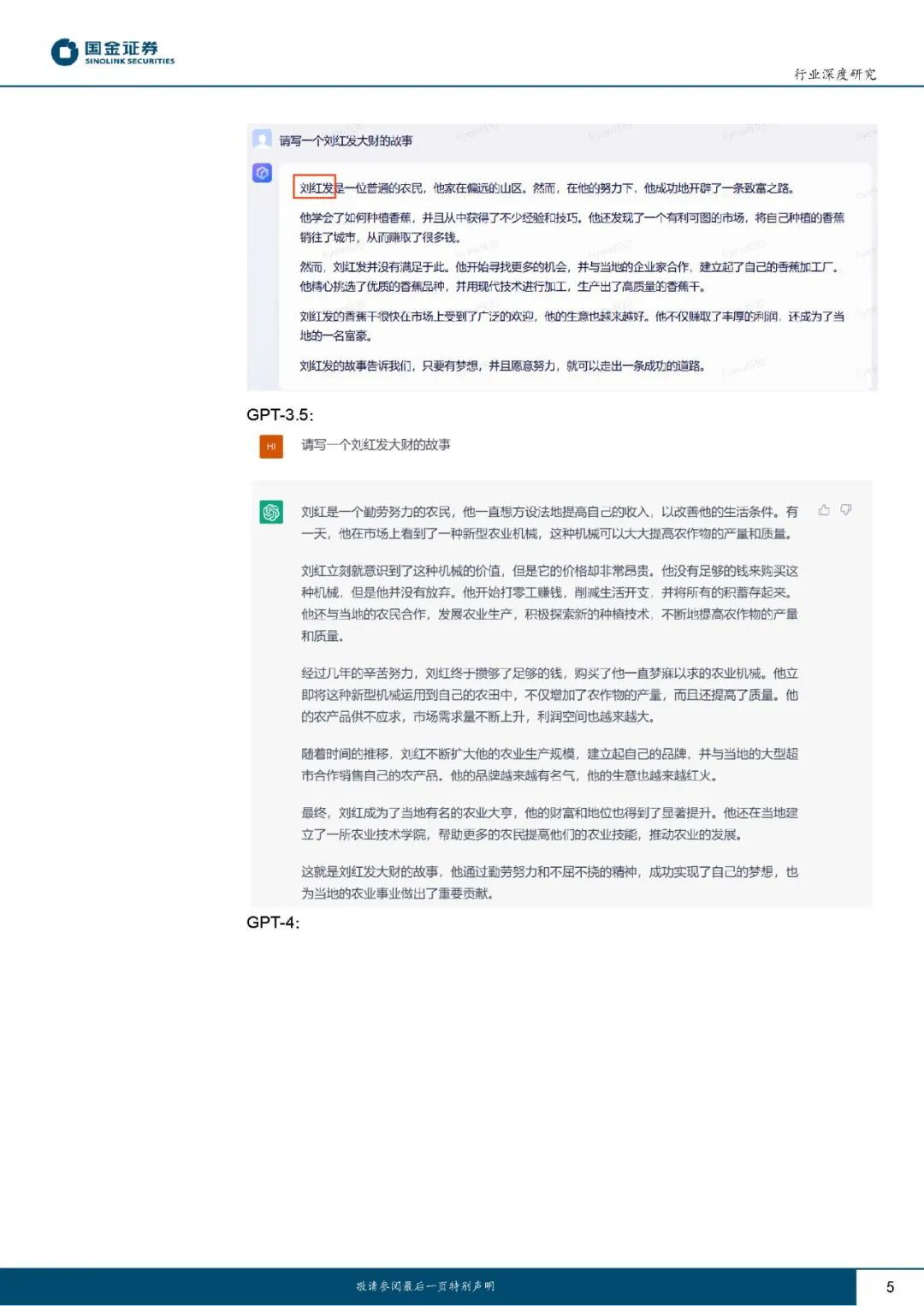
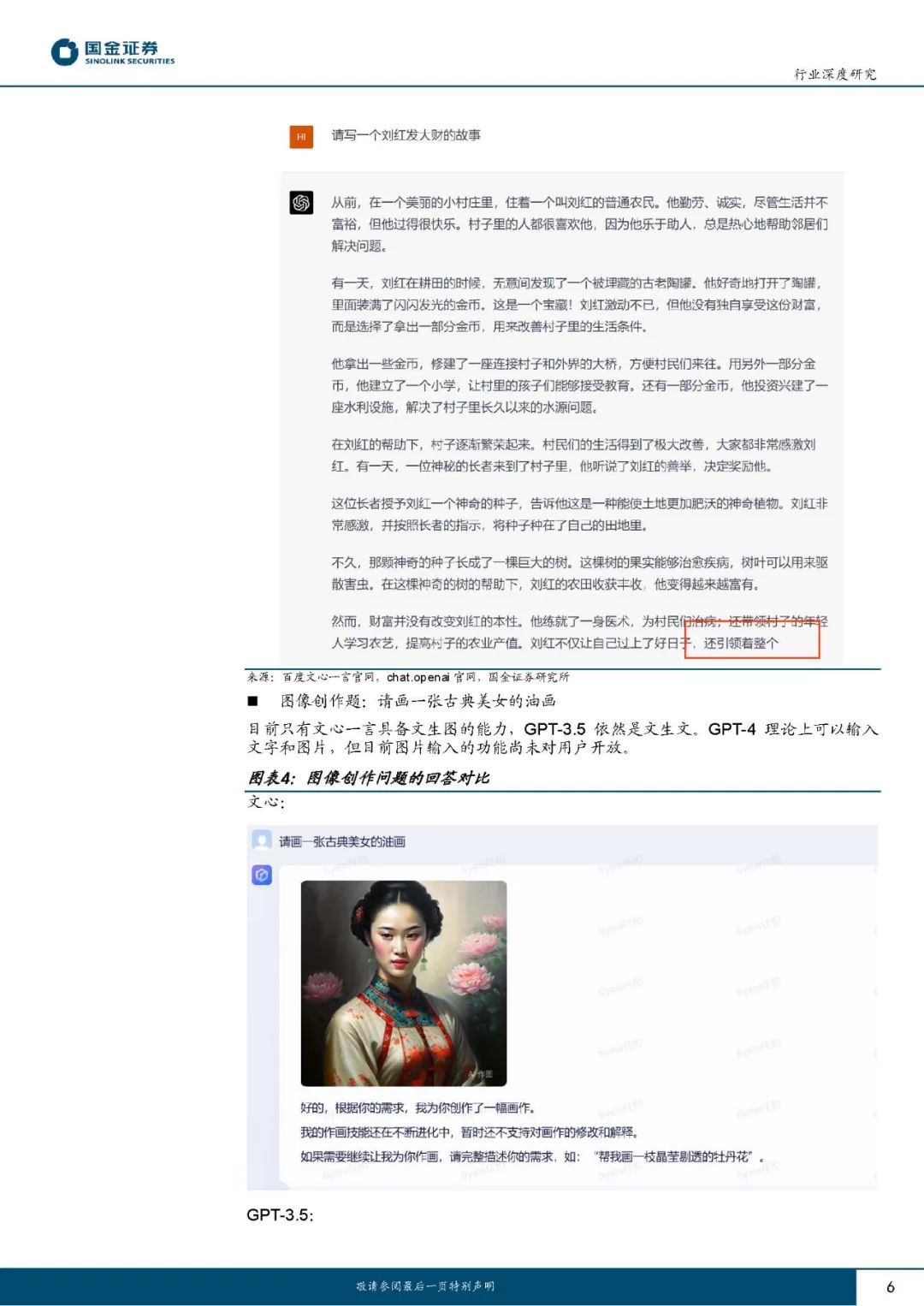
在常识和创作类问题中,三大模型均能正确回答客观常识类问题;进行文学创作结果均能体现正面价值观,但文心一言的分词功能有待提升;目前GPT-4尚未开放图像生成外部测试,文心一言的图像生成能力较为出色。 在归纳和推理类问题中,文心一言在演绎推理、逻辑推理等领域表现略逊于GPT系列模型,但在归纳总结类任务中表现较好;三大模型在情感推理类问题中仍有提升空间。 在数学和代码类问题中,GPT-3.5有更好的数学能力表现;GPT-3.5及GPT-4模型均完成了本文提出的代码生成问题,但并非最优解,文心一言代码问题识别能力有待加强。 在应用场景测试中,三大模型均能较好地完成AI生活助手、售后客服、产品推荐、办公场景文本生成等任务,但在文言文和古诗词理解运用方面表现不佳。 我们认为随百度文心及OpenAI合作生态伙伴数量快速增长、训练数据量和模型训练能力持续提升,各模型性能都有望实现进一步优化完善。


成为VIP会员查看完整内容
相关内容



相关VIP内容
相关资讯