

在这项工作中,我们系统地回顾了近期在使用语言模型进行代码处理方面的进步,涵盖了50多个模型、30多个评估任务和500个相关工作。我们将代码处理模型分为一般语言模型,由GPT家族代表,以及专门预训练在代码上的专业模型,这些模型通常具有针对性的目标。我们讨论了这些模型之间的关系和差异,并强调了代码建模从统计模型和RNNs到预训练的Transformers和LLMs的历史转变,这与NLP所经历的过程完全相同。我们还讨论了代码特定的特征,如AST、CFG和单元测试,以及它们在训练代码语言模型中的应用,并识别了这个领域的关键挑战和潜在的未来方向。我们在GitHub仓库https://github.com/codefuse-ai/Awesome-Code-LLM上保持这项综述的开放和更新。
近年来,随着预训练的Transformers(Vaswani等,2017年)如BERT(Devlin等,2019年)和GPT(Radford等,2018年)的出现,语言建模取得了显著进步。随着大型语言模型(LLMs)扩展到数千亿参数,并开始展现出人工通用智能(Brown等,2020年;Chowdhery等,2022年;OpenAI,2023年)的早期迹象,它们的应用也超越了文本处理。由Codex(Chen等,2021年)引领,LLMs在代码处理方面取得了令人印象深刻的结果,催生了诸如GitHub Copilot1和开源的多亿代码模型如StarCoder(Li等,2023年)和Code LLaMA(Rozière等,2023年)等商业产品。
然而,预训练Transformers在代码处理中的应用可以追溯到解码器仅自回归模型成为主导之前的时间(Feng等,2020年;Liu等,2020年),并且这个领域还未见到全面的综述。为了弥合自然语言处理(NLP)社区和软件工程(SE)社区在语言模型应用主题上的差距,我们在这项工作中对代码领域的语言模型进行了全景式综述,涵盖了50多个模型,30多个下游任务和500个相关工作。我们将代码语言模型的不同类别进行了分类,从在一般领域训练的庞大模型到专门为代码理解或生成训练的微型模型。我们强调这些模型之间的关系和差异,并突出了将代码特定特征,如抽象语法树或数据流,整合到语言模型中,以及从NLP适应的最新技术。 与我们的工作相关,我们知道有几项类似主题的综述,与我们同时进行的有三项工作(Hou等,2023年;Zheng等,2023年;She等,2023年)。然而,这些工作要么关注NLP方面(Zan等,2023年;Xu和Zhu,2022年),要么关注SE方面(Niu等,2023年;Hou等,2023年;Zheng等,2023年;She等,2023年),没有涵盖另一方面的模型、任务和挑战。例如,Zan等(2023年)专注于LLMs用于文本到代码生成,而很少讨论软件工程社区中的其他评估任务。相比之下,Hou等(2023年)和She等(2023年)全面回顾了ASE和ICSE等SE会议的工作,但仅引用了来自深度学习和NLP会议如ACL、EMNLP、NeurIPS和ICLR的少数几项工作。
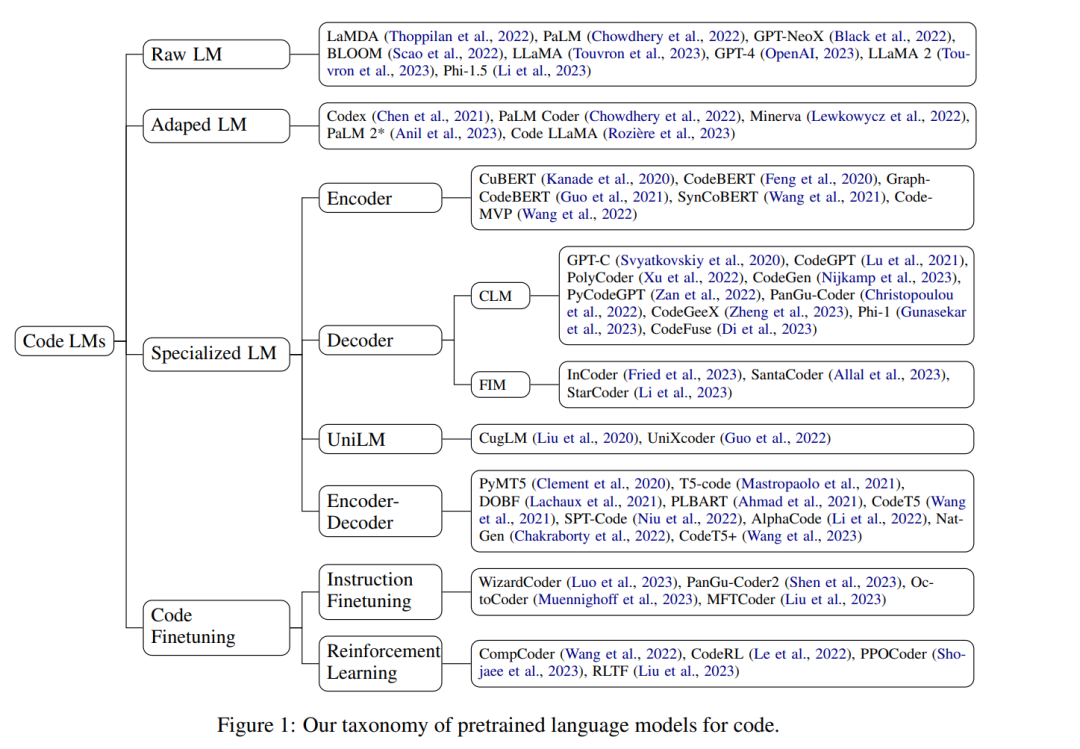
因此,在这些工作的基础上,我们努力统一这两个社区的视角,并在整个工作中强调NLP和SE之间的整合。我们主要观察到最近语言建模的高级主题已经被引入代码处理,包括指令调整(Honovich等,2023年;Xu等,2023年;Luo等,2023年),填充目标(Tay等,2023年;Li等,2023年;Rozière等,2023年),重新思考规模定律(Hoffmann等,2022年;Gunasekar等,2023年;Li等,2023年),架构改进(Shazeer,2019年;Su等,2021年;Dao等,2022年),以及自主代理(Qian等,2023年;Hong等,2023年),而SE的需求则为这些技术提供了现实世界的测试床,并推动LLMs向生产领域发展。我们认为对这些进展的系统性回顾将惠及两个社区。
本工作的其余部分按照图1所示的分类进行组织。在§2中,我们首先提供语言建模和Transformer模型的基础知识,然后在§3中,我们将语言模型评估的背景置于代码领域,强调从各种代码理解任务到更实用的文本到代码生成任务的历史转变。在§4中,我们讨论了展示了编码能力的众多LLMs,然后在§5中,我们根据它们的架构回顾了专业且通常较小的模型,特别关注最近应用的填充目标、指令调整、强化学习和工程改进。接着,在§6中,我们讨论了代码具有的独特特征,这些特征自然语言中不可用,但已被用于辅助代码处理。在§7中,我们回顾了LLMs与软件开发最近的整合,最后在§8中总结这项工作,并突出当前代码处理中的挑战。
代码语言模型评估
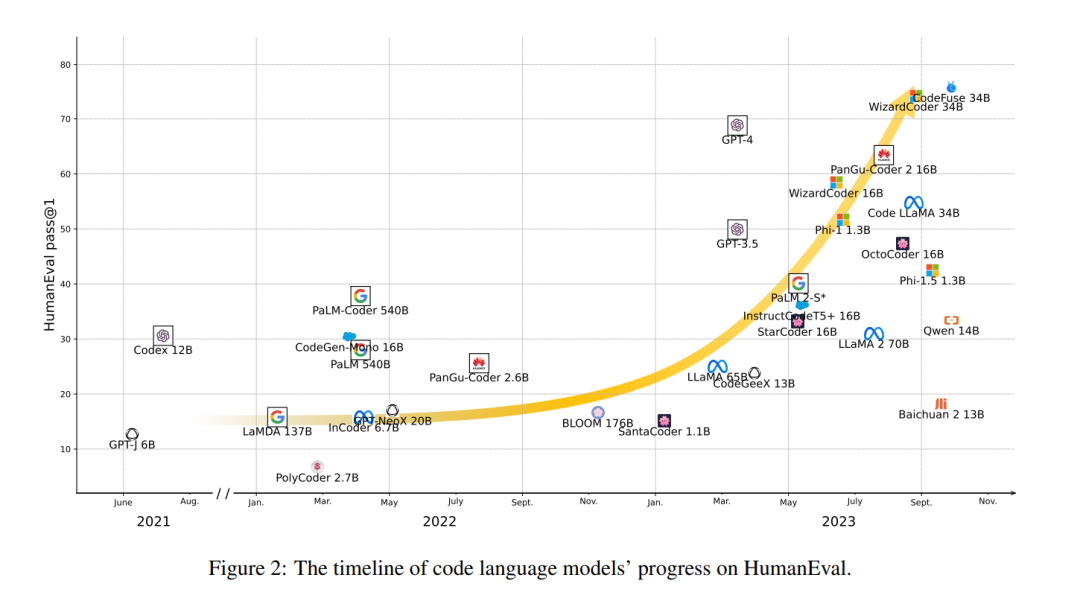
在过去的十年中,软件工程社区提出了各种评估任务来评估代码模型。CodeXGLUE(Lu等,2021年)将大多数此类任务整合到一个基准中,涵盖了代码理解任务,如克隆检测、缺陷检测,以及序列到序列生成任务,如代码修复、代码翻译、程序合成和代码摘要。然而,在Chen等(2021年)引入HumanEval和Codex之后,文本到代码的合成在NLP社区受到了关注,并自此成为评估LLMs的标准任务(图2)。因此,我们首先在§3.1中简要介绍每个传统任务及预训练语言模型在其中的应用,并在图3、4中提供每个任务相关工作的综合列表。然后,我们在§3.2中回顾评估指标,并在§3.3中更详细地研究程序合成。最后,在§3.4中,我们还讨论了最新的存储库级评估趋势。在附录A中,我们列出了每个下游任务的基准。
代码的通用语言模型
自从语言模型扩展到数百亿参数(Brown等,2020年;Chowdhery等,2022年)以来,许多模型即使没有专门为代码设计或训练,也展示了非凡的编码能力。以Codex为先驱,研究人员还发现,在代码上进行持续的预训练可以显著提高语言模型在代码方面的性能。
**代码专用语言模型 **
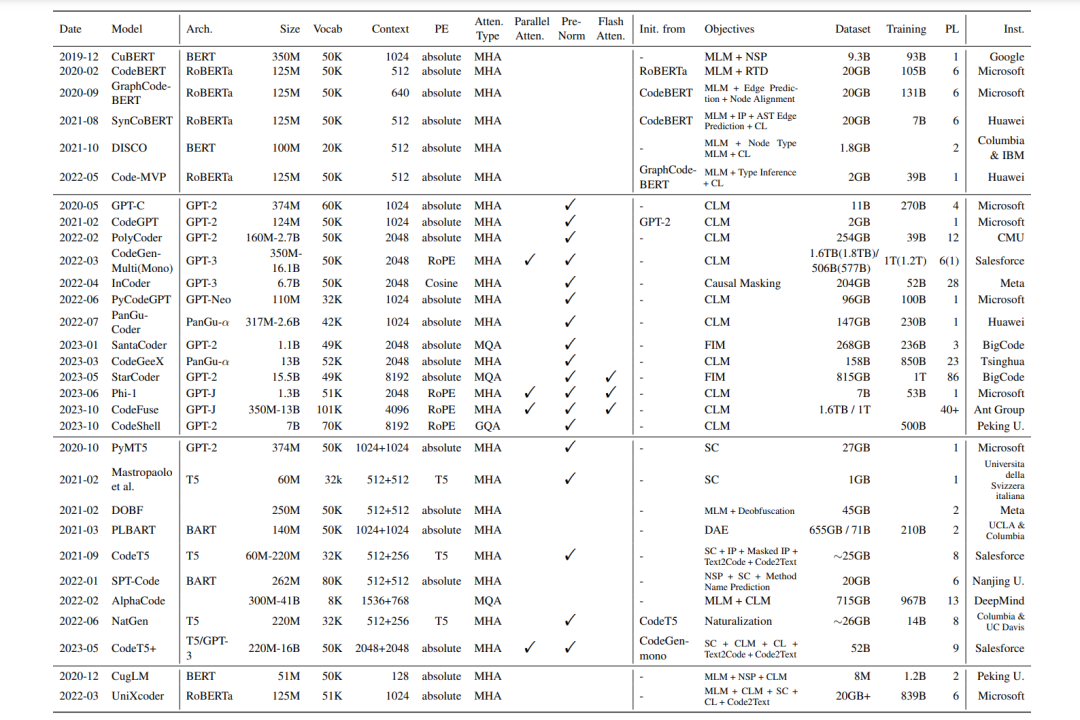
随着像GPT和BERT这样的预训练Transformers在自然语言处理中取得显著成功,这类模型架构、学习范式和训练目标很快被软件工程社区采纳,用于生产专用于代码理解和生成的模型。在本节中,我们首先回顾了用于预训练代码语言模型的常用数据集(§5.1),然后深入探讨了代码LMs的复杂家族,按照它们的模型架构分类:仅编码器模型(§5.2),编码器-解码器模型(§5.3),仅解码器模型(§5.4),UniLM(§5.5)和扩散模型(§5.6)。最后,在§5.7中,我们还展示了将NLP中更多最新技术,如指令调整(Wei等,2022年;Sanh等,2022年;Chung等,2022年)和强化学习(Ouyang等,2022年)应用于代码处理的当前趋势。这些预训练模型的概览提供在表3中
在这项工作中,我们系统地回顾了使用预训练Transformer语言模型进行代码处理的历史,并强调了它们与在一般领域上预训练的模型的关系和比较。代码建模的进步总体上遵循了NLP的历史进程,从SMT模型发展到NMT模型,然后发展到微调预训练的Transformers,最后到LLMs的少量样本应用,甚至在实际生产中应用自主代理。与自然语言不同,代码的特性使得从替代视角提取辅助信息变得容易,并利用解释器和单元测试进行自动反馈。