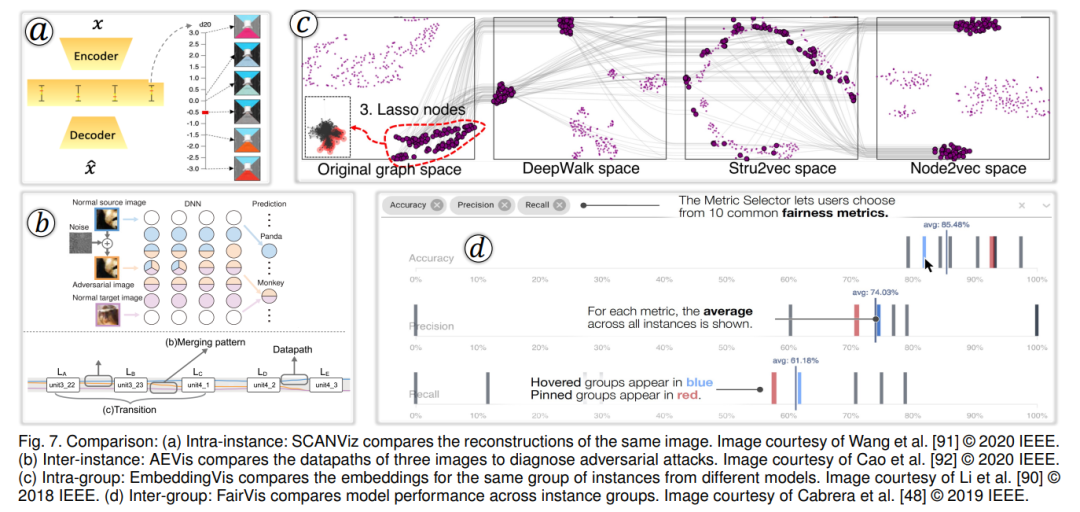
过去的十年,我们见证了大量的工作利用可视化(VIS)的力量来解释机器学习(ML)模型。相应的研究主题,VIS4ML,正在快速地发展。为了更好地组织这些庞大的工作,并阐明VIS4ML的发展趋势,我们通过这次调查为这些研究提供了一个系统的回顾。由于数据质量极大地影响了ML模型的性能,我们的调查特别从数据的角度总结VIS4ML的工作。首先,我们将机器学习模型处理的常见数据分为五种类型,解释每种类型的独特特点,并强调那些擅长从它们中学习的ML模型。其次,从大量的VIS4ML工作中,我们提炼出六项在ML流程的不同阶段操作这些数据类型的任务(即,数据为中心的任务),以理解、诊断和优化ML模型。最后,通过研究143篇调查论文在五种数据类型、六个数据为中心的任务及其交叉点的分布,我们分析了潜在的研究方向,并设想了未来的研究趋势。
https://www.zhuanzhi.ai/paper/468f07cc2f87eea04d54489bc7482dcf
近期,机器学习(ML)[1],尤其是深度学习(DL)[2], [3],的成功引起了研究者的极大关注。ML呈现出了一个普遍趋势,即模型变得越来越强大,但这往往以解释性逐渐降低为代价。随着对ML模型安全性和可靠性的担忧增加,它们的较差的解释性开始阻止它们在许多关键安全的应用中被采用,例如医学诊断[4]、[5]和自动驾驶[6]、[7]。为了减轻这个问题,近期已经投入了大量的可视化(VIS)努力来解释可解释的人工智能(XAI [8]),例如,扰动数据实例以探测ML模型的决策边界[9]、[10],训练可解释的代理来模拟ML模型的行为[11]、[12],从ML模型中提取中间数据以打开黑箱[13]、[14]等。这些工作构成了一个新的研究领域,即VIS4ML,而且这个蓬勃发展的领域中每年发布的论文数量正在增加。本调查的目标是系统地回顾它们并阐明它们的发展趋势。与此同时,从以模型为中心到以数据为中心发展ML模型的趋势正在上升[15]。尽管我们生活在大数据的时代,但数据中仍然存在许多质量问题,如噪声标签[16]、缺失项[17]和不平衡的数据分布[18]。随着建模技术变得越来越成熟,对ML开发者来说,显然可以从改进数据而不是模型中获得更多的性能提升。因此,随着ML模型的快速稳定演进,近期对改进ML模型的数据质量的研究越来越受到关注[15]。这也与著名的谚语“垃圾进,垃圾出”相呼应,即,如果没有高质量的输入数据,我们永远无法得到令人满意的ML模型。从ML领域转向数据中心建模的转变也激发了许多开创性的VIS工作,这些工作通过数据策划、校正和净化来检查和提高数据质量[16]、[19]、[20]。
为了促进这一新兴且有前景的方向,我们重新审视并从数据的角度系统地回顾现有的VIS4ML工作,以揭示已经进行的努力和仍然存在的机会。这样的回顾将有助于激发更多的VIS4ML想法并推动更多以数据为导向的创新。我们的数据中心调查旨在通过揭示它们关注的数据类型以及如何操作数据来解释、诊断和完善ML模型,系统地回顾最新的VIS4ML工作。该调查从以下三个方面进行。首先,我们确定ML模型处理的最常见的数据类型,它们的独特特点,以及如何定制ML模型以更好地从中学习(第4节)。其次,针对应用于确定的数据类型的操作,我们提出了六个以模型理解、诊断和完善为总体目标的数据中心VIS4ML任务[21]、[22](第5节)。第三,通过研究不同数据类型、VIS4ML任务及其交集上调查论文的分布,我们总结了正在进行的研究趋势,并揭示了有前景的VIS4ML研究方向(第6节)。本调查的贡献主要有两方面。首先,我们为VIS4ML提供了一个以数据为中心的分类,并按照这一分类全面回顾了最新的工作。分类和回顾帮助研究者更好地理解数量日益增长的VIS4ML工作,从一个新的角度重新审视它们,并鼓励研究者提出更多以数据为中心的VIS4ML工作。其次,从不同分类子类别的调查论文的覆盖范围来看,我们揭示了哪些数据类型、VIS4ML任务或数据任务组合尚未得到充分探索,从而指出了有前景的研究方向,并为这个蓬勃发展的领域提供了新的想法。我们还使用SurVis[23]开发了一个关于此调查的交互式网页,
网址为:https://vis4ml.github.io/。
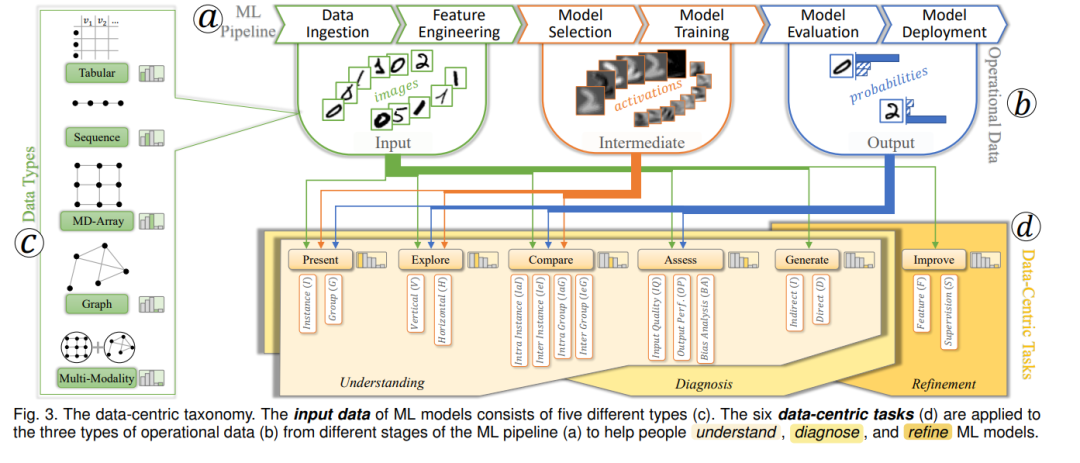
我们的数据中心综述是从两个方面进行的:(1) VIS4ML工作关注的数据类型;(2) 如何操作这些数据来解释、诊断或完善ML模型。这两方面的分类经历了多次迭代。我们在这里简要总结一些关键的迭代,以解释我们的调查原理。对于“什么”部分,我们首先按照ML执行流程(图3(a, b))确定了ML模型的操作数据为输入、中间和输出数据[40]。然后,我们尝试基于他们对三种数据类型的解释焦点来标记VIS4ML论文。但是,在进行了一些初始的标注后,我们发现几乎所有的VIS4ML论文都涵盖了输入和输出数据,其中一些使用了中间数据,而其他一些则没有。这种分类很快退化为两个基本上反映工作是特定于模型的(使用中间数据)还是与模型无关的(不使用中间数据)的类别。由于这个分类在早期的调查中已经被引入,我们没有继续这个尝试。后来,我们试图从数据库领域借用数据分类,并将数据分类为结构化和非结构化。但经过一些标记实践,我们注意到,VIS4ML工作中的大多数数据都是非结构化的(例如,图像、文本和图表)。使用这种分类无法揭示每种数据类型的独特特性(例如,空间或顺序)并导致了非常不平衡的数据类型分布。经过更多的探索,并受到ML模型定制处理的底层数据特性的启发(例如,CNNs/RNNs擅长处理空间/顺序数据),我们最终提出了我们当前的数据分类(详见第4节)。
对于“如何”部分,我们最初的分类是根据他们采用的VIS技术对论文进行分组(例如,节点链接图和散点图)。这似乎是最直接的选择。但是,我们很快意识到,确定的VIS技术对任何数据分析主题都是通用的,不能反映VIS4ML的独特性,也与我们的数据中心视角不一致。受Munzner的嵌套模型[41]的启发,我们接着将注意力转向VIS4ML论文的需求分析部分。在这里,我们发现要求大多是面向任务的。因此,我们转向检查现有的VIS任务分类,如第2节所总结。然而,大多数这些任务分类不是特定于VIS4ML的,而是适用于任何数据分析应用。经过几次更多的分类迭代,我们意识到,描述个别VIS4ML论文中的需求的句子揭示了VIS应该如何为ML服务。从这些句子中,我们提取了动词,即应用于ML数据的操作,并合并相似的操作来确定最具代表性的操作。最后,我们得出了六个特定于VIS4ML的任务(详见第5节)。此外,这些任务也是数据中心的,因为需求分析句子的对象始终与ML操作数据的三种类型有关。为了明确建立所识别的数据和任务之间的联系,我们在图3(b)和图3(d)之间用绿色、橙色和蓝色的箭头连接它们。
我们的数据中心分类法根据相应的ML模型关注的数据类型以及如何操作这些数据(即VIS4ML任务)来审查VIS4ML论文,以理解、诊断和完善ML模型,具体包括:
数据类型 (第4节):我们确定了输入到ML模型中的常见数据类型,描述了它们的独特特性,并解释了ML模型是如何被定制的,以便更好地从这些数据中学习。这些数据类型包括:表格、顺序、多维数组、图形和多模态数据(如图3(c)所示)。
数据中心任务 (第5节):关注于对这五种数据类型进行的操作,我们提取了六种数据中心的VIS4ML任务:展示、探索、评估、比较、生成和改进数据。前五项通常用于模型理解/诊断。生成任务与改进任务一起也用于模型精炼(参见图3(d))。
第4节和第5节详细描述了我们的数据/任务分类法,每个子类别都由一个或多个代表性的VIS作品示例化。由于不可能为所有143篇论文提供示例,我们在表1和2中对它们进行了总结。第6节展示了论文在数据类型、数据中心任务及其交集方面的分布,揭示了当前的研究趋势和潜在的未来方向。最后,我们在第7节讨论了我们调查的一些固有局限性,然后在第8节对其进行了总结。