

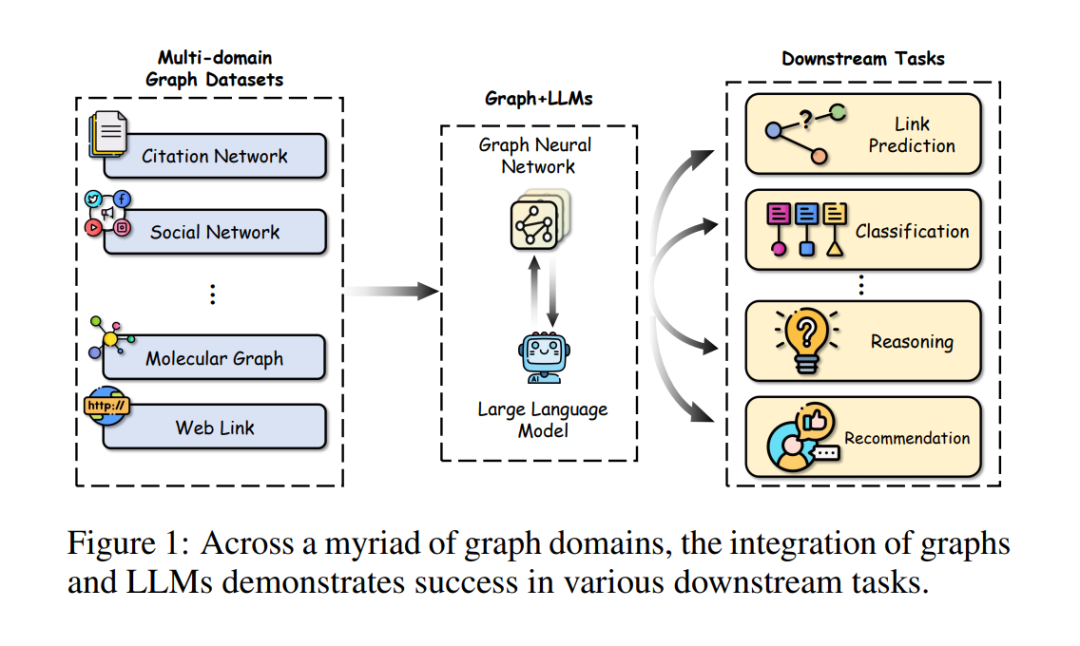
图在表示和分析诸如引文网络、社交网络和生物数据等实际应用中的复杂关系方面扮演着重要角色。最近,大型语言模型(LLMs),它们在各个领域取得了巨大成功,也被用于图相关任务,超越了传统的基于图神经网络(GNNs)的方法,实现了最先进的性能。在这篇综述中,我们首先全面回顾和分析了结合LLMs和图的现有方法。首先,我们提出了一个新的分类法,根据LLMs在图相关任务中扮演的角色(即增强器、预测器和对齐组件)将现有方法分为三类。然后,我们系统地调查了沿着分类法的三个类别的代表性方法。最后,我们讨论了现有研究的剩余局限性,并强调了未来研究的有希望的途径。相关论文已总结,并将在以下网址持续更新:https://github.com/yhLeeee/Awesome-LLMs-in-Graph-tasks。
图论,在现代世界的许多领域,特别是在技术、科学和物流领域,扮演着基础性的角色[Ji et al., 2021]。图数据代表了节点之间的结构特性,从而阐明了图组件内的关系。许多实际世界的数据集,如引文网络[Sen et al., 2008]、社交网络[Hamilton et al., 2017]和分子数据[Wu et al., 2018],本质上都是以图的形式表示的。为了处理图相关任务,图神经网络(GNNs)[Kipf and Welling, 2016; Velickovic et al., 2018]已经成为处理和分析图数据的最受欢迎的选择之一。GNNs的主要目标是通过在节点之间的递归信息传递和聚合机制,获取在节点、边或图层面上的表达性表示,用于不同种类的下游任务。
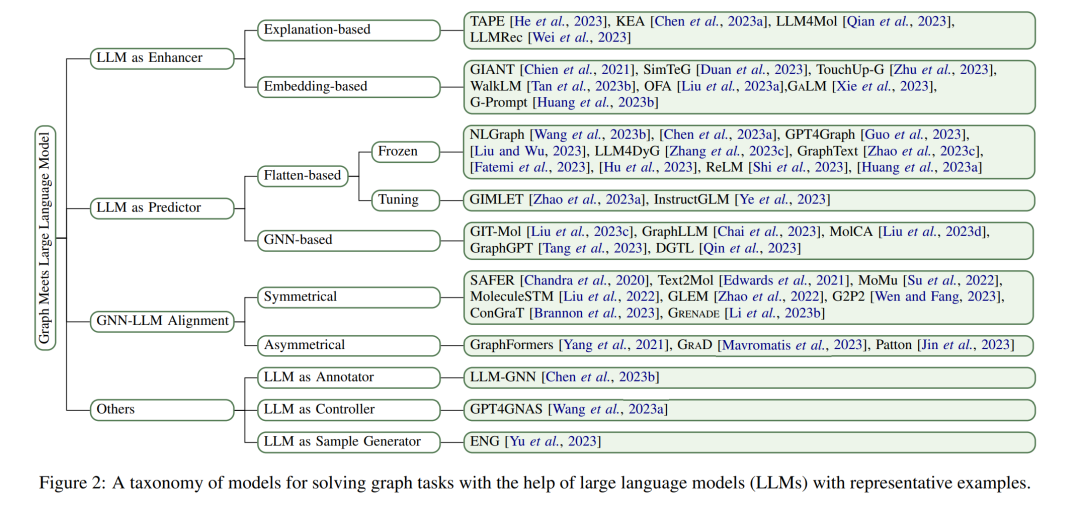
近年来,如Transformer [Vaswani et al., 2017]、BERT [Kenton and Toutanova, 2019]、GPT [Brown et al., 2020] 及其变体等大型语言模型(LLMs)在多个领域取得了重大进展。这些LLMs可轻易地应用于各种下游任务,几乎无需调整,就在多种自然语言处理任务中展现了卓越性能,例如情感分析、机器翻译和文本分类 [Zhao et al., 2023d]。虽然它们主要聚焦于文本序列,但目前越来越多的研究开始关注于增强LLMs的多模态能力,使其能够处理包括图形 [Chai et al., 2023]、图像 [Zhang et al., 2023b] 和视频 [Zhang et al., 2023a] 在内的多种数据类型。 LLMs在图相关任务中的应用已显著改变了我们与图的交互方式,特别是那些含有与文本属性相关联的节点的图。将LLMs与传统GNNs(图神经网络)的结合可以带来互利共赢,增强图学习。尽管GNNs擅长捕捉结构信息,但它们主要依赖语义上受限的嵌入作为节点特征,这限制了它们表达节点完整复杂性的能力。通过整合LLMs,GNNs可以得到更强大的节点特征,有效捕捉结构和语境方面的信息。另一方面,LLMs擅长编码文本,但通常难以捕捉图数据中的结构信息。结合GNNs和LLMs可以利用LLMs强大的文本理解能力,同时发挥GNNs捕捉结构关系的能力,从而实现更全面、强大的图学习。例如,TAPE [He et al., 2023] 利用与节点(如论文)相关的语义知识,这些知识由LLMs生成,来提高GNNs中初始节点嵌入的质量。此外,InstructGLM [Ye et al., 2023] 用LLMs替换了GNNs中的预测器,通过平铺图形和设计提示(提示)等技术,利用自然语言的表现力。MoleculeSTM [Liu et al., 2022] 将GNNs和LLMs对齐到同一向量空间,将文本知识引入图形(如分子)中,从而提高推理能力。 显然,LLMs从不同角度对图相关任务产生了重要影响。为了更好地系统概览,如图2所示,我们遵循Chen et al. [2023a]的方法,组织我们的一级分类法,基于LLMs在整个模型管道中扮演的角色(即增强器、预测器和对齐组件)进行分类。我们进一步细化我们的分类法,并为初始类别引入更多细粒度。 动机。尽管LLMs在图相关任务中的应用越来越广泛,但这个迅速发展的领域仍然缺乏系统的综述。张等人[Zhang et al., 2023d]进行了一项前瞻性综述,提出了一篇讨论图与LLMs整合所面临挑战和机遇的观点文章。刘等人[Liu et al., 2023b]提供了另一项相关综述,总结了现有的图基础模型,并概述了预训练和适应策略。然而,这两篇文章都在全面覆盖和缺乏专门关注LLMs如何增强图的分类法方面存在局限性。相比之下,我们专注于图和文本模态共存的场景,并提出了一个更细粒度的分类法,以系统地回顾和总结LLMs技术在图相关任务中的当前状态。
贡献。这项工作的贡献可以从以下三个方面总结: (1)结构化分类法。通过结构化分类法,对该领域进行了广泛概览,将现有工作分为四类(图2)。 (2)全面综述。基于提出的分类法,系统地描述了LLMs在图相关任务中的当前研究进展。 (3)一些未来方向。我们讨论了现有工作的剩余局限性,并指出了可能的未来发展方向。
**LLM作为增强器 **
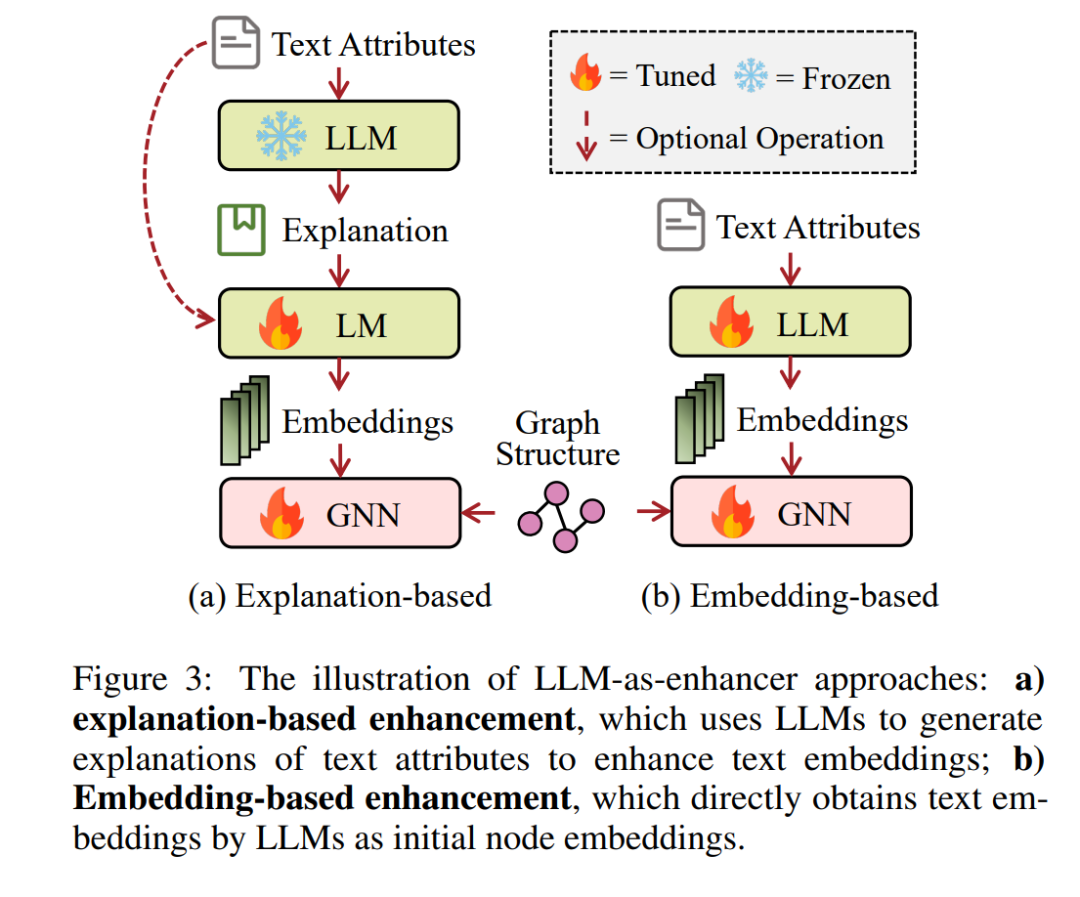
图神经网络(GNNs)已成为分析图结构数据的强大工具。然而,最主流的基准数据集(例如,Cora [Yang et al., 2016] 和 Ogbn-Arxiv [Hu et al., 2020])采用了朴素的方法来编码TAGs中的文本信息,使用的是浅层嵌入,如词袋法、跳跃模型 [Mikolov et al., 2013] 或 TF-IDF [Salton and Buckley, 1988]。这不可避免地限制了GNNs在TAGs上的性能。LLM作为增强器的方法对应于利用强大的LLMs来提升节点嵌入的质量。衍生的嵌入被附加到图结构上,可以被任何GNNs利用,或直接输入到下游分类器中,用于各种任务。我们自然地将这些方法分为两个分支:基于解释和基于嵌入,这取决于它们是否使用LLMs产生额外的文本信息。
LLM作为预测器
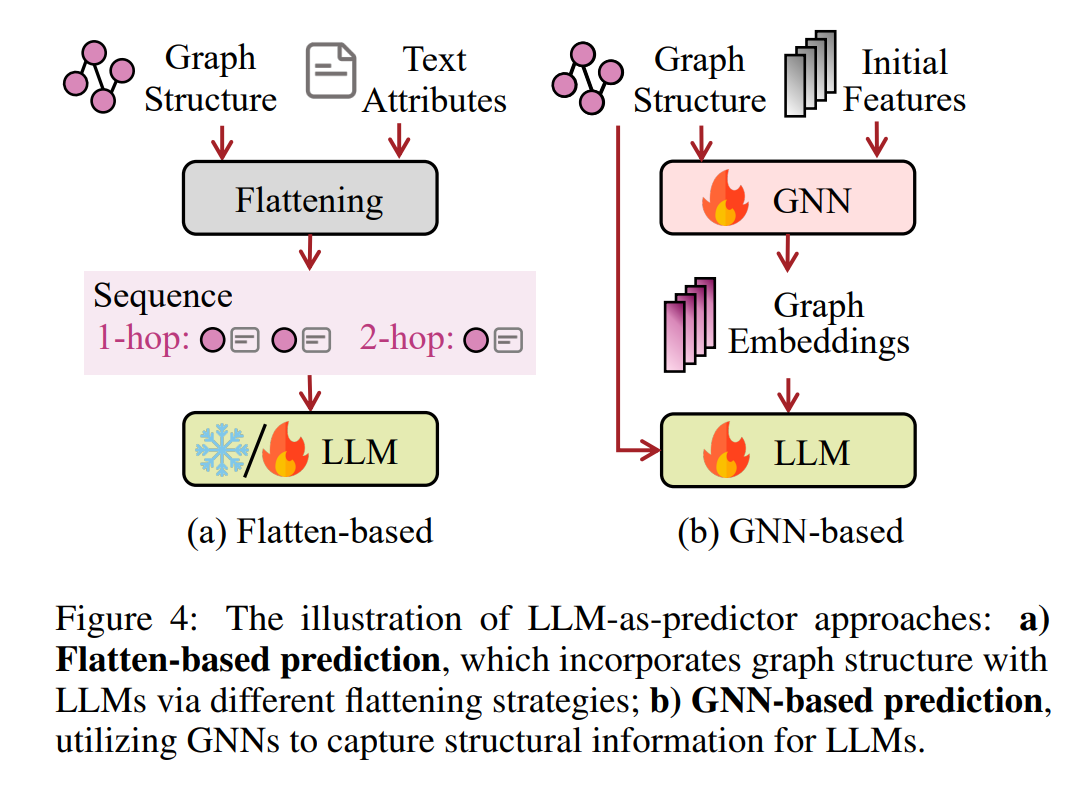
这一类别的核心思想是利用LLMs来对广泛的图相关任务进行预测,例如在统一的生成范式下的分类和推理。然而,将LLMs应用于图模态提出了独特的挑战,主要是因为图数据往往缺乏直接转换成序列文本的方式,不同的图以不同的方式定义结构和特征。在这一部分,我们根据模型是否使用GNNs来提取结构特征供LLMs使用,将模型大致分为基于平铺和基于GNN的预测两类。
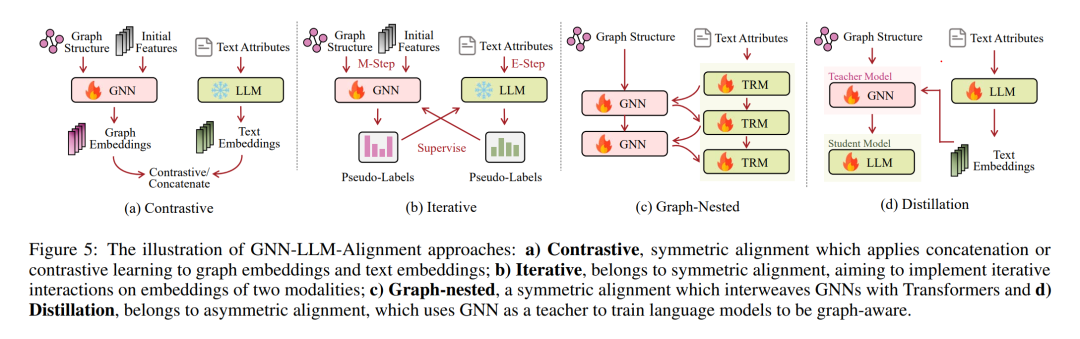
GNN-LLM 对齐
对GNNs和LLMs的嵌入空间进行对齐是整合图模态与文本模态的有效方式。GNN-LLM对齐确保在特定阶段协调它们的嵌入空间时,每个编码器的独特功能得以保留。在这一部分,我们总结了对齐GNNs和LLMs的技术,这些技术可以根据是否对GNNs和LLMs都给予同等重视,或是否优先考虑一种模态而另一种模态则不那么重视,被分类为对称或非对称。
结论
近年来,将大型语言模型(LLMs)应用于与图相关的任务已成为研究的一个突出领域。在这篇综述中,我们旨在提供对适应图的LLMs的现有策略的深入概述。首先,我们介绍了一个新的分类法,根据LLMs所扮演的不同角色(即增强器、预测器和对齐组件),将涉及图和文本模态的技术分为三类。其次,我们根据这种分类系统地回顾了代表性的研究。最后,我们讨论了一些限制,并强调了几个未来的研究方向。通过这篇全面的综述,我们希望能够揭示LLMs在图学习领域的进步和挑战,从而鼓励在这一领域进一步的提升。

