

大型语言模型(LLMs)在自然语言理解、语言生成和复杂推理等重要任务中展示了显著能力,并有潜力对我们的社会产生重大影响。然而,这些能力伴随着它们所需的大量资源,突显了开发有效技术以应对其效率挑战的强烈需求。在本综述中,我们提供了对高效LLMs研究的系统性和全面的回顾。我们组织了文献,形成了一个由三个主要类别构成的分类法,分别从模型中心、数据中心和框架中心的视角,涵盖了不同但相互关联的高效LLMs主题。我们还创建了一个GitHub仓库,在 https://github.com/AIoTMLSys-Lab/Efficient-LLMs-Survey 收录了本综述中的论文,并将积极维护这个仓库,将新的研究成果纳入其中。我们希望我们的综述能成为帮助研究人员和实践者系统理解高效LLMs研究发展的宝贵资源,并激励他们为这个重要且令人兴奋的领域做出贡献。
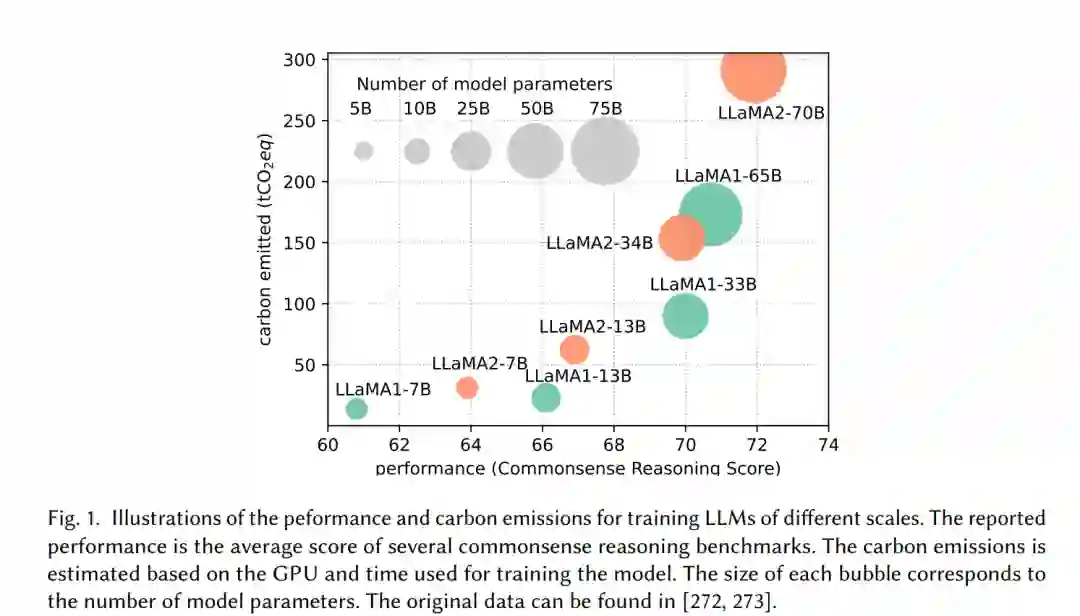
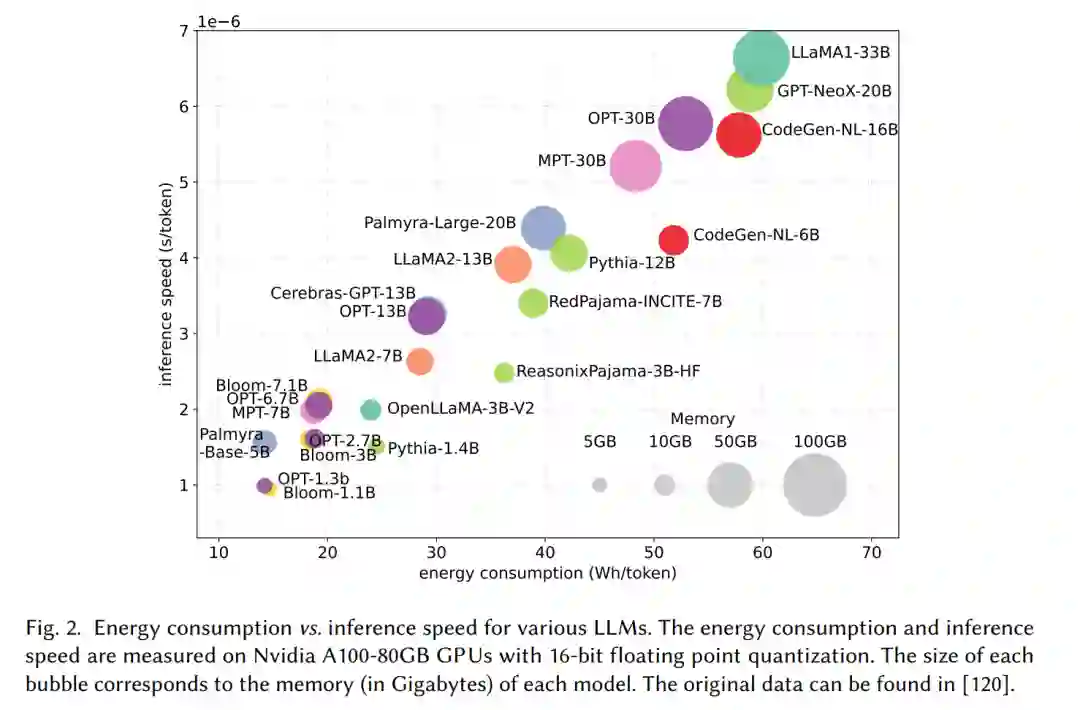
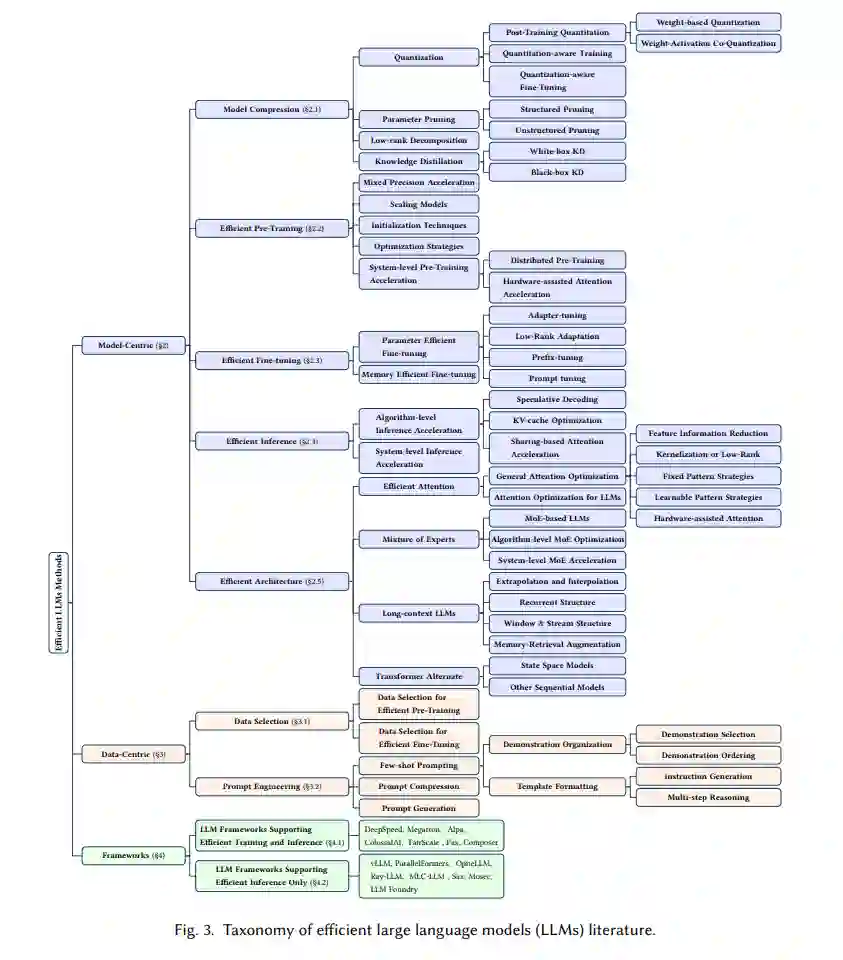
大型语言模型(LLMs)是一种先进的人工智能模型,旨在理解和生成人类语言。最近,我们见证了GPT系列(GPT-3 [21] 和 GPT-4 [197])、谷歌系列(Gemini [266]、GLaM [71]、PaLM [50]、PaLM-2 [8])、Meta系列(LLaMA 1&2 [272, 273])、BLOOM [233]、盘古之心 [227] 和 GLM [339]等LLMs的兴起,以及它们在自然语言理解(NLU)、语言生成、复杂推理[320]和与生物医学[278, 280]、法律[72]及代码生成[34, 300]等领域相关的任务中取得的显著表现。这些性能突破归功于它们的巨大规模,因为它们包含数十亿甚至数万亿个参数,同时又在大量数据上进行训练,这些数据来自多样化的来源。 尽管LLMs引领着人工智能的下一波革命,但LLMs的显著能力却以其巨大的资源需求为代价[50, 71, 197, 227]。图1展示了LLaMA系列模型性能与训练过程中碳排放之间的关系。如图所示,随着模型参数数量的增加,碳排放量呈指数级增长。除了训练之外,推理(inference)也对LLMs的运营成本有着相当大的贡献。如图2所示,更先进的LLMs在推理过程中表现出更高的内存使用和能源消耗,这对于以经济有效的方式将这些模型扩展到更广泛的客户群和多样化的应用中提出了挑战。随着LLMs应用和客户群的快速扩张,推理过程中的运营成本(包括能源消耗和内存使用)将增加,超过训练成本,成为整体环境影响的主导因素。 LLMs的高资源消耗推动了开发技术以提高LLMs效率的需求。本综述的总体目标是提供一个全面的视角,概述高效LLMs的技术进展,并总结现有的研究方向。如图3所示,我们将文献组织成一个由三个主要类别构成的分类法,分别从模型中心、数据中心和框架中心的视角,涵盖了高效LLMs的主题。这三个类别涵盖了不同但相互关联的研究主题,共同提供了对高效LLMs研究的系统性和全面的回顾。具体来说,
•** 模型中心方法**:模型中心方法侧重于以模型本身为焦点的算法层面和系统层面的高效技术。由于LLMs拥有数十亿甚至数万亿个参数,它们表现出与小规模模型不同的特征[299],这促使了新技术的发展。在第2部分,我们调查了涵盖模型压缩、高效预训练、高效微调、高效推理和高效架构设计相关的研究方向的高效技术。
• 数据中心方法:在LLMs领域,数据的重要性与模型本身一样关键。数据中心方法侧重于数据质量和结构在提高LLMs效率方面的作用。在第3部分,我们调查了涵盖数据选择和提示工程相关研究方向的高效技术。
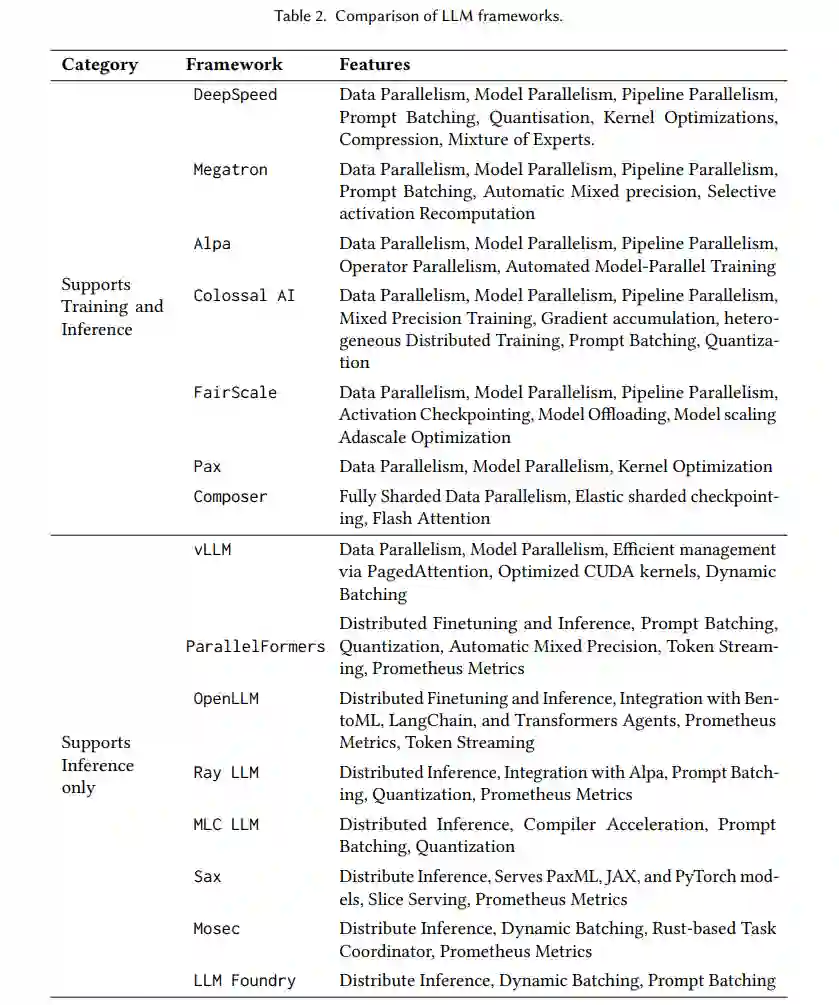
• LLM框架:LLMs的出现促使开发专门的框架,以高效地处理它们的训练、推理和服务。虽然主流的人工智能框架(如TensorFlow、PyTorch和JAX)提供了基础,但它们缺乏对LLMs至关重要的特定优化和特性的内置支持。在第4部分,我们调查了专门为高效LLMs设计的现有框架,介绍了它们的独特特性、底层库和专门化。
最后,我们建立了一个GitHub仓库,在 https://github.com/AIoT-MLSys-Lab/EfficientLLMs-Survey 上汇编了本综述中的论文,并将它们按照相同的分类法组织起来。我们将积极维护它并纳入新的研究成果。我们希望这个综述以及GitHub仓库能帮助研究人员和从业者浏览文献,并作为激发对高效LLMs进一步研究的催化剂。
以模型为中心
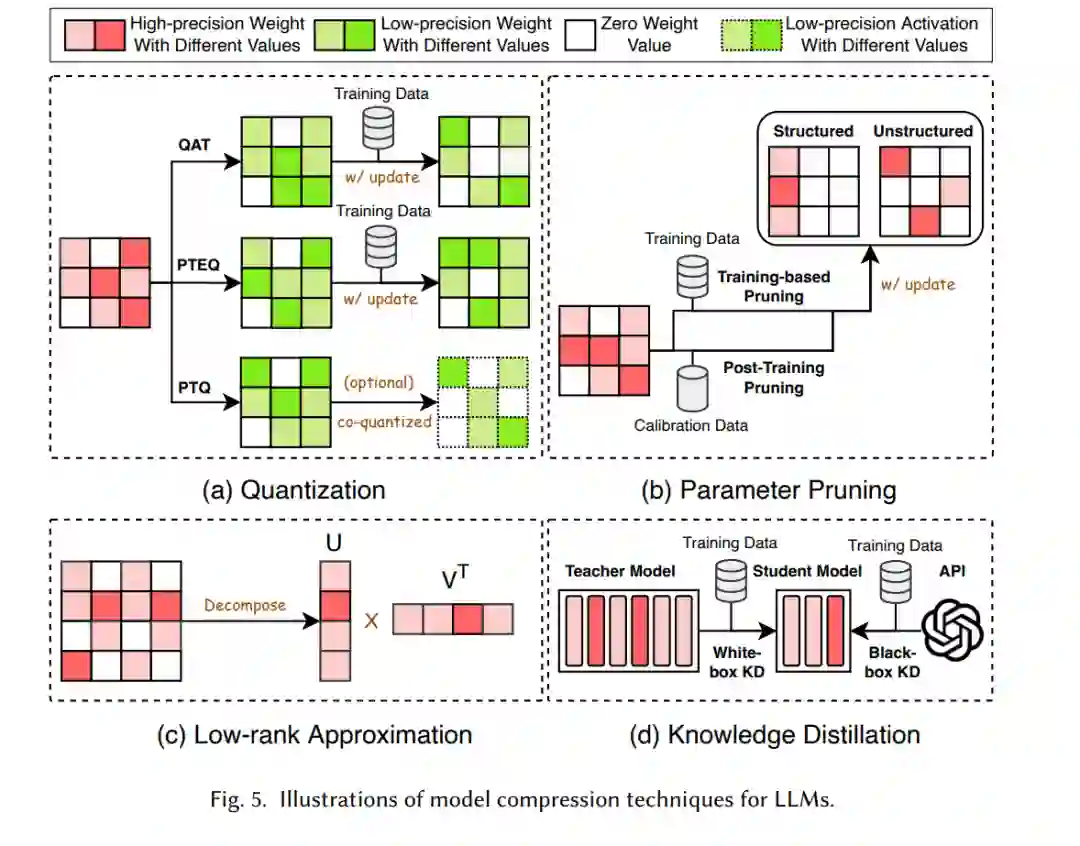
正如图4所总结的,大型语言模型(LLMs)的模型压缩技术可以分为四类:量化、参数剪枝、低秩近似和知识蒸馏。
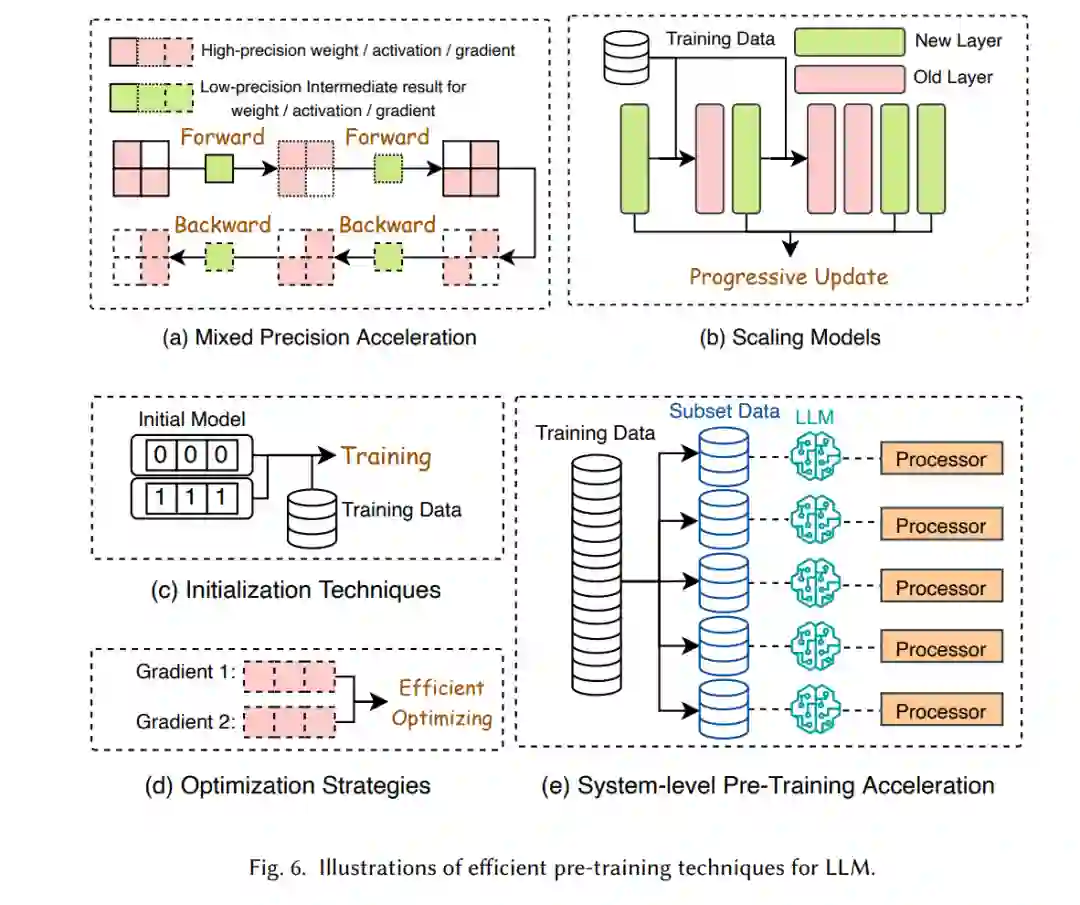
如表1所示,预训练大型语言模型(LLMs)的成本极其昂贵。高效的预训练旨在提高预训练过程的效率并降低成本。正如图7所总结的,高效预训练技术可以分为四类:混合精度加速、模型缩放、初始化技术和优化策略。
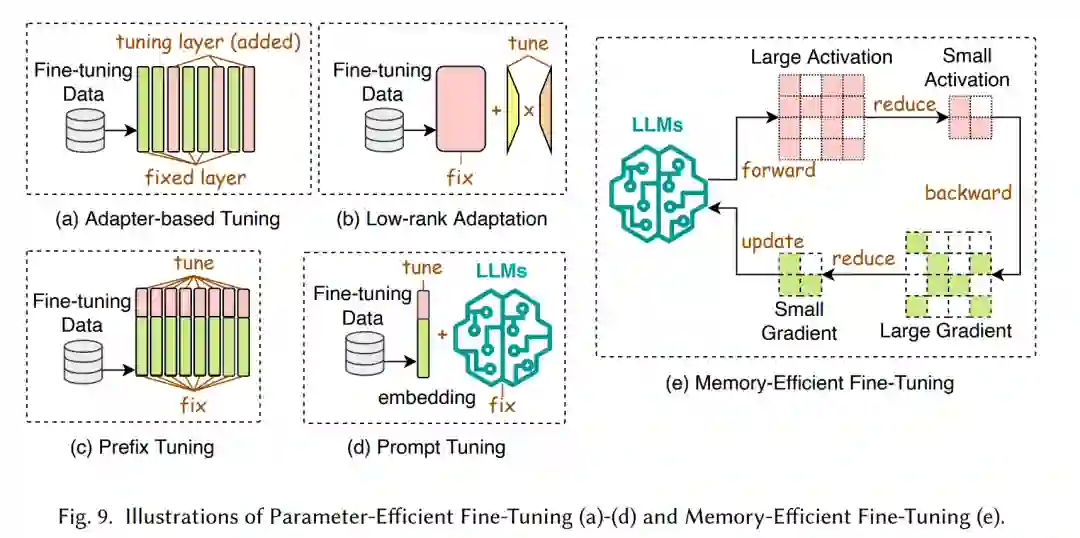
高效微调旨在提高大型语言模型(LLMs)微调过程的效率。正如图8所示,高效微调方法可以分为参数高效微调(PEFT)和内存高效微调(MEFT)。
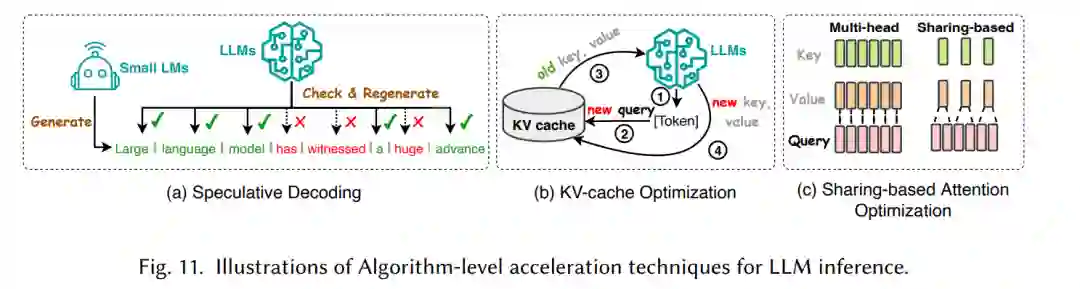
高效推理旨在提高大型语言模型(LLMs)推理过程的效率。正如图10所总结的,高效推理技术可以分为算法层面和系统层面的加速技术。
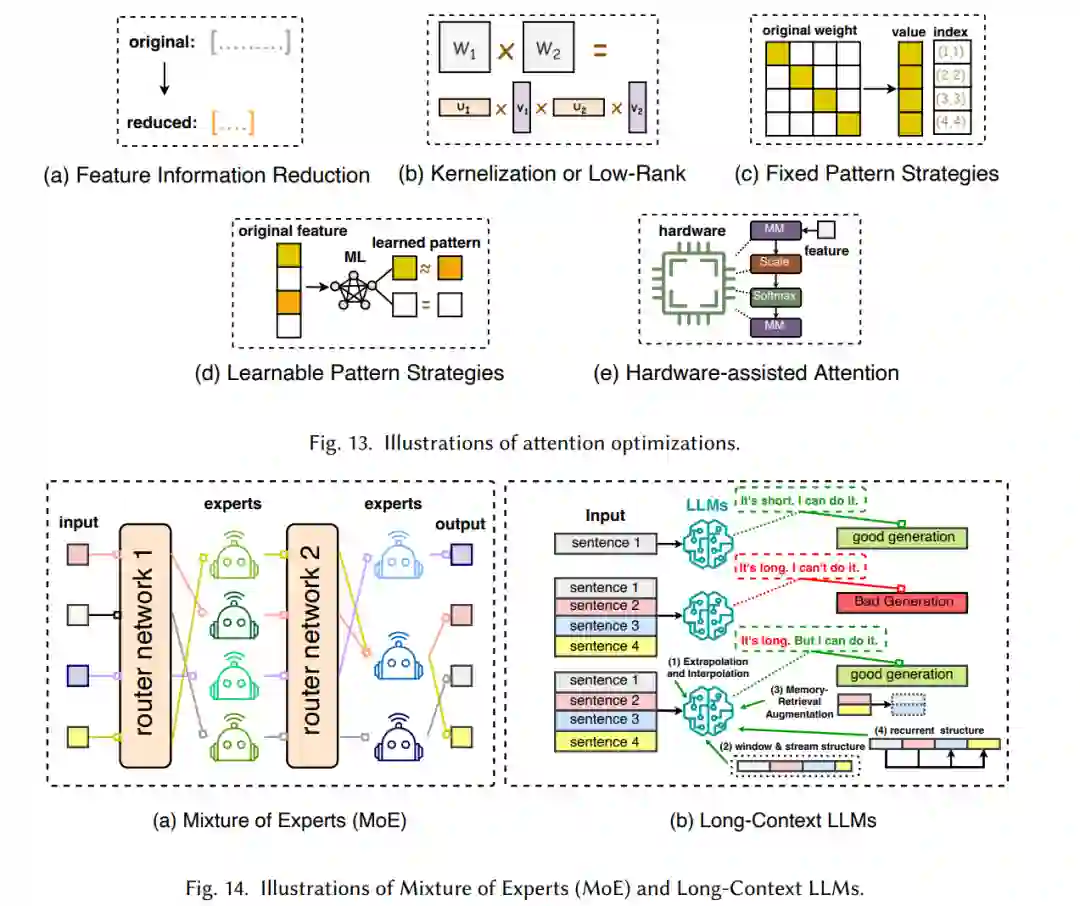
针对大型语言模型(LLMs)的高效架构设计是指对模型结构和计算过程进行战略性优化,以提升性能和可扩展性,同时最小化资源消耗。图12总结了大型语言模型的高效架构设计。
以数据为中心
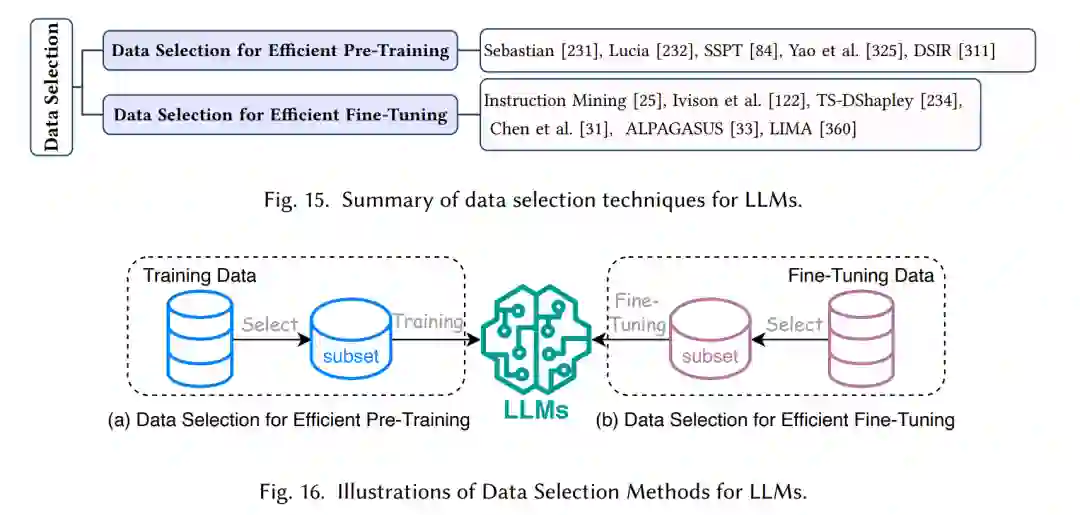
大型语言模型(LLMs)的数据选择涉及对数据源、质量和预处理的仔细考虑。确保高质量数据是开发高效可靠的LLMs的基础,因为它影响着它们的学习、泛化和在各种任务上准确执行的能力。[84, 232, 311, 325]。这个过程对于避免在模型中传播偏见和不准确性至关重要,使得LLMs训练能够收敛。研究人员正在开发优化数据选择、数据压缩和提示微调等策略,以提高性能同时使用较少的资源。图15总结了高效预训练和微调的最新数据选择技术。
提示工程[167]涉及设计有效的输入(提示),以引导大型语言模型(LLMs)生成期望的输出。这对于LLMs至关重要,因为提示工程使得LLMs能够针对特定任务进行定制,而无需大量标记数据。高效技术使得这些模型能够在较少的计算开销下准确处理信息和响应。基于提示的语言模型所涉及的计算成本一直是持续研究的主题,特别是在特定任务应用的背景下。正如图17所总结的,提示工程技术可以分为少量样本提示、提示压缩和提示生成。
LLM框架
结论
在这篇综述中,我们提供了对高效大型语言模型(LLMs)的系统性回顾,这是一个旨在实现LLMs民主化的重要研究领域。我们从阐述高效LLMs的必要性开始。通过一个分类体系,我们分别从以模型为中心和以数据为中心的角度,回顾了LLMs的算法层面和系统层面的高效技术。此外,我们还回顾了具有特定优化和特性的LLMs框架,这些对高效LLMs至关重要。我们认为,效率将在LLMs及以LLMs为导向的系统中发挥越来越重要的作用。我们希望这篇综述能够使研究人员和实践者快速进入这一领域,并作为激发高效LLMs新研究的催化剂。


