

尽管人工智能已经取得了令人瞩目的成就,但其正向通用人工智能的道路上前进。由OpenAI开发的Sora具备分钟级的世界模拟能力,可被视为这一发展路径上的一个里程碑。然而,尽管取得了显著成功,Sora仍然面临着需要解决的各种障碍。在本综述中,我们从Sora在文本生成视频方面的视角出发,进行文献的全面回顾,试图回答一个问题:我们能从Sora中看到什么。具体来说,在介绍了基本的通用算法之后,我们从三个相互垂直的维度对文献进行了分类:进化生成器、卓越追求和现实全景。随后,对广泛使用的数据集和评估指标进行了详细整理。最后但同样重要的是,我们识别了该领域的若干挑战和开放性问题,并提出了未来研究和发展的潜在方向。本综述中的文本生成视频研究的完整列表可在以下链接找到:
https://github.com/soraw-ai/Awesome-Text-to-Video-Generation

近年来,AI生成内容(AIGC)领域的快速进展标志着实现通用人工智能(AGI)迈出了关键的一步,特别是在OpenAI于2023年初推出其大型语言模型(LLM)GPT-4之后。AIGC引起了学术界和工业界的极大关注,其中包括基于LLM的对话代理ChatGPT [1],以及文本生成图像(T2I)模型如DALL·E [2]、Midjourney [3]和Stable Diffusion [4]。这些成就显著影响了文本生成视频(T2V)领域,并在OpenAI的Sora [5]中展示了非凡的能力,如图1所示。 正如[5]中所阐明的那样,Sora被设计为一个复杂的世界模拟器,能够根据文本指令生成现实且富有想象力的场景。其卓越的扩展能力使其能够高效地从互联网规模的数据中学习,这得益于DiT模型 [6]的集成,该模型取代了传统的U-Net架构 [7]。这一战略性整合使Sora与GenTron [8]、W.A.L.T [9]和Latte [10]等类似的进展相一致,增强了其生成能力。Sora独特地具备生成高质量的分钟级视频的能力,这是现有T2V研究尚未实现的 [11]、[12]、[13]、[14]、[15]、[16]、[17]、[18]、[19]、[20]、[21]、[22]、[23]、[24]、[25]、[26]。它还在生成高分辨率和无缝质量的视频方面表现出色,与现有T2V方法的进展相媲美 [27]、[28]、[29]、[30]、[31]、[32]、[33]、[34]、[35]。虽然Sora在生成复杂物体方面显著提升,超越了以往的研究 [36]、[37]、[38]、[39],但在确保这些物体之间的连贯运动方面仍面临挑战。尽管如此,必须承认Sora在呈现具有复杂细节的场景(包括主体和背景)方面的卓越能力,超越了以往专注于复杂场景 [24]、[40]、[41]、[42] 和合理布局生成的研究 [42]、[44]、[45]。 据我们所知,有两篇与我们研究相关的综述:[46]和[47]。[46]涵盖了从视频生成到编辑的广泛主题,提供了一个总体概述,但只关注了有限的基于扩散的文本生成视频(T2V)技术。同时,[47]对Sora进行了详细的技术分析,提供了相关技术的初步综述,但在T2V领域缺乏深度和广度。为此,我们的工作旨在填补这一空白,通过提供对T2V方法、基准数据集、相关挑战和未解决问题的详尽回顾,以及未来研究方向的前瞻性,贡献一个更为细致和全面的视角。 贡献:在本综述中,我们通过对OpenAI的Sora的深入研究,对文本生成视频(T2V)领域进行了全面的回顾。我们系统地追踪并总结了最新的文献,提炼了Sora的核心元素。本文还阐明了基础概念,包括在该领域至关重要的生成模型和算法。我们深入探讨了所调查文献的具体内容,从所使用的算法和模型到用于生成高质量视频的技术。此外,本综述还对T2V数据集和相关评估指标进行了广泛的调查。重要的是,我们揭示了T2V研究中的当前挑战和未解决的问题,并根据我们的见解提出了未来的发展方向。 章节结构:本文的结构如下:第二部分提供了基础概述,包括T2V生成的目标以及支撑这项技术的核心模型和算法。第三部分主要基于我们对Sora的观察,提供了所有相关领域的广泛概述。第四部分进行了详细分析,强调了T2V研究中的挑战和未解决的问题,特别关注从Sora中获得的见解。第五部分专门用于概述未来的研究方向,这些方向是基于我们对现有研究的分析和Sora的关键方面所确定的。本文在第六部分总结了我们的结论,综合了从全面回顾中得出的见解和影响。
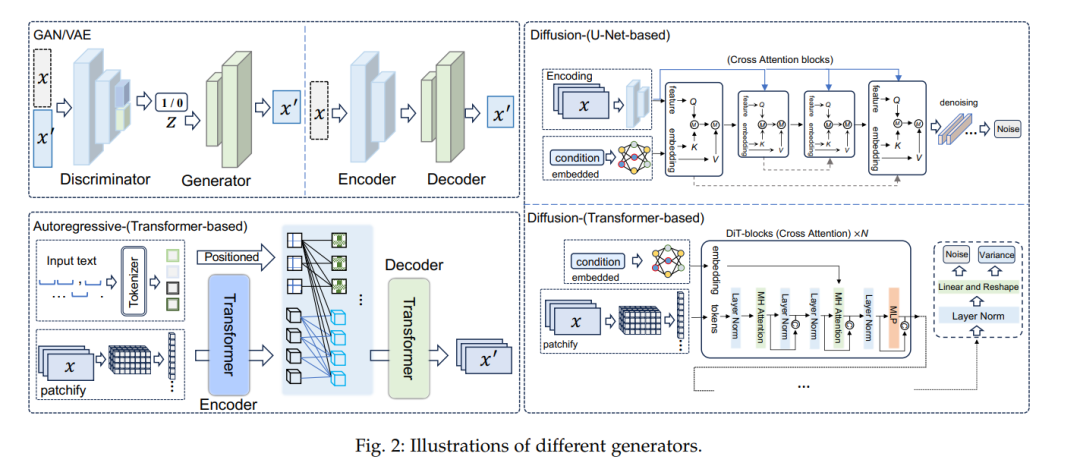
随着文本生成图像技术的重大突破,人类开始探索更具挑战性的文本生成视频领域,该领域能够传达和封装更丰富的视觉信息。尽管近年来这一领域的研究进展较为缓慢,但Sora的推出极大地重燃了希望,标志着一个重要的转折点,为该领域注入了新的活力。
因此,在本节中,我们将从Sora尤其是T2V生成领域中获得的关键见解系统地分类为三个主要类别,并对每个类别进行详细回顾:进化生成器(见第3.1节)、卓越追求(见第3.2节)、现实全景(见第3.3节)以及数据集和评估指标(见第3.4节)。全面的结构如图3所示。
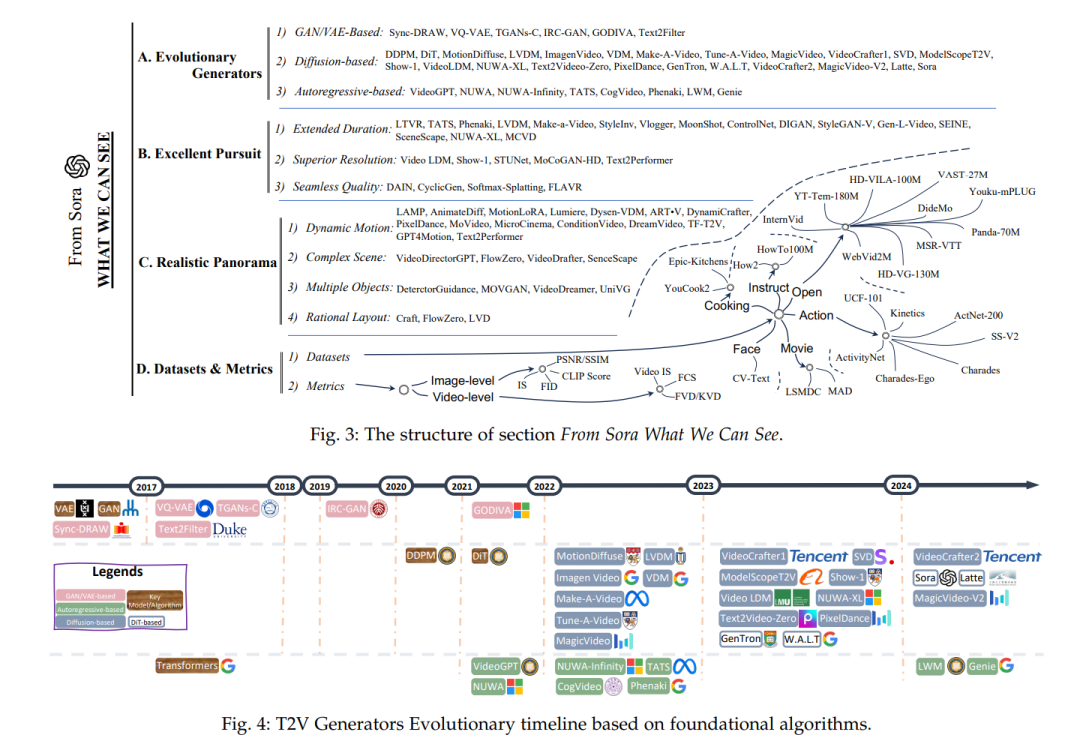
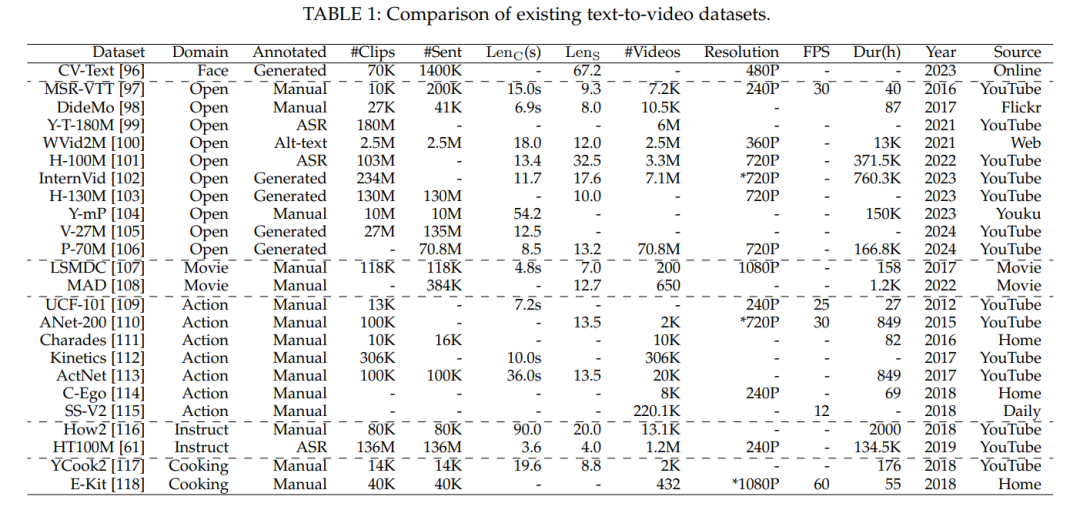
结论 基于对Sora的分解,本综述对当前文本生成视频(T2V)工作进行了全面回顾。具体来说,我们从生成模型演变的角度组织了文献,涵盖了基于GAN/VAE、自回归和扩散的框架。此外,我们深入审查了文献,基于优秀视频应具备的三种关键品质:延长的持续时间、卓越的分辨率和无缝的质量。此外,鉴于Sora被称为真实世界模拟器,我们展示了一个包含动态运动、复杂场景、多物体和合理布局的现实全景。此外,常用的视频生成数据集和评估指标根据其来源和应用领域进行了分类。最后,我们识别了一些T2V领域剩余的挑战和问题,并提出了未来发展的潜在方向。


