

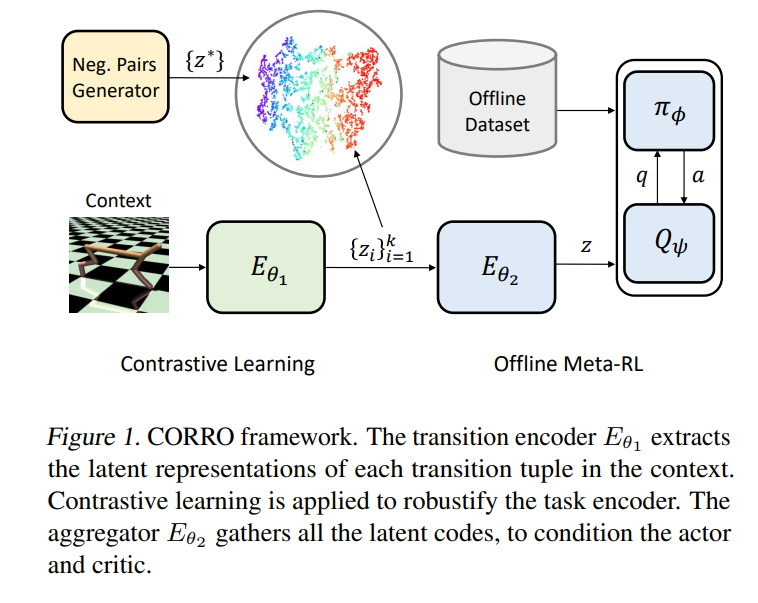
我们研究离线元强化学习,这是一种实用的强化学习范式,从离线数据中学习以适应新的任务。离线数据的分布由行为策略和任务共同决定。现有的离线元强化学习算法无法区分这些因素,导致任务表示对行为策略的变化不稳定。为了解决这个问题,我们提出了一个任务表示的对比学习框架,该框架对训练和测试中的行为策略分布不匹配具有鲁棒性。我们设计了一个双层编码器结构,使用互信息最大化来形式化任务表示学习,导出了一个对比学习目标,并引入了几种方法来近似负对的真实分布。在各种离线元强化学习基准上的实验表明,我们的方法比以前的方法更有优势,特别是在泛化到非分布行为策略上。代码可以在https://github.com/PKU-AI-Edge/CORRO上找到。
成为VIP会员查看完整内容
相关内容

Arxiv
0+阅读 · 2022年8月12日
Arxiv
0+阅读 · 2022年8月10日
Arxiv
11+阅读 · 2021年9月24日

相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年8月12日
Arxiv
0+阅读 · 2022年8月10日
Arxiv
11+阅读 · 2021年9月24日