
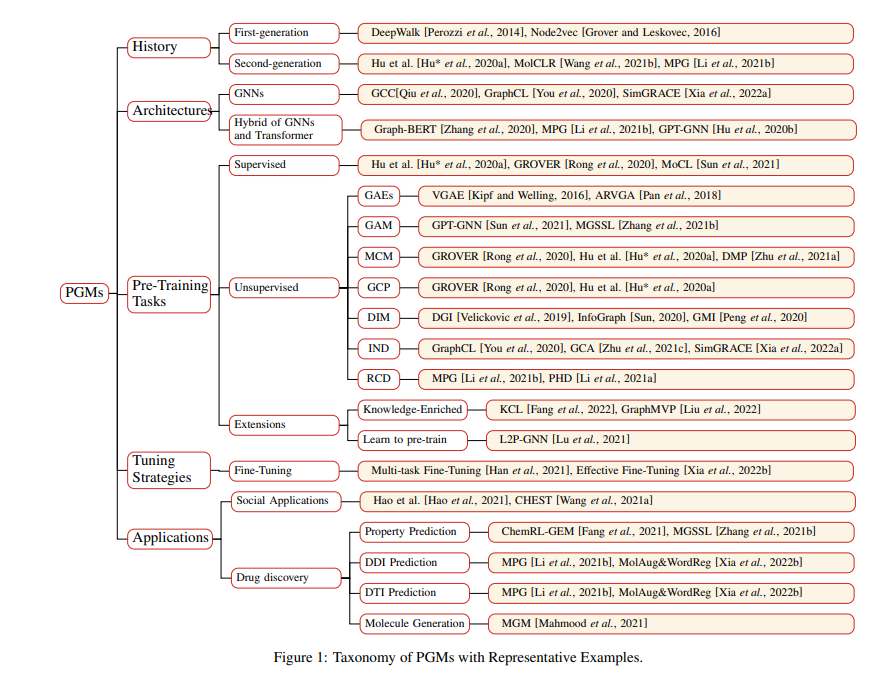
像BERT这样的预训练语言模型(Pre-trained Language Models , PLMs)已经彻底改变了自然语言处理(NLP)的前景。受其启发,人们最近在预训练图模型(PGMs)上投入了大量的精力。由于模型参数庞大,PGM能够从大量有标记和无标记的图数据中获取丰富的知识。隐含编码在模型参数中的知识可以使各种下游任务受益,并有助于缓解在图上学习的几个基本问题。在这篇论文中,我们提供了一个全面的PGMs综述。我们首先简要介绍了图表示学习的局限性,从而介绍了图预训练的动机。接下来,我们从历史、模型架构、预训练策略、调优策略和应用等五个不同的角度,对现有的PGM进行了系统的分类。最后,我们提出了几个有前景的研究方向,可以作为今后研究的指导方针。
成为VIP会员查看完整内容
相关内容
专知会员服务
24+阅读 · 2022年3月15日
专知会员服务
140+阅读 · 2020年7月10日
专知会员服务
99+阅读 · 2020年7月3日
专知会员服务
207+阅读 · 2020年2月16日
相关VIP内容
专知会员服务
24+阅读 · 2022年3月15日
专知会员服务
140+阅读 · 2020年7月10日
专知会员服务
99+阅读 · 2020年7月3日
专知会员服务
207+阅读 · 2020年2月16日
相关资讯
相关论文