图神经网络GNN预训练技术进展概述
论文推荐 /introduction/
机器学习的成功很大程度上取决于数据。但是,高质量的标记数据通常很昂贵且难以获得,尤其是对于训练参数较多的模型。而我们却可以很容易地获取大量的无标记数据,其数量可能是标记数据的数千倍。
为了解决标注数据较少的问题,我们要尽可能利用其无标注数据,一个常规的做法是自监督的预训练(self-supervised pre-training)。其目标是设计合理的自监督任务,从而使模型能从无标注数据里学得数据的信息,作为初始化迁移到下游任务中。由于目标任务中很多的知识已经在预训练中学到,因此通过预训练,我们只需要非常少量的标注数据,就能得到较好的泛化性能。
这里我们为大家推荐四篇有关于GNN预训练的文章:
Learning to Pre-train Graph Neural Networks
Pre-Training Graph Neural Networks for Cold-Start Users and Items Representation
GPT-GNN: Generative Pre-Training of Graph Neural Networks
Strategies for Pre-training Graph Neural Networks
1
Strategies for Pre-training Graph Neural Networks

这篇文章是业界大牛Jure的文章,他的团队提出了一个新的策略和自监督方法来预训练GNN。
这个模型的中心思想是,在单个节点及整个图的层级上预训练GNN,这样GNN就可以同时学习到有用的局部和全局表示。
经过在多个图分类数据集上的研究,我们发现,传统的策略(要么在整个图上,要么在单个节点上预训练GNN)的性能提升是受限的,甚至可能会在下流任务上造成相反的迁移。而我们的策略避免了相反的迁移,并且在下流任务上提升了泛化能力。相较于SOTA模型能够得到高达9.4%的ROC-AUC提升。
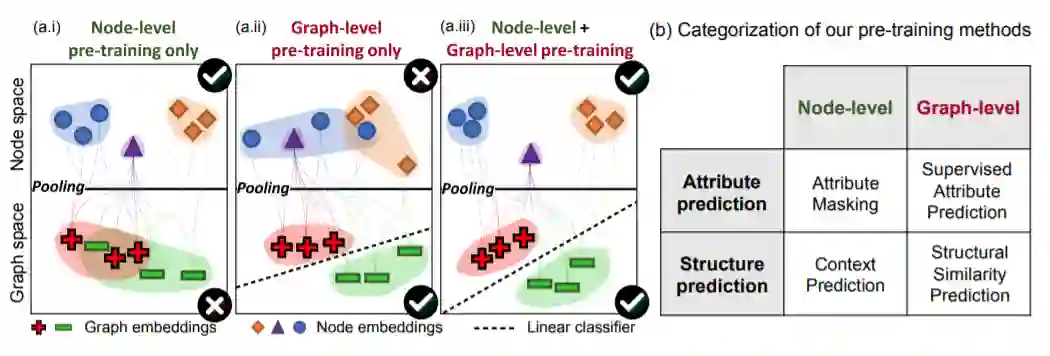
图1
论文接下来分别介绍了节点层级和图层级的预训练。
对于GNN的节点级预训练,我们的方法是使用易于访问的未标记数据来捕获图中的特定领域的知识/规律。 在这里,我们提出了两种自我监督的方法,上下文预测和属性屏蔽。
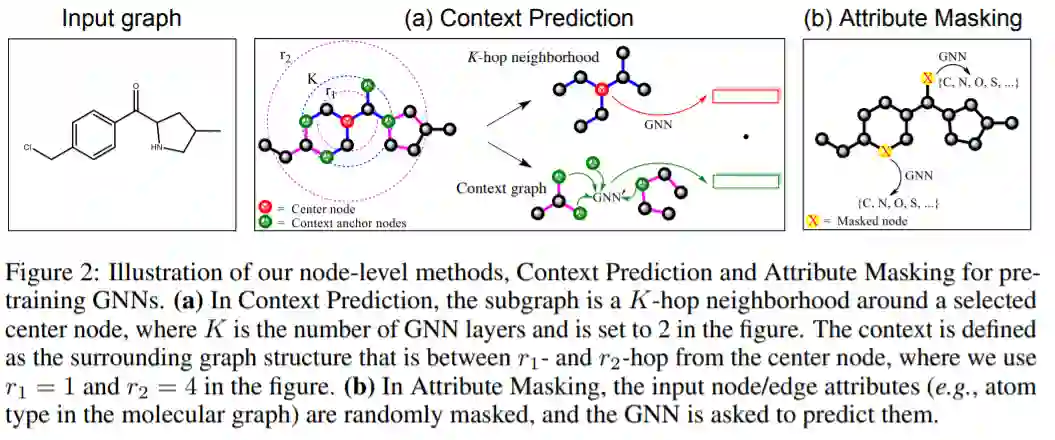
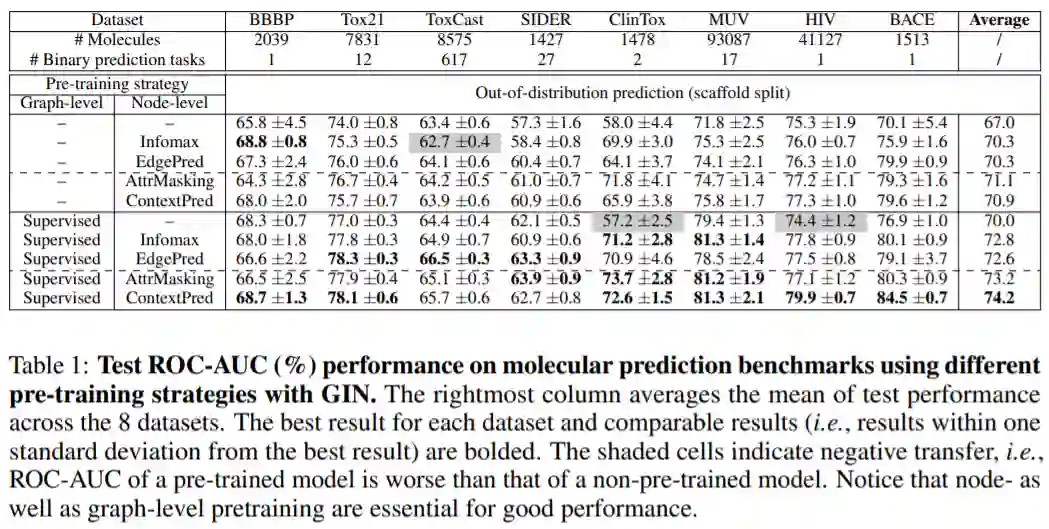
表1
在GIN模型上,用不同的预训练模型,测试其ROC-AUC值。可以看到同时在图层级和节点层级上预训练的模型表现是最好的。
2
GPT-GNN: Generative Pre-Training of Graph Neural Networks

这篇论文提出了GPT-GNN框架,通过生成预训练来初始化GNN。GPT-GNN引入了自监督的属性图生成任务来预训练GNN,以便它可以捕获图的结构和语义属性。
我们将图生成分为两部分:
1.属性生成
2.边生成
通过对这两个部分建模,在生成过程中,GPT-GNN捕获了节点属性和图结构之间的固有依赖。
在百万级数据上进行的综合性实验证明,GPT-GNN比其他先进的GNN模型更有效,在下流任务上可以达到9.1%的效果。
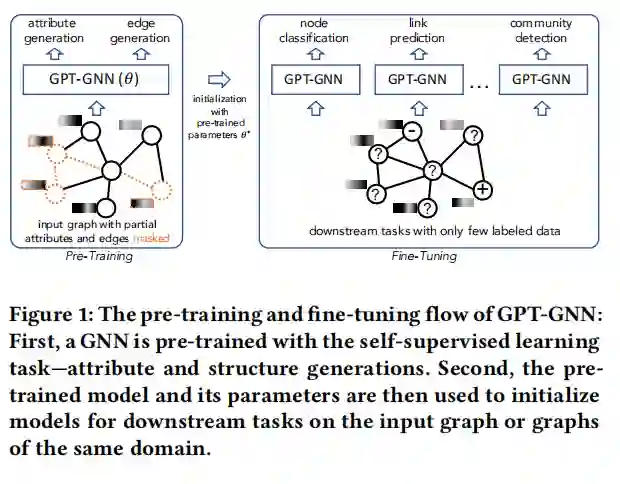
图2
图2展示了GPT-GNN的预训练和微调流。首先,GNN可以通过自监督学习任务进行预训练,生成属性和边。然后,预训练的模型和他的参数可以被用来初始化模型。
为了同时捕获属性、结构信息,需要将节点的条件生成概率分解为特征生成和图结构生成。首先,通过已观测到的边来预测节点特征,然后,通过已观测到的边和预测的节点特征,预测剩下的边。
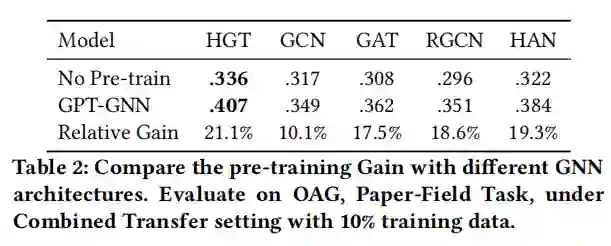
表2
将HGT,将GCN,GAT,RGCN,HAN作为基础模型,发现在经过预训练之后,他们的表现会更好。能达到10%以上的提升。
3
Learning to Pre-train Graph Neural Networks

这篇论文的作者来自北京邮电大学、腾讯、新加坡管理大学和鹏城实验室的。论文非常有趣,是讲怎样学习预训练GNN的。
传统的GNN预训练通常是遵循两步范式的:
1.在大量的无标签数据上进行预训练
2.在标签数据上进行微调
由于两步的目标不同,所以会存在一个偏差。针对于样的问题。
为了减少这个偏差,论文中提出了L2P-GNN,一个自监督的预训练策略。L2P-GNN的中心思想是,在预训练的过程中进行微调,使得模型可以快速适应新任务。这样学习到的初始化不仅对节点之间的局部连通性进行了编码和调整,还能泛化到图的不同子结构。
为了将局部和全局的信息考虑在内,L2P-GNN设计了一个在图层级和节点层级的双重适应机制。
最终在数据集上的实验表明,L2P-GNN是有效的。
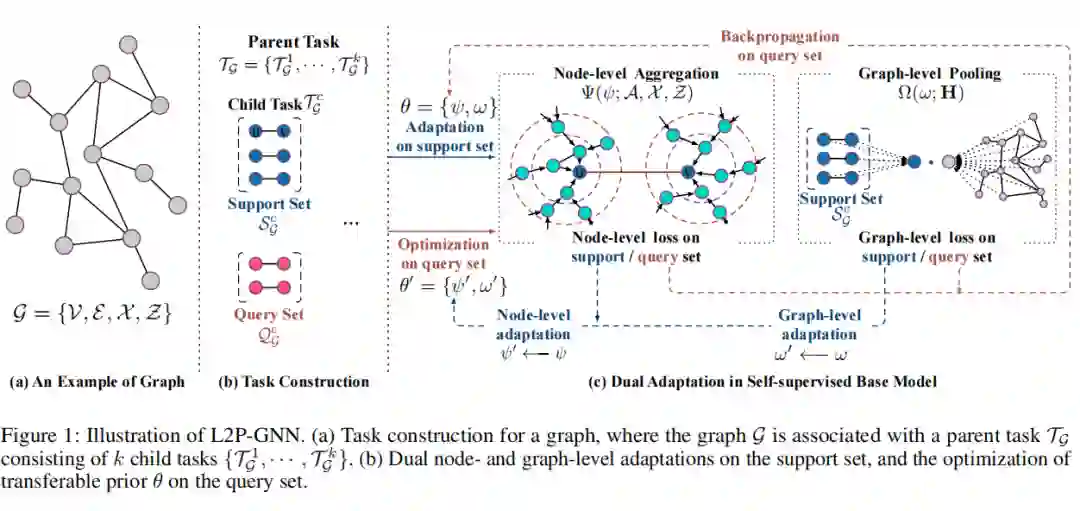
图3
L2P-GNN的模型框架如图3所示。其中:
(a)表示输入的图,这里以输入一个图为例
(b)为任务的构建过程
(c)为双重适应自监督模型,用于学习图上的信息
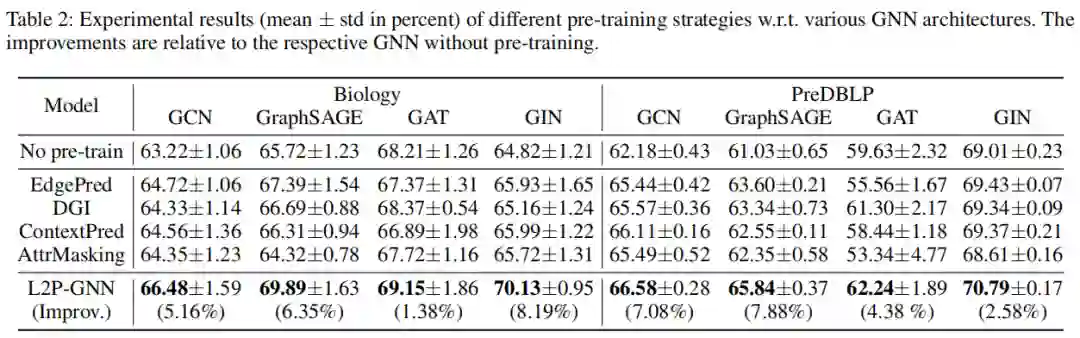
表3
将L2P-GNN模型和SOTA预训练基线作比较。我们发现:
1.总体来讲,L2P-GNN模型可以获得更好的表现。在两个数据集上L2P-GNN模型可以获得高达6.27%、3.95%的提升。
2.此外,使用大量未标注数据对 GNN 进行预训练显然对下游任务有所帮助。因为相比于在两个数据集上未经过预训练的模型,L2P-GNN 分别带来了 8.19% 和 7.88% 的增益。
3.研究者还注意到,一些基线(即使用 EdgePred 和 AttrMasking 策略的 GAT 模型)在下游任务中的性能提升极为有限,并在下游任务上产生了负迁移。原因可能是这些策略学习的信息与下游任务无关,因而不利于预训练 GNN 的泛化。这一发现证实了先前的观察结果,即负迁移会限制预训练模型的使用性和可靠性。
4
Pre-Training Graph Neural Networks for Cold-Start Users and Items Representation

推荐系统可以根据用户的历史行为和兴趣来预测用户未来行为和兴趣,因此大量用户行为数据就成为推荐系统的重要组成部分和先决条件。
但是在推荐应用的开始阶段往往是没有大量数据的。如何在这种情况下设计让用户满意的推荐系统,就是冷启动问题。
尽管研究人员已经通过结合高阶协作信号来解决该问题,但是用户冷启动和物品冷启动问题并未得到明显优化。
而这篇论文提出,在应用GNN模型之前,先对其进行预训练。但是预训练的目的并不是为了做推荐,而是交互性模拟来自用户/项目的冷启动场景,并将嵌入重建作为任务,从而可以直接提高嵌入质量,从而适应新的冷启动用户/项目。
为了减少冷启动邻居的影响,加入了自监督的元聚集器来增强图卷积的聚集能力.
在三个公开推荐数据集上的实验证明我们的预训练GNN相比之前的GNN模型是有效的。
模型图如图4所示
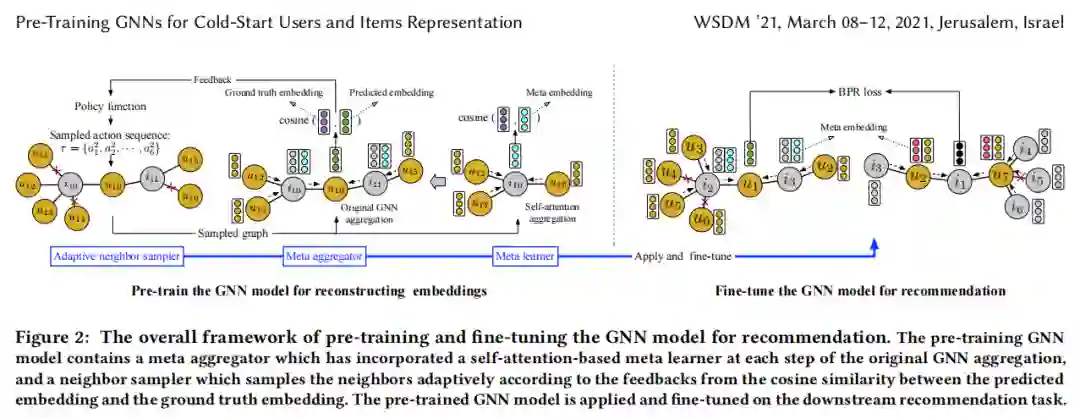
图4
图中为预训练和微调GNN的总体框架。预训练GNN模型在每一个原始GNN模型聚集步骤中,加入了自监督元学习器的元聚集器,以及一个邻居取样器(根据来自预测嵌入和地面真实嵌入之间的余弦相似度的反馈,自适应地对邻居进行采样)。预训练好的GNN模型可以应用于微调下游的任务。
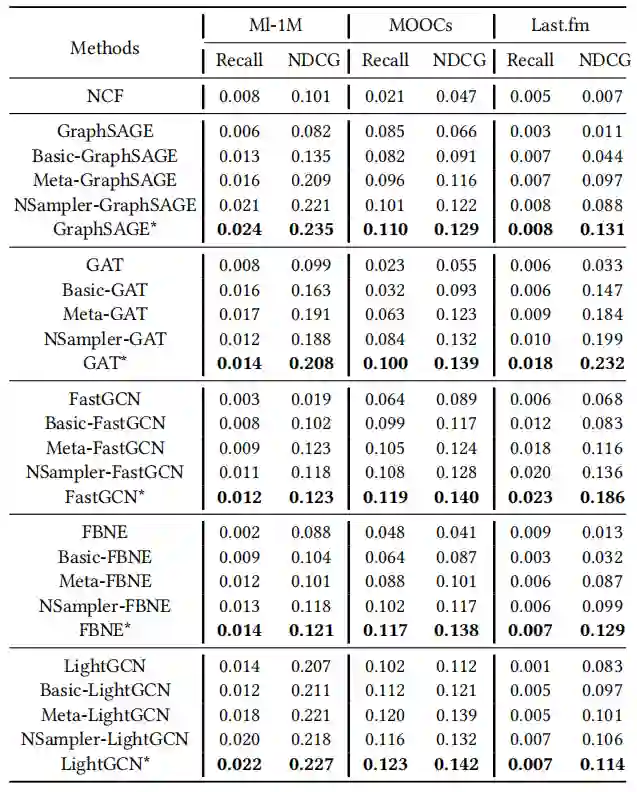
表4
从表4可以看到总体的推荐表现。可以看到经过预训练之后的GNN模型表现相比之前提高了0.4%-3.5%。可以证明预训练GNN模型是有效的。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“GNN4” 就可以获取《图神经网络GNN预训练技术进展概述》专知下载链接






