亚马逊最新《知识增强预训练语言模型》,全面综述知识嵌入预训练模型以及在NLU与NLG应用
【导读】预训练语言模型是当前的研究热点之一。来自AWS AI相关研究人员发布了关于《知识增强预训练语言模型》综述论文,值的关注!

摘要
预训练语言模型(Pretrained Language Models, PLM)通过在大规模文本语料库上学习信息语境化表示,建立了一种新的范式。这种新的范式已经彻底改变了整个自然语言处理领域,并为各种NLP任务设置了新的最先进的性能。然而,尽管PLM可以从训练语料库中存储一定的知识/事实,但它们的知识意识还远远不能令人满意。为了解决这个问题,将知识集成到PLM中已经成为一个非常活跃的研究领域,并且已经开发了各种各样的方法。在本文中,我们对这一新兴和快速发展的领域-知识增强的预训练语言模型(KE-PLMs)提供了一个全面的文献综述。我们引入三种分类法来对现有工作进行分类。此外,我们还调研了各种NLU和NLG应用,在这些应用上,KE-PLM表现出了优于普通PLM的性能。最后,讨论了KE-PLMs面临的挑战和未来的研究方向。
引言
近年来,大规模预训练语言模型(大规模预训练语言模型,简称PLM)给自然语言处理领域带来了革命性的变化。预先训练的模型如BERT [16], RoBERTa [50], GPT2/3[68][7]和T5[69]获得了巨大的成功,极大地提升了各种NLP应用的最先进性能[67]。前训练在NLP中的广泛成功也启发了自我监督前训练在其他领域的应用,如图表示学习[30][31]和推荐系统[81][98]。对大量文本数据的训练也使这些plm能够记住训练语料库中包含的某些事实和知识。最近的研究表明,这些经过训练的语言模型可以拥有相当数量的词汇知识[48][92]和事实知识[63][71][95]。然而,进一步的研究发现,PLM在知识意识方面也存在以下局限性:
对于NLU来说,最近的研究发现PLM倾向于依赖于表面信号/统计线索[62][55][58],并且很容易被否定的信息(例如,“Birds can [MASK]”vs .“Birds cannot [MASK]”)和错误启动的探针[35]所愚弄。此外,已有研究发现,PLM在推理任务中往往会失败[84]。
对于NLG,尽管PLM能够生成语法正确的句子,但生成的文本可能不符合逻辑或不合理。例如,在[46]中提到,给定一组概念{dog, frisbee, catch, throw}, GPT2生成“a dog throw a frisbee at a football player”和T5生成“dog catch a frisbee and throw it to a dog”,这两者都不符合人类的常识。
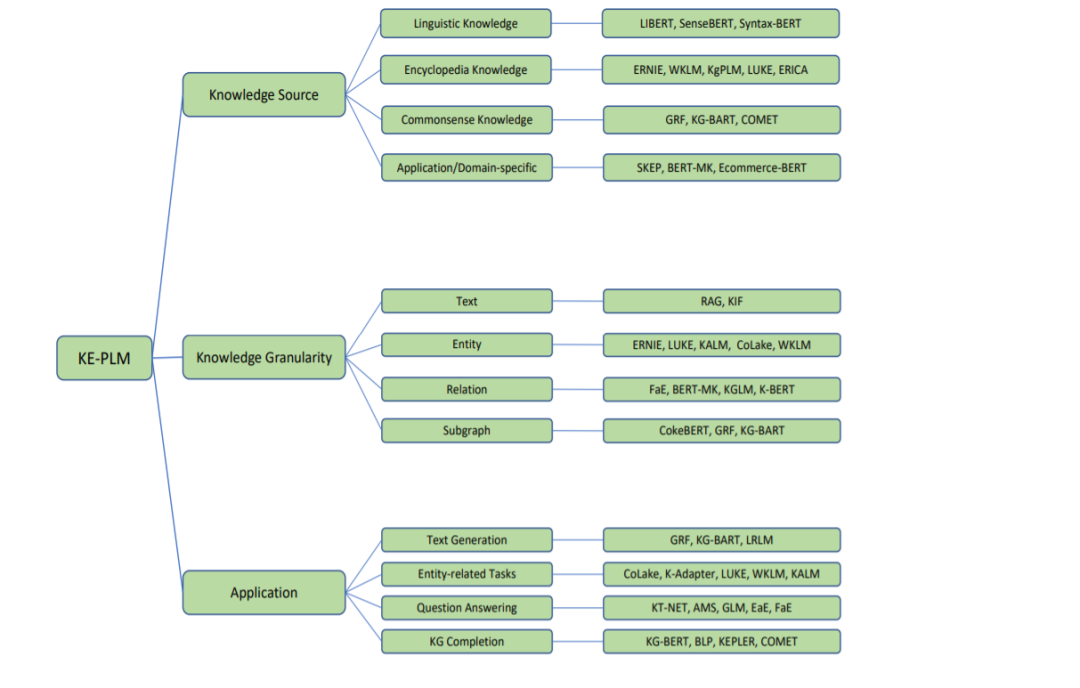
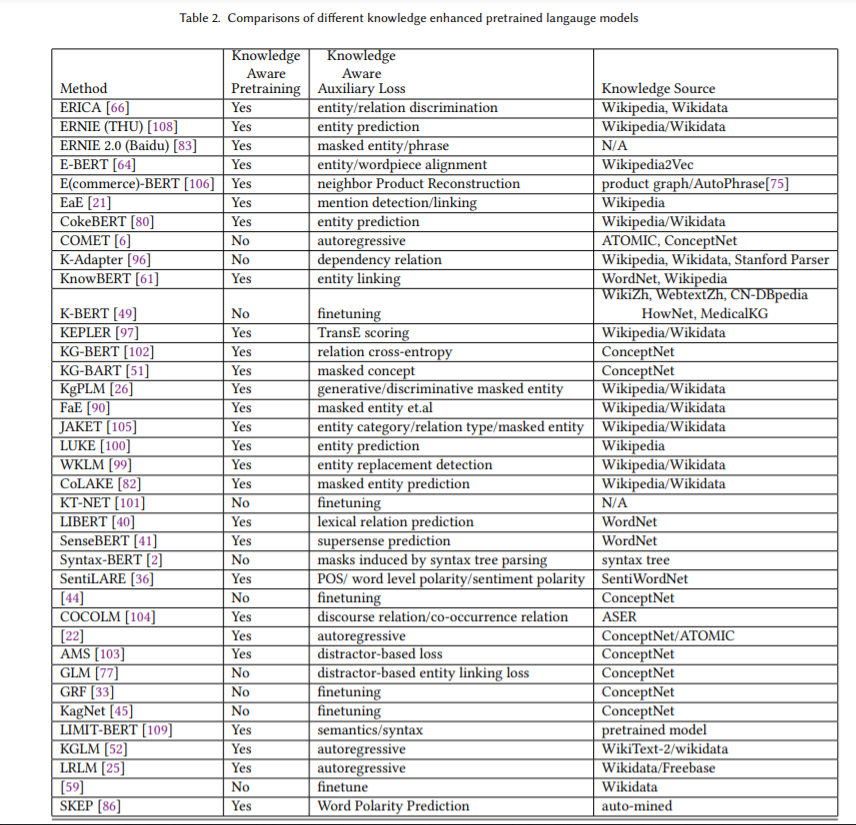
这些观察结果促使人们设计更有知识意识的预训练模型。最近,越来越多的研究致力于明确地将知识纳入PLMs[100][108][61][90][96][49][33]。他们利用百科知识、常识知识和语言知识等多种来源,采用不同的注入策略。这种知识集成机制成功地增强了现有PLM的知识意识,提高了包括但不限于实体输入[100]、问题回答[101][45]、故事生成[22]和知识图完成[102]在内的各种任务的性能。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“KEPLM” 就可以获取《亚马逊最新《知识增强预训练语言模型》,全面综述知识嵌入预训练模型以及在NLU与NLG应用》专知下载链接




