

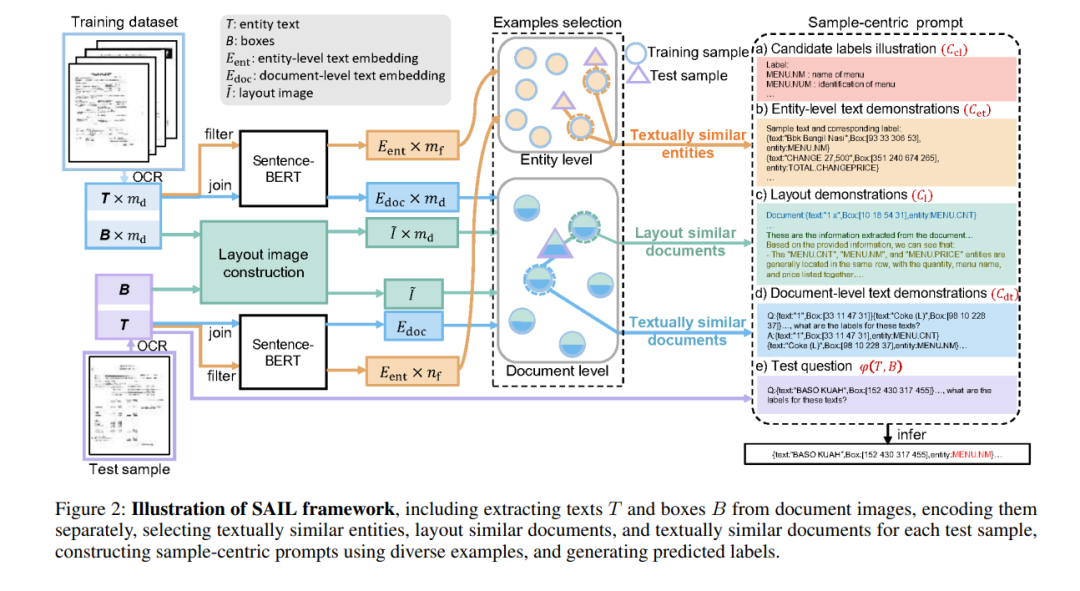
文档信息提取(DIE)旨在从视觉丰富文档(VRDs)中提取结构化信息。以往的全训练方法已展示出强大的性能,但在面对未见数据时可能存在泛化困难。相比之下,无训练方法利用强大的预训练模型,如大语言模型(LLMs),通过少量示例处理各种下游任务。然而,无训练方法在文档信息提取(DIE)中面临两个主要挑战:(1)理解VRD中布局与文本元素之间的复杂关系;(2)为预训练模型提供准确的指导。为解决这些挑战,我们提出了面向样本的上下文学习(SAIL)方法。SAIL引入了细粒度的实体级文本相似度,促进了LLMs的深度文本分析,并结合了布局相似度,增强了对VRD中布局的分析。此外,SAIL为各种面向样本的示例制定了统一的上下文学习(ICL)提示模板,使得为每个示例提供定制化的提示,能够为预训练模型提供精确的指导。我们在FUNSD、CORD和SROIE基准数据集上进行了广泛实验,使用了多种基础模型(例如,LLMs),结果表明,我们的SAIL方法在无训练基准方法中表现出色,甚至接近全训练方法,展示了我们方法的优越性和泛化能力。 代码 — https://github.com/sky-goldfish/SAIL
成为VIP会员查看完整内容
相关内容
Arxiv
0+阅读 · 12月21日
Arxiv
181+阅读 · 2023年4月7日
Arxiv
20+阅读 · 2023年3月21日

相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 12月21日
Arxiv
181+阅读 · 2023年4月7日
Arxiv
20+阅读 · 2023年3月21日