

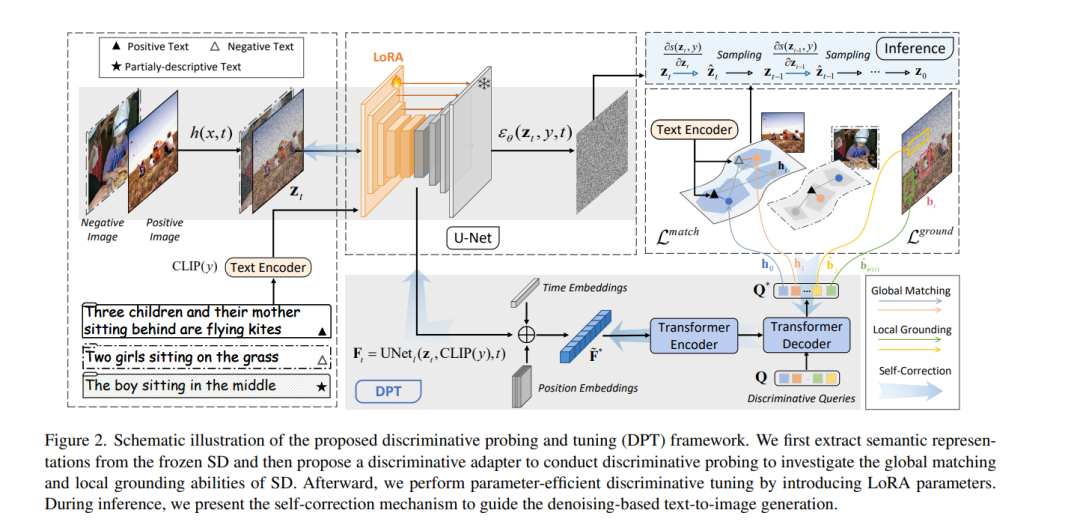
尽管文本到图像生成(T2I)技术取得了进展,但先前的方法常常面临文本-图像不对齐问题,例如生成图像中的关系混淆。现有的解决方案包括为了更好的组合理解而操纵跨注意力,或集成大型语言模型以改善布局规划。然而,T2I模型固有的对齐能力仍然不足。通过回顾生成模型和判别模型之间的联系,我们认为T2I模型的判别能力可能反映了它们在生成过程中的文本-图像对齐熟练程度。基于这一点,我们提倡增强T2I模型的判别能力,以实现更精确的文本到图像对齐生成。我们在T2I模型上构建了一个判别适配器,用以探测它们在两个代表性任务上的判别能力,并利用判别性微调来改善它们的文本-图像对齐。作为判别适配器的一个额外好处,自我修正机制可以在推理过程中利用判别梯度更好地将生成的图像与文本提示对齐。在包括分布内和分布外场景在内的三个基准数据集上进行的全面评估证明了我们方法的优越生成性能。同时,与其他生成模型相比,它在两个判别任务上达到了最先进的判别性能。代码可在 https://dpt-t2i.github.io/ 获取。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日