

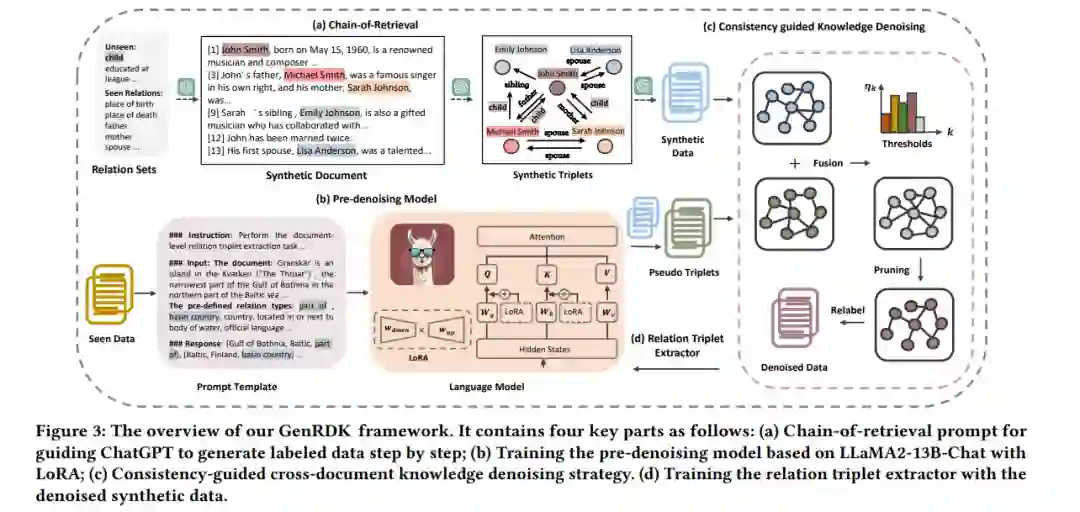
文档级关系三元组提取(DocRTE)是信息系统中的一项基础任务,旨在从文档中同时提取具有语义关系的实体。现有的方法在很大程度上依赖于大量的完全标记数据。然而,为新兴关系收集和注释数据是耗时且劳动密集的。最近的先进大型语言模型(LLM),如ChatGPT和LLaMA,展示了令人印象深刻的长文本生成能力,激发了我们探索一种获取带有新关系的自动标记文档的替代方法。在本文中,我们提出了一种零样本文档级关系三元组提取(ZeroDocRTE)框架,该框架通过从LLM中检索和去噪知识来生成标记数据,称为GenRDK。具体来说,我们提出了一种链式检索提示,以引导ChatGPT逐步生成带标签的长文本数据。为了提高合成数据的质量,我们提出了一种基于跨文档知识一致性的去噪策略。利用我们的去噪合成数据,我们继续对LLaMA2-13B-Chat进行微调,以提取文档级关系三元组。我们在两个公共数据集上进行了零样本文档级关系和三元组提取的实验。实验结果表明,我们的GenRDK框架胜过了强基线方法。
成为VIP会员查看完整内容
相关内容
Arxiv
225+阅读 · 2023年4月7日
Arxiv
20+阅读 · 2023年3月21日
相关VIP内容
相关资讯
相关论文
Arxiv
225+阅读 · 2023年4月7日
Arxiv
20+阅读 · 2023年3月21日