

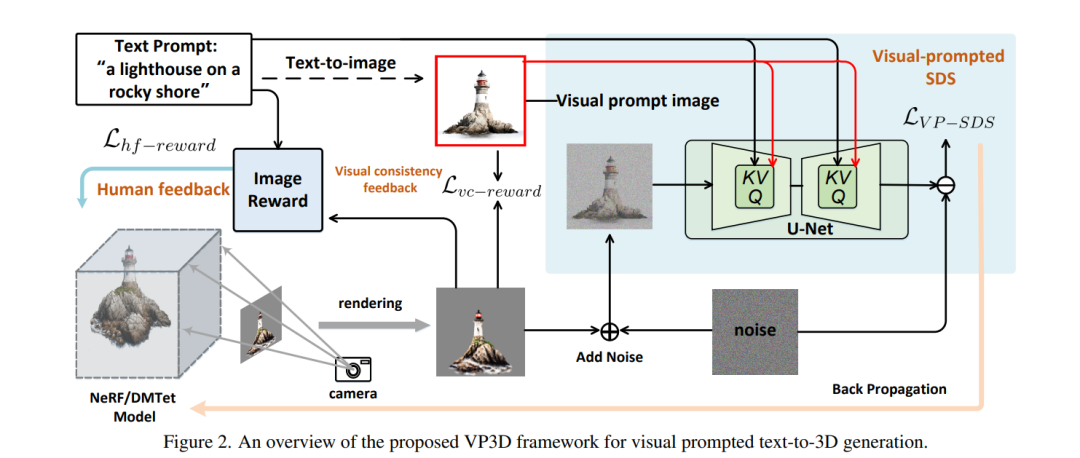
最近在文本到三维生成领域的创新引入了评分蒸馏采样(SDS),它通过直接从二维扩散模型中提取先验知识,实现了隐式三维模型(NeRF)的零样本学习。然而,当前基于SDS的模型仍然难以处理复杂的文本提示,并且通常会生成形变的三维模型,这些模型具有不真实的纹理或视图间不一致问题。在这项工作中,我们引入了一种新颖的视觉提示引导的文本到三维扩散模型(VP3D),它明确地释放了二维视觉提示中的视觉外观知识,以促进文本到三维的生成。VP3D不仅仅使用文本提示对SDS进行监督,而是首先利用二维扩散模型从输入文本生成高质量图像,随后作为视觉提示加强SDS优化,明确提供视觉外观。同时,我们将SDS优化与额外的可微奖励函数相结合,该函数鼓励渲染的三维模型图像在视觉上更好地与二维视觉提示对齐,并与文本提示在语义上匹配。通过广泛的实验,我们展示了我们VP3D中的二维视觉提示显著地简化了三维模型视觉外观的学习,因而导致了更高的视觉保真度和更详细的纹理。当用给定的参考图像替换自生成的视觉提示时,VP3D能够触发一个新的风格化文本到三维生成任务,这也是十分吸引人的。我们的项目页面可在 https://vp3d-cvpr24.github.io 上查看。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日

相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日