
【导读】三维物体检测是自动驾驶感知系统的重要组成部分,它可以智能预测自动驾驶车辆附近关键三维物体的位置、大小和类别。香港中文大学发布了最新《自动驾驶三维物体检测》综述论文,32页pdf涵盖367篇文献全面概述基于激光雷达、基于相机和多模态的物体检测进展,非常值得关注!

近年来,自动驾驶因其具有减轻驾驶员负担和提高驾驶安全性的潜力而受到越来越多的关注。在现代自动驾驶流程中,感知系统是不可或缺的组成部分,其目的是准确估计周围环境的状态,为预测和规划提供可靠的观测数据。三维物体检测是感知系统的重要组成部分,它可以智能预测自动驾驶车辆附近关键三维物体的位置、大小和类别。本文综述了自动驾驶三维物体检测的研究进展。首先,我们介绍了三维物体检测的背景,并讨论了这项任务所面临的挑战。其次,从模型和传感器输入等方面全面综述了三维物体检测的研究进展,包括基于激光雷达、基于相机和多模态的检测方法。我们还对每一类方法的潜力和挑战进行了深入分析。此外,我们还系统地研究了三维物体检测在驾驶系统中的应用。最后,对三维物体检测方法进行了性能分析,并进一步总结了近年来的研究趋势,展望了该领域的未来发展方向。
项目地址:https://github.com/PointsCoder/Awesome-3D-Object-Detection-for-Autonomous-Driving
引言
**近年来,自动驾驶技术取得了飞速发展,其目标是让车辆智能感知周围环境,无需或无需人为努力就能安全地行驶。自动驾驶技术被广泛应用于许多场景,包括自动驾驶卡车、机器人出租车、配送机器人等,能够减少人为失误,提高道路安全。汽车感知是自动驾驶系统的核心组成部分,通过感知输入帮助自动驾驶车辆了解周围环境。感知系统一般采用摄像机采集的多模态数据图像、激光雷达扫描的点云、高清地图等)作为输入,预测道路关键要素的几何和语义信息。高质量的感知结果为后续的轨迹预测和路径规划提供可靠的观测数据。
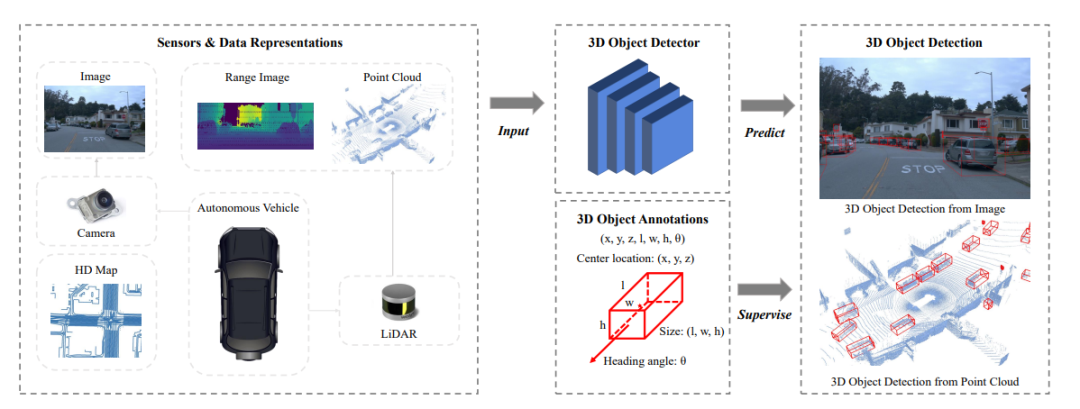
自动驾驶场景中的3D对象检测示例
为了全面了解驾驶环境,感知系统可以涉及到很多视觉任务,如目标检测与跟踪、车道检测、语义和实例分割等。在这些感知任务中,三维物体检测是汽车感知系统中不可或缺的任务之一。三维物体检测的目的是预测关键物体在三维空间中的位置、大小和类别,如汽车、行人、骑自行车的人等。与仅在图像上生成二维边界框而忽略目标与自身距离信息的目标检测相比,三维物体检测关注的是目标在真实三维坐标系中的定位与识别。三维物体检测在现实坐标中预测的几何信息可以直接用于测量自驾车与关键物体之间的距离,从而进一步帮助规划驾驶路线和避免碰撞。
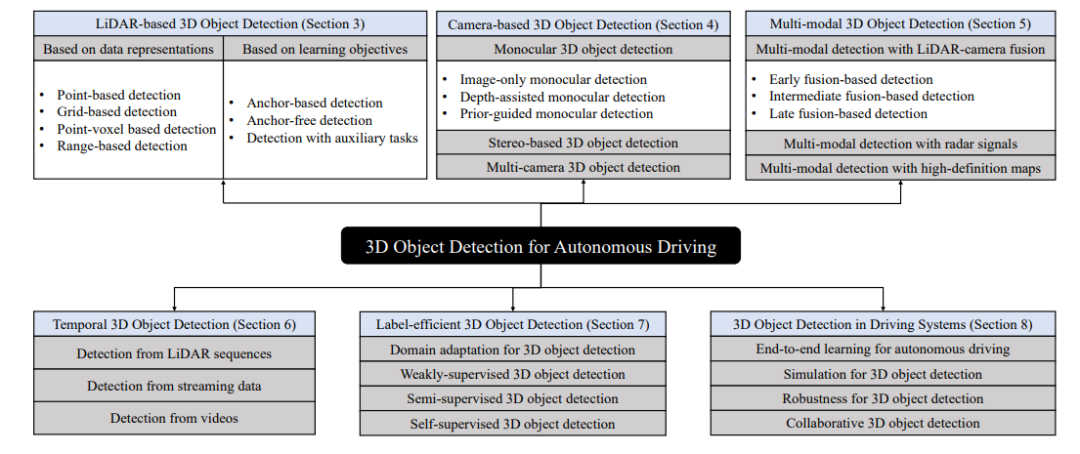
自动驾驶三维物体检测的层次分类法
随着计算机视觉和机器人技术中深度学习技术的发展,三维物体检测方法得到了迅速的发展。这些方法一直试图从特定的角度来解决3D物体检测问题,如从特定的感官类型检测、数据表示等,但缺乏与其他类别方法的系统比较。因此,综合分析所有类型的三维物体检测方法的优缺点是可取的,可以为研究社区提供一些有趣的发现。为此,我们提出对自动驾驶应用中的三维物体检测方法进行全面的综述,并对不同类型的方法进行深入的分析和系统的比较。与现有研究相比[5,139,215],本文广泛涵盖了这一领域的最新进展,如从距离图像中检测三维目标、自/半/弱监督三维目标检测、端到端驾驶系统中的三维检测等。以往的研究只关注点云[88,73,338]、单眼图像[297,165]和多模态输入[284]的检测,而本文系统地研究了所有感官类型和大多数应用场景下的三维物体检测方法。这项工作的主要贡献可归纳如下:
-
本文从不同的角度对三维物体检测方法进行了全面的综述,包括来自不同传感器输入的检测(基于激光雷达、基于相机和多模态检测)、来自时间序列的检测、标签高效检测,以及三维物体检测在驾驶系统中的应用。
-
我们从结构和层次上对三维物体检测方法进行了总结,并对这些方法进行了系统的分析,对不同类别的方法的潜力和挑战提出了有价值的见解。
-
我们对三维物体检测方法进行了全面的性能和速度分析,找出了多年来的研究趋势,并对未来的三维物体检测方向提出了有见地的看法。
本文的结构安排如下。首先,我们在第2节中介绍了三维物体检测的问题定义、数据集和评估指标。然后,我们回顾和分析了基于LiDAR传感器(第3节)、摄像头(第4节)和多感官输入融合(第5节)的三维物体检测方法。接下来,我们介绍了第6节中利用时间数据的检测方法和第7节中使用较少的标签的检测方法。随后我们在第8节讨论了三维物体检测在驱动系统中的应用。最后,在第9部分,我们对三维物体检测的速度和性能进行了分析,并对研究趋势进行了探讨,并对未来的发展方向进行了展望。图1显示了一个层次结构的分类法。我们还在这里提供了一个不断更新的项目页面。
基于激光雷达的三维物体检测
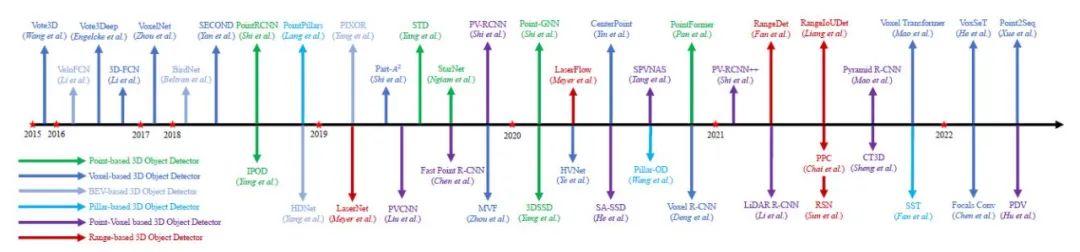
基于激光雷达的三维物体检测方法概述
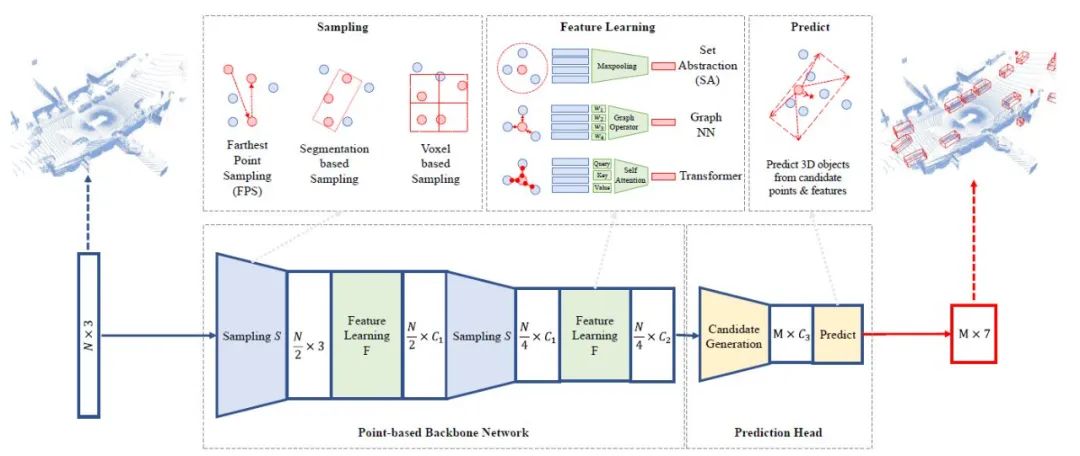
一种通用的基于点的检测框架包括基于点的骨干网和预测头。基于点的主干由多个块组成,用于点云采样和特征学习,预测头直接从候选点估计出三维边界框。
基于相机的三维物体检测
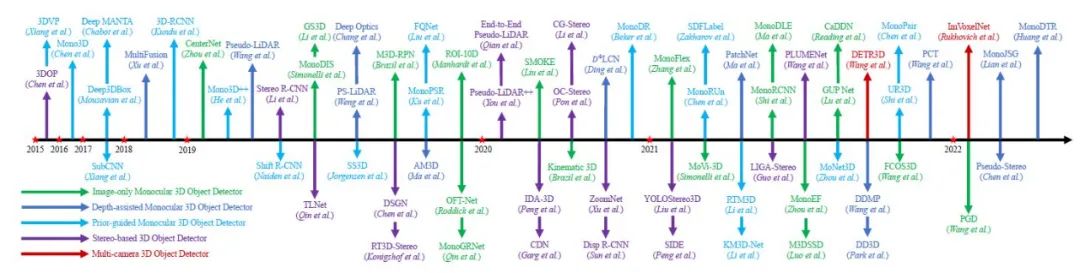
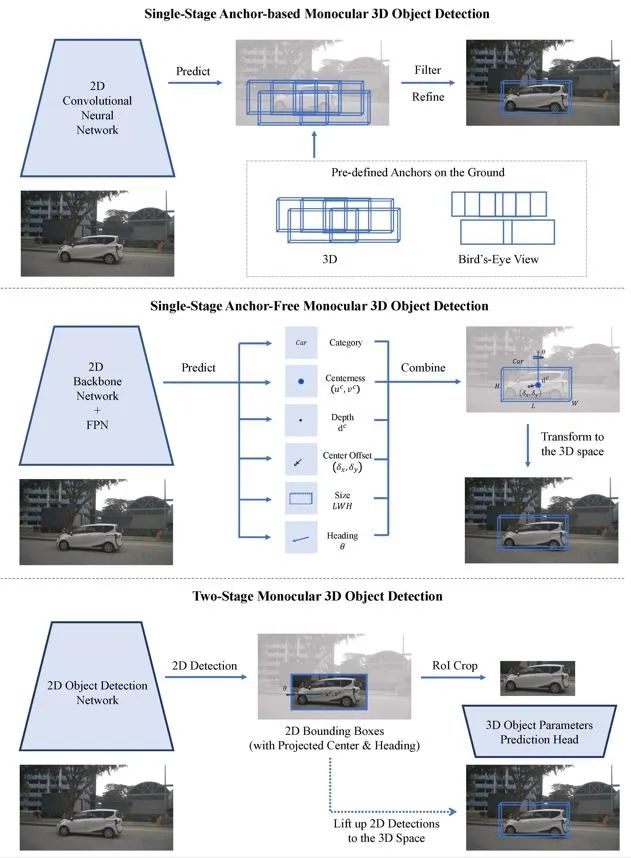
单阶段锚定方法利用图像特征和预定义的3D锚定框来预测三维物体参数。单阶段无锚方法直接从图像像素预测三维物体参数。两阶段检测方法首先由二维检测器生成二维包围盒,然后根据二维RoI特征预测三维物体参数,将二维检测提升到三维空间。
多模态三维物体检测
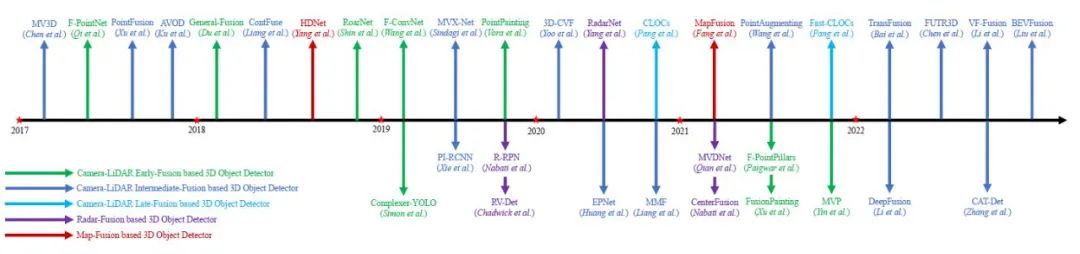
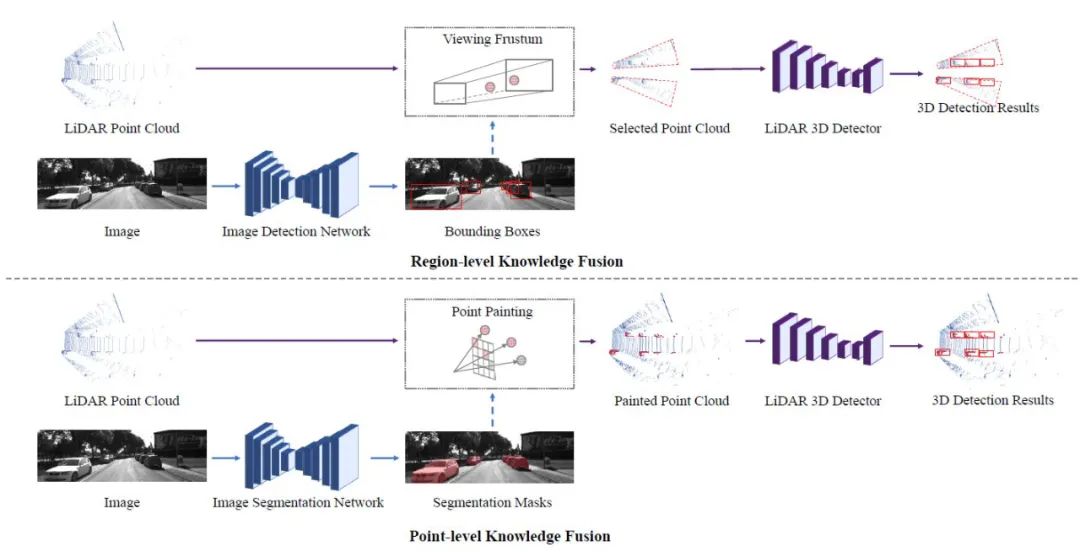
早期融合方法在点云特征通过基于激光雷达的三维物体检测器之前,利用图像信息进行增强。在区域知识融合中,首先对图像进行二维检测,生成二维边界框。然后将二维方框挤压到视锥中,选择合适的点云区域,用于后续的基于激光雷达的三维目标检测。在点级知识融合中,首先对图像进行语义分割,然后将分割结果从图像像素转移到点上,作为附加在每个点上的附加特征。最后将增强后的点云通过激光雷达探测器进行三维物体检测。


