本文是《第 14 届北约运筹与分析 (OR&A) 会议:新兴和颠覆性技术》上的重要文章,介绍了从手工兵棋推演到桌面兵棋推演,再到数字兵棋推演,到智能兵棋推演的整个开发过程,值得一读。
摘要
作者描述了他们在瑞士国防装备采购局科学和技术部(armasuisse Science + Technology)的技术前瞻研究计划,也称为 DEFTECH(DEfence Future TECHnologies,国防未来技术),应用各种兵棋推演相关方法的经验,以识别破坏性技术趋势,评估其在军事背景下的影响并向瑞士武装部队通报可能的机会和威胁。
这包括一个从 2017 年开始并仍在进行的迭代过程,其中不仅创建了一个开放平台,而且还举办了几次国际研讨会。应用的方法包括更高聚合级别的矩阵式兵棋推演、受北约破坏性技术评估游戏 (DTAG) “系统卡理念(Idea of System Cards)”启发的红队成就,以及讲故事的方法。
对技术的特别关注最终促进了一种名为“新技术战争”的战术桌面兵棋推演平台开发,该游戏可商用。作为一个平台构建的互联网组件允许感兴趣的利益相关者之间进行交互,这些利益相关者希望模拟其他技术或场景并将其提供给社区。集成多智能体模拟、决策支持、人工智能和视频游戏的数字化游戏正在开发中。
作者介绍了过去研究的结论,包括不同的设计理念、确定的优缺点、最佳实践、当前的发展和愿景。
1 引言&背景
你通常期望从一个关于技术预见的研究项目中得到的肯定是关于在给定的时间范围内可能出现的技术分析报告。根据你的考虑,那个时间范围可以是近的,也可以是远的。这似乎是一个合乎逻辑且直截了当的答案,而且确实如此。但是,请稍等片刻,问问自己:你是对技术本身感兴趣还是对它们将提供什么感兴趣?它们将如何影响你的作业方式以及它们可能代表哪些机会和威胁?在这个阶段,甚至更进一步,问问自己,你真正感兴趣的是机会、威胁,以及它们所代表的东西,还是它们代表你?这种差异并不是轶事,因为它意味着从更具描述性的可交付成果转变为与你个人产生共鸣的事物。实现这一目标的最佳方式是产生独特的体验,与你的感官互动,以便你可以在需要时参考它。
我们处于国防环境中,正常的预期交付成果将是一份专门针对技术领域的报告。因此,包括一些故事讲述在内的叙事工作可能是向读者传递经验的一种方式。不幸的是,这种体验可能只停留在情感层面。让人们玩弄技术可以实现的东西,并在给定的场景中体验他们决定的后果肯定会带来更多的见解。
然而,在之前还有一个额外的挑战:我们想要试验的要素还不存在。因此,我们必须模拟它们,而不是简单地测试它们。带着想法和感受而不是价值观,为了提供必要的数学模型来转向模拟世界。正是在这一刻,我想到了“游戏”。但是怎么做?用什么做?和谁一起?在哪个级别?多久?在不知情的情况下,我们打开了潘多拉魔盒,其中包含我们必须考虑构建游戏环境的可能性和替代方案。
这里报告的是一个原始的尝试,不仅展示了已完成的工作,还展示了在此过程中以一种或另一种方式参与的不同利益相关者的动机。过去,现在,将来;每个人都在我们今天的位置和明天的位置中发挥了重要作用。现在看起来很明显的要素在开始时并不是这样的;未来可以实现的目标肯定需要今天的奋斗。
2 Deftech兵棋推演项目
该项目是 armasuisse Science + Technology 技术前瞻研究计划的一部分,也称为 Deftech - 国防未来技术。该计划的任务是识别颠覆性技术趋势,评估其在军事背景下的影响,并向瑞士武装部队通报其可能的机遇和威胁。
该计划于 2013 年开始,由中央协调并由年度预算支持,以执行不同的项目。鉴于其特殊性,Deftech 的愿景是通过协同效应进行预测。多年来,在前瞻性方法、信息的表示和可视化、开源情报 (OSINT) 的利用、科幻小说的使用、最近侧重于使用技术的兵棋推演以及对社会接受(或不接受)双重用途技术应用的理解。
鉴于该计划的协作性质,大部分活动及其成果可在专用互联网平台 (https://deftech.ch) 上获得。
新技术的主要挑战之一在于评估其未来影响并创造洞察力,这对军事作战员和指挥官来说都是切实可行的,对军事规划人员和系统开发人员来说也是可行的。由于兵棋推演是基于人类互动的演习,因此当应用于技术环境时,它有助于在潜在军事用户定义的动态和有争议的作战环境中实现新兴技术。这允许探索潜在的技术实施及其影响。因此,技术分析是兵棋推演在国防环境中的主要应用之一。
这形成了认知兴趣以及我们选择的方法论方式的起点,这将在以下部分中进行描述。
3 技术型兵棋推演——第一次迭代
2017 年,我们首先为 2035 年的瑞士进行了一场技术兵棋推演。在这个框架中,我们专注于三个不同的子场景,它们描述了潜在但最典型的安全挑战。根据 armasuisse 的“DEFTECH 雷达”(https://deftech.ch/visualise) 描述的预选未来技术,在兵棋推演中提供给玩家,以便他们可以在行动过程中根据需要灵活使用。
游戏设计的灵感来自于 Engle 的矩阵游戏理念,因为它具有探索性的方法以及在设计和执行过程中的灵活性。在我们的案例中,我们开发了一个双边桌面研讨会游戏,每个回合都有计划周期,之后双方交替执行他们的行动。在每一个回合中,双方各有四名参与者,讨论了他们行动的预期效果,并描述了为此问题应用的技术,由主持人主持。基于该讨论,主持人为行动分配了成功概率。随后通过掷骰子来确定实际结果,以将随机效应整合到交互中并保持游戏继续进行。
根据我们的设计,游戏依据玩家的决定、技术应用、讨论的论点和确定的结果创建了一个连续的叙事。分析的洞见来自于叙事本身、分析者的观察和玩家在对方不断的对抗和反制下讨论并努力创造效果的投入。此外,记录在案的叙述、分析师的笔记和最具争议的话题为后续研究提供了各种小插曲和假设。
除了这些结果之外,我们还发现了我们设计的一些挑战和缺点:首先,一般来说,兵棋推演提供了探索性见解,但由于开放的人机交互,以逃避可复制性为代价。更重要的是,应用技术的物化和与系统的集成构成了主要挑战,尤其是高水平的集成。为了减轻赤字,我们改编了北约颠覆性技术评估游戏 (DTAG) 中的元素,即所谓的“系统理念”(IoS)。
要创建IoS,首先要确定相关的未来技术。在第二步中,IoS卡牌是在一个研讨会上以给定的卡牌格式制作的,即将一种或多种选定技术与特定设备相结合,以运行新的潜在系统。此类 IoS 卡牌可以单独使用(即记录如何将相关技术应用于未来军事系统的见解和想法)或作为上述进一步技术兵棋推演的输入。我们于 2018 年在 armasuisse 的一个研讨会上执行了这一步骤,其中有几个工作组,最多 8 人,他们首先必须针对特定场景和要实现的目标提出一两张 IoS 卡牌。之后,两个小组配对并通过顺序结构化的讨论在红队努力中相互挑战他们的 IoS 卡牌。第三步,包括使用 IoS 卡牌进行的以技术为中心的兵棋推演及其相关分析,可以按照上述兵棋推演的描述执行。作为经典兵棋推演的替代方案,IoS 卡牌还可以用作游戏和计算机模拟的建模输入,以分析假设的未来操作环境中的基础技术,如下所述。

图 3-1:初始兵棋推演的游戏输入和执行
4 大转变:走向桌面兵棋推演
分析情况后,我们得出了一个显而易见的想法,即为了了解通过新技术集成实现的新产品影响,我们需要在它使用的级别上对其进行模拟。在我们的案例中,这意味着从战略层面转移到战术层面,其中必须为每个系统定义保护、杀伤力、机动性等参数的值。由于重点是理解这些系统提供的潜在破坏,我们必须具有轻松更改这些值的灵活性,以查看哪种组合将允许战术破坏或简单优势。
让我们考虑一下外骨骼的例子。愿景是装备一些步兵,使他们能够更快地移动,携带更多的重量(保护?弹药?),减少身体疲劳和受伤等。每个参数的大问题是“多少?”。使士兵能够携带 80 公斤而不是 50 公斤可能会提供优势,因为这可能意味着在特定情况下提供更多的保护或更多的弹药,但是专注于开发这样的系统是否足够重要?如果你可以携带 800 公斤而不是 80 公斤呢?
因此,为了激发交流和讨论,游戏必须能够轻松模拟这些变化并激发围绕它们的讨论。目标不是取胜,而是了解这些未来系统在给定战术场景中的优势和劣势。考虑到所有这些,桌面游戏的选择作为一种解决方案。
然而,为了在半天的过程中整合“游戏”部分,以便在模拟之前展示新系统,我们提出了以下先决条件:
(1) 游戏将围绕“蓝对红”场景。
(2) 用户手册应该足够简单,以便初学者能在 15 分钟内开始玩起。
(3) 一场比赛的持续时间必须最长为 60 分钟,以便在半天的时间内测试不同的选项。
(4) 游戏必须足够模块化,以允许引入新的未来技术/系统以及新场景,以适应不同利益相关者的兴趣和关注点。
在开发过程中,我们直接让瑞士武装部队,即军事理论和未来规划团队参与场景的定义以及未来技术的选择。我们一起确保我们从蓝方模拟的一切都尊重日内瓦战争公约。我们与专家验证了各种技术参数,以确保至少在第一次迭代中,我们将使用可以在未来几年内实现的价值。
考虑到这些要求,我们开始了将成为“新技术战争”(NTW)兵棋推演平台的旅程。
4.1 让它变得简单的挑战
大多数桌面兵棋推演,其中最成功的商业游戏,都针对最广泛的现实主义。由于精确的游戏机制和夸张的细节,您通常会以牺牲简单性为代价来实现这一点。很少看到最少少于 30 或 40 页的规则手册。对于我们的开发,我们必须颠倒范式,拿出一个 4 页的手册来尽可能准确地模拟,要尽可能简单。
因此,我们从需要开发一款能够以简单且非常灵活的方式采用当前瑞士学说的游戏原则开始。灵活,因为我们必须能够细化游戏的参数,才能清楚地看到对这些参数有影响的新技术效果,而且仅限于那些参数。

图 4-1:以新技术和系统为重点的桌游“新技术战争”的表示(标题“用明天的系统挑战今天的战术”总结了我们通过玩这个严肃的游戏试图强调的内容)
在这个阶段,桌子周围的所有玩家都应该开始更好地理解新系统可以在特定的战术情况下带来什么。比仅仅阅读有关它的报告要好得多。然而,还有一个悬而未决的问题我们还没有真正解决:作为防御者或攻击者,有没有一种特定的方法可以使用这个新系统来完成分配的任务?
要回答这个问题,您需要考虑在给定场景中使用新系统的所有可能方式。为此,您需要探索数字世界。
5 从桌面到数字
我们决定将兵棋推演转移到数字世界,而不是让它在屏幕上播放,而是为了获得关于如何以最佳方式使用新系统并挑战当前战术程序的更多见解。为了实现这一愿景,我们开始研究以下三个主题:
(1) 我们可以从生成蓝色与红色场景的所有可能结果中学到什么?
(2) 人类可以从与人工智能 (AI) 的兵棋推演中学到什么?我们该怎么做?
(3) 我们可以向人类玩家呈现什么类型的信息,以使人类加 AI 比单独的 AI 更好?你如何将信息呈现给玩家?
5.1 模拟所有的结果
在任何重要的兵棋推演中,可能的结果数量都非常庞大,以至于人类无法靠想象探索和分析它们。在专注于创造学习效果的训练兵棋推演中,无法探索整个结果空间可能无关紧要,但如果你将其用于开发新条令、测试作战概念和评估战术决策,则具有至关重要的意义。在这些情况下,你需要区分什么是可能的、合理的或可能的。
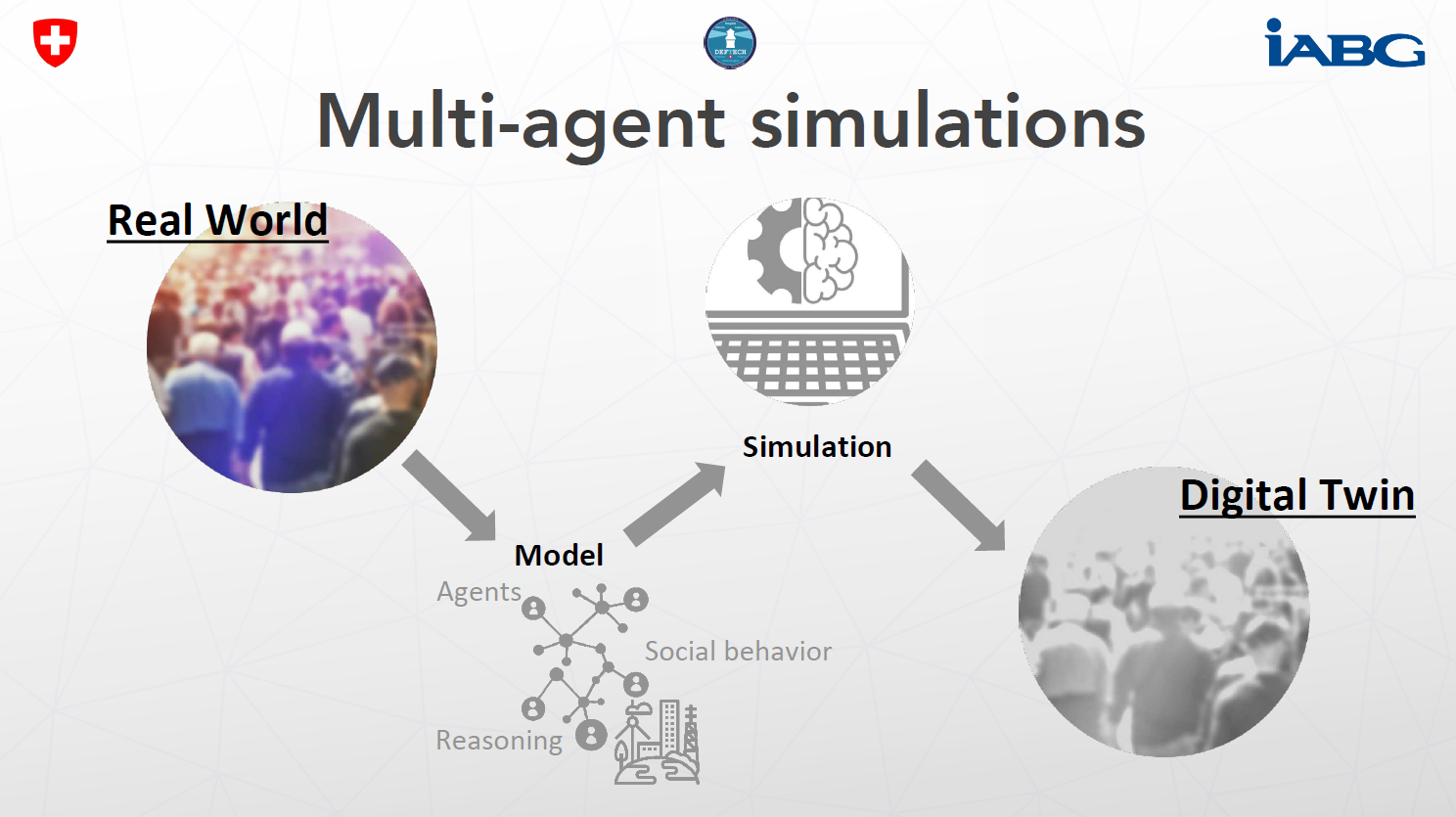
如何克服这一挑战?多亏了所谓的多智能体模拟。由于计算机比人类玩得更快,多智能体模拟可以系统地探索游戏结果的整个空间并确定最佳行动方案,从而产生合理的游戏结果。
5.1.1 多智能体模拟
桌面游戏等基于规则的系统可以直接转化为模拟:游戏规则和游戏环境(如地形和时间)被编码为计算机模型,逐渐向前成型,同时玩家互动的结果被记录为模拟世界的新状态。
多智能体模拟是城市、金融交易或军事行动等现实世界系统的数字双胞胎。为了构建多智能体模拟,首先生成合成种群。这是感兴趣系统的静态快照,包括个人的社会人口特征和行为以及社会技术环境。然后使用模拟技术根据行为规则和环境约束对合成种群进行动画处理。然后对模拟进行校准,以产生尽可能与感兴趣的真实世界变量在统计上无法区分的输出。这种经过验证的模拟不仅有助于探索游戏结果的范围,而且有助于诊断、预测和预见。
5.1.2 兵棋推演仿真
构建和运行我们的“新技术战争”(NTW)的多智能体模拟涉及以下步骤:
(1) 熟悉NTW:玩几轮NTW,学习游戏,了解规则。
(2) 构建NTW模型:根据规则手册、其他资料和对NTW的主观理解,包括选手、装备、规则、地形等。
(3) 将模型编码为多智能体模拟:编写软件来近似游戏“物理”,例如游戏板的数字化版本;描述由每个场景的系统、效应器和平台组成的软件包;为智能体定义任务目标,并为智能体配备强化学习行为。
(4) 模拟的验证:手动回合的游戏结果是手绘草图的(见图 5-1,左)。蓝色和红色虚线表示人类玩家在游戏中如何移动蓝色和红色军事单位。蓝色和红色的点表示射击位置。蓝色和红色实线表示火力线。然后将手绘草图数字化(图 5-1,右);运行了 1,000 次 NTW 模拟,结果以类似于手绘草图的格式自动绘制出来(图 5-2)。最后,通过为图像识别开发的机器学习算法将手动游戏结果与模拟游戏结果进行比较。
(5) 创建一个基础设施来运行实验:以探索游戏结果的空间并确定最佳行动方案。这包括产生 10,000 次模拟运行。
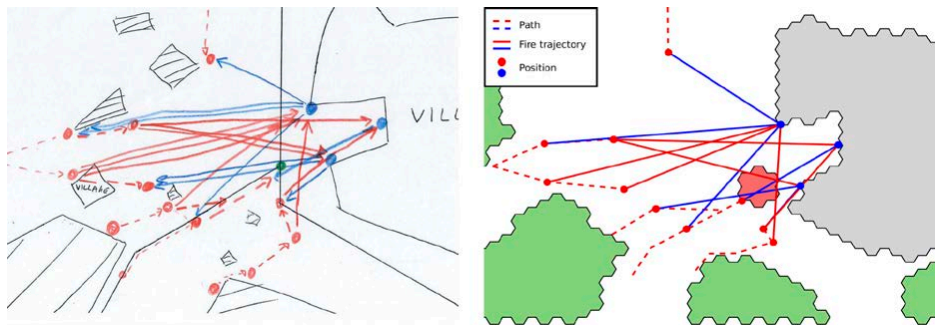
图 5-1:两个人玩游戏的手绘草图结果与数字化版本
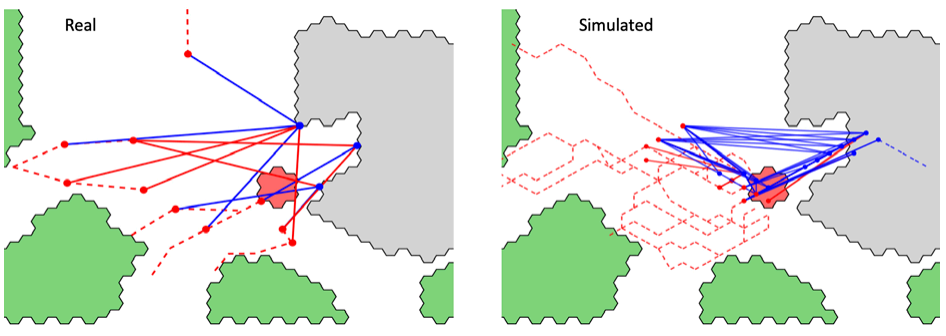
图 5-2:模拟游戏结果的可视化表示
5.1.3 结果分析
正如一开始所假设的那样,模拟可以探索合理的游戏结果的整个空间。我们并不打算重现特定的游戏结果,而是想知道为多智能体模拟提供动力的人工智能是否具有产生超越人类想象和游戏的合理结果所需的属性。首先,我们发现模拟确实产生了人类玩游戏的结果。这些在图 5-3 中的棕色簇中显示为红色十字。点云代表 1,000 个模拟游戏。其次,通过机器学习对游戏结果进行聚类,出现了三个不同的群体。这张图的意义就很明显了:模拟玩游戏并产生人类玩家没有想到的合理结果。这些都是蓝色和绿色集群中代表的所有游戏。
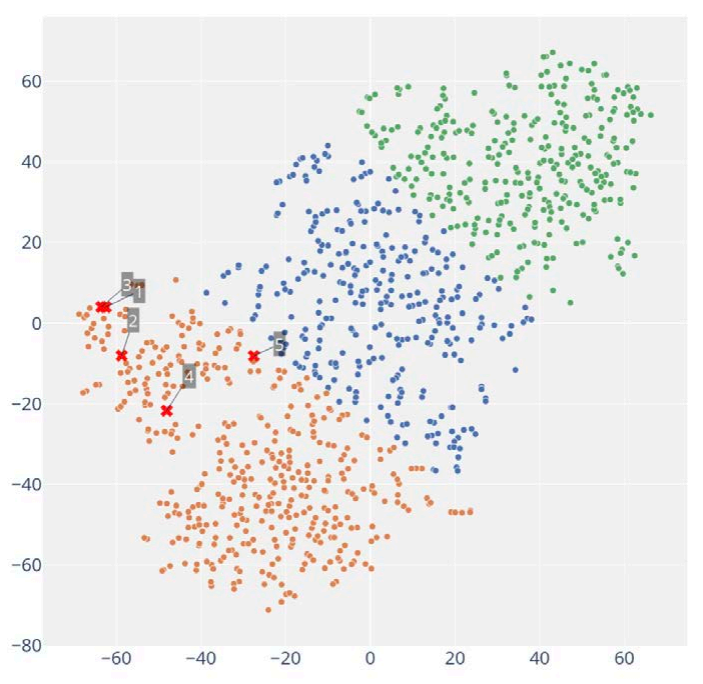
图 5-3:以点云表示的 1,000 个模拟游戏结果(游戏分为三个不同的组。现实世界的游戏,在点云左侧被描绘为红色十字,仅类似于棕色的游戏集群。游戏以蓝色和绿色的簇是模拟玩的游戏,但不是人类玩家想象的。点之间的距离代表游戏的两个数字表示之间的差异,如图 5-2 所示)
5.1.4 我们能学习到什么?
人类玩的游戏表明 BLUE 可以赢得大约 40% 的 NTW。相反,模拟表明,考虑到完整的结果集,而不仅仅是人类迄今为止所玩的结果,BLUE 获胜的机会要低得多,约为 3%。微调BLUE的强化学习参数后,BLUE的胜率没有超过10%。因此,模拟表明人类可能对获胜过于自信。这可以通过最初不知道玩游戏的其他可能性来解释。人类锁定在狭窄、熟悉的模式中;而模拟没有。模拟有助于确定最佳行动方案,而不会成为我们自己认知缺陷的牺牲品。
通过与数字冠军比赛来消除认知偏见是为 NTW 开发两种人工智能(一个玩 RED,另一个玩 BLUE)追求的目标。
5.2 使用人工智能增强作战战术
现代基于人工智能的智能体不仅在提供信息的能力上优于人类,而且在受控情况下做出决策的能力也优于人类。这意味着:在一个具有给定规则和行动的微型世界中,IT 系统不仅为决策提供背景,而且能够自行决定。如果可以将决策任务放入这样一个简化的世界(通常以游戏的形式),那么量身定制的 AI 通常可以帮助选择正确的动作。所描述的设置几乎包括所有战略游戏,例如国际象棋、围棋、将棋、Hex 等,AI 玩家可以毫不费力地击败人类世界冠军。
这项技术突破的核心在于通过数十亿次模拟训练人工智能的想法。每一次输赢都会被记录下来,每一步都会改进人工智能。不仅向决策者提供了一个模拟,而且一个 AI 会运行尽可能多的合理案例,并选择最有可能产生最佳结果的行动。经过足够多的迭代后,这个过程产生了在几乎所有战略游戏中超过人类大师能力的奇妙动作。
5.2.1 “新技术战争”模式下的兵棋推演
NTW 游戏是与军事专家密切合作设计的。它是一个简化但现实的模型,用于在各种现实世界的战争场景中进行决策。玩家面临典型的军事冲突情况,必须决定战略和战术以达到他的军事目标。当然,玩家可以在他的想象中运行有限数量的场景(模拟),并根据经验、可用数据和模拟采取最佳行动。然而,已经为许多其他游戏建立了训练 AI 智能体的方法,以达到超人的表现。 NTW 采用基于人工智能的方法,旨在学习军事战术和战略。一旦在游戏规则范围内达到令人满意的表现,游戏的结构可能会被扩展,以更准确地捕捉现实战争。示例包括添加未来的武器、详细说明其属性、合并具有不同目标的其他智能体等。
5.2.2 策略游戏的AI架构
就策略游戏 AI 玩家的开发而言,两种寻找最佳策略的方法可以被视为标准。我们将在下面详细描述这些方法。
首先是经典搜索,其中 AI 玩家尝试模拟尽可能多的游戏状态,然后选择最好的模拟。这种方法可以被描述为蛮力,因为它的最终目标是尝试所有可能的游戏状态并遵循导致胜利的决定。在实践中,穷举搜索通常是不可能的,因为即使是简单的游戏也会很快破坏最强计算机的能力。国际象棋中合理的游戏状态数量估计在 1040 左右,这个数字远远超出了计算机模拟的范围。因此,并非所有状态都被分析,但人工智能限制了足够数量的合理结果。搜索由两个关键参数量化。分支因子衡量对手玩家在当前决定下可以采取的合理行动的数量。搜索深度定义了模拟了多少后续动作。对于国际象棋,典型的分支因子约为 3,即对于每一步,通常考虑三个回复,并且深度最多为 80 步。一旦达到最大搜索宽度(由分支因子给出)和深度,定制的评估就会测量结果的质量。实现这种方法的常见 AI 算法是所谓的 AlphaBeta 搜索。值得一提的是,在商用智能手机上运行的实现 AlphaBeta 的公开国际象棋程序(例如 StockFish)比人类世界国际象棋冠军要强得多。
虽然 AlphaBeta 在分支因子和搜索深度不太大的情况下非常成功,但当这些指标增加时它很快就会失败。由于搜索练习的指数性质,即使增加一个单位的深度也会将计算机所需的容量乘以分支因子。因此,不能通过简单地选择更好的计算基础设施来解决这个问题。
在游戏中做出决策的第二种也是更现代的方法,明确地解决了 AlphaBeta 搜索的弱点,可以被描述为定向搜索。已经提出了各种架构,但基本设置如下。两个深度神经网络 (DNN) 用于决策。第一个是评估性的,因为它衡量质量。第二个 DNN 通过估计合理行为的概率来指导搜索。与 AlphaBeta 相比,此方法更关注决策的可能和相关后果,而不是尽可能多地检查。这种类型的搜索算法总结在首字母缩略词 MCTS(蒙特卡洛树搜索)下。近年来,MCTS 搜索算法在包括国际象棋、围棋、Chogi、Hex 在内的许多游戏中都优于 AlphaBeta 搜索,并构成了当前最先进的技术。
5.2.3 AI 在“新技术战争”中的应用
与国际象棋相比,NTW 的特点是分支因子明显更大,但同时搜索深度更小。分支因子大致反映了合理动作的数量。在 NTW 的情况下,可能有多种类型的动作,包括移动、攻击和响应动作。此外,在 NTW 的每一轮中,玩家的所有人物都可以行动,而国际象棋则只有一个人物移动。这个结果是一个通常从 50 到 100 的分支因子。另一方面,NTW 对每个场景都有一个有限的深度,标准深度是 12,这比国际象棋要小得多。
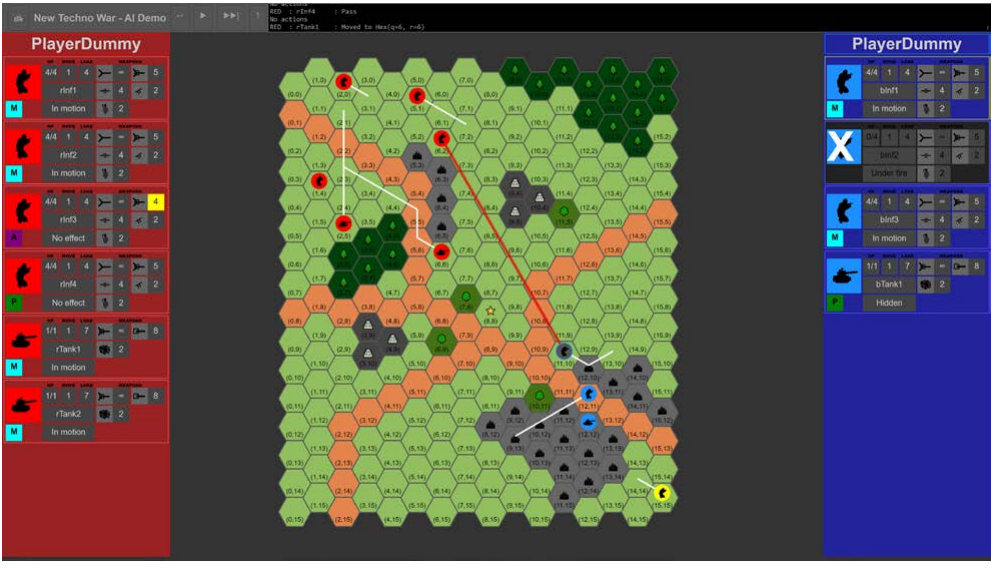
由于 AlphaBeta 或 MCTS 框架中的大型分支因子,现成的 AI 无法访问 NTW,但必须开发定制方法。该游戏的一个特殊之处在于响应动作的可能性,它打破了上述策略游戏的标准移动顺序。总而言之,NTW 需要一个 AI,它是为游戏的特定结构量身定制的,并且必须在定制的工作中进行开发。我们的团队目前在 PyTorch 开源 AI 框架(由 Facebook)中实现了一个实验性 AI。这些实验是用多个智能体进行的,以测量它们在 NTW 上的性能。智能体可以通过 Web 界面与人类对战(见图 5-4)。
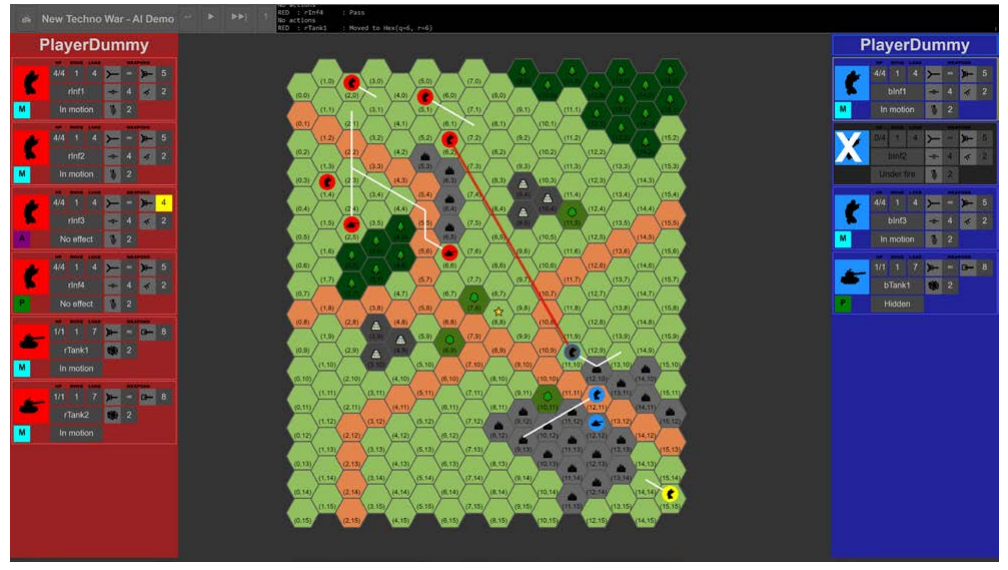
图 5-4:数字化NTW游戏的Web界面,允许人类玩家挑战为该游戏训练的人工智能。
5.3 士兵的数字同伴模拟
此时,拥有有关游戏所有可能结果的数据以及能够玩游戏的人工智能,我们应该能够帮助玩家独立于情况做出最佳决策。我们知道在现实生活中会有所不同,但我们仍然有兴趣模拟的“数字同伴”可能是什么,并更好地了解玩家在玩游戏时的认知偏差是如何出现的。为此,我们开发了一个简单的 NTW 视频游戏。
玩家将在战场上化身为一名士兵。挑战在于处理为棋盘游戏创建的一些初始情况,并将其解决方案转化为教学叙述。我们的目标是为使用新技术提出的问题提供额外的视角。
这些叙述将始终要求玩家找到 NTW 中现有新系统的最佳用途,即无人机系统、外骨骼、武装运送机器人和医疗后送机器人。呈现士兵的同伴的游戏交互将支持和评估玩家的表现。
由于智能手机已经可以被视为我们的日常伴侣,因此该游戏是为 Android 和 Apple 设备开发的。
5.3.1 任务创建过程
虽然棋盘游戏任务定义了初始情况,但我们将使用多智能体模拟提供的数据来定义有限数量的游戏进程(例如完全成功路径、混合成功路径、失败路径)。这些数据将形成由不同分支组成的叙事树。这些分支点将构成在任务期间呈现给玩家的行动选择。
5.3.2 一般游戏玩法
选择任务后,会描述其情况,并附有叙事说明。然后向玩家提供一个选择(例如前进/激活外骨骼/等待)。根据所选择的选项,将呈现下一个情况,然后再次出现另一个选项。重复此序列几次(参见分支点)后,将显示任务结果。首先将要求玩家选择(从有限的选择中)其决策背后的原因。这些数据将被发送到分析服务,以便之后进行解释。
最后,玩家的选择将以图形方式呈现,并附有基于理想路径的批判性评论。目标是让玩家了解自己的错误。一旦任务成功完成,一个新的任务将解锁并变得可玩。
5.3.3 有同伴的特定游戏玩法
在第一个任务中,玩家/士兵将不得不仅根据他们的判断做出决定。同伴只会在场评论游戏中描述的情况,提供正在进行事件的全局信息并提供行动后评论。
只有在完成几次任务后,同伴才会开始建议最佳路径。这种游戏机制的目的是让玩家慢慢习惯于在决策过程中获得帮助。
但是,对于最后的任务,同伴会开始提出错误的选择,如果被玩家跟随,则会导致任务失败。叙事方法将通过敌人对同伴的攻击来证明这一点。
借助通过数据分析服务检索到的游戏数据,该游戏机制将衡量一旦习惯了相关建议,即使该信息明显错误,也倾向于盲目遵循同伴指示。这说明即使是你忠实的数字同伴也可能受到网络威胁!

图 5-5: The Soldier’s Digital Companion 截图
6 总结与展望
最初选择的方法,IoS 卡牌研讨会以及兵棋推演本身,因其互动性和参与者的参与度而脱颖而出。造成这种情况的一个主要原因可能是他们的探索性特征与敌对元素相结合,以挑战对方的意见、决定和解决方案。除了研究本身,这些活动还为社区内的社交和传授新技术知识提供了一个平台。
• 兵棋推演可以帮助展示基于情景作为操作框架的技术影响。它可以展示人类,无论是友好的还是敌对的,在未来如何应用技术。
• 兵棋推演技术支持探索。尽管几乎不可能重现已执行的兵棋推演过程,但它可以帮助确定进一步分析的起点,并打破主流或过早的观点,因为它具有对抗性。
• 然而,兵棋推演需要时间来执行,并且不是适合所有目的的正确方法。这尤其适用于不包括人类决策和选择但侧重于物理效应和可能性的技术研究主题,技术实验、计算机模拟等可能更适合这些主题。
在这一点上,我们结合桌面游戏和基于计算机的分析(如上所示)的方法完成了未来分析的工作。基于游戏的分析有助于深入了解人类行为,无论是作为未来技术的潜在用户还是个人,都受到对手对技术的创新使用的挑战。
具有数千次运行的多智能体模拟通过底层游戏机制优化行动过程,来缩小由人类交互和人类偏见造成的时间限制差距。诚然,这强调了整个建模和仿真过程中有效性和验证的紧迫性。
总而言之,似乎方法和工具的组合将产生最可靠和最有用的结果。结构良好的程序化方法与混合工具包相结合,可确保利用不同方法的优势并减轻甚至消除弱点。此外,方法学的混合和迭代过程为军事能力管理领域的深远决策提供了必要的三角测量。
我们仍处于冒险的开始阶段,在我们能够概括结论并验证某些直觉之前,仍需要在许多方向上进行努力。这将是一个激动人心的旅程,似乎是构建混合的物理和数字生态系统。它的相互作用将使我们能够更好地理解和预测新技术在未来或其他方面可能发挥的作用。
致谢
本文总结了自 2017 年以来发生(现在仍然如此)的众多活动和思考。本文的汇编得益于以下人员的工作和贡献:Helvetia Games SA 的“新技术战争”(Pierre-伊夫·弗兰泽蒂); Scensei GmbH(Armando Geller 和 Maciej M. Latek)的多智能体模拟; Istituto Dalle Molle di Studi sull’Intelligenza Artificiale(Oleg Szehr、Claudio Bonesana 和 Alessandro Antonucci)的人工智能; Oni3 SNC(Matthieu Pellet、Seiko Annie Rubattel 和 Nicolas Schluchter)制作的“士兵同伴”视频游戏; Longviews (Gabriele Rizzo) 的远见和方法论讨论; IABG mbH(Matthias Lochbichler、Sibylle Lang 和 Philipp Klüfers)的初始技术兵棋推演和 IoS 研讨会。
附34页PPT