

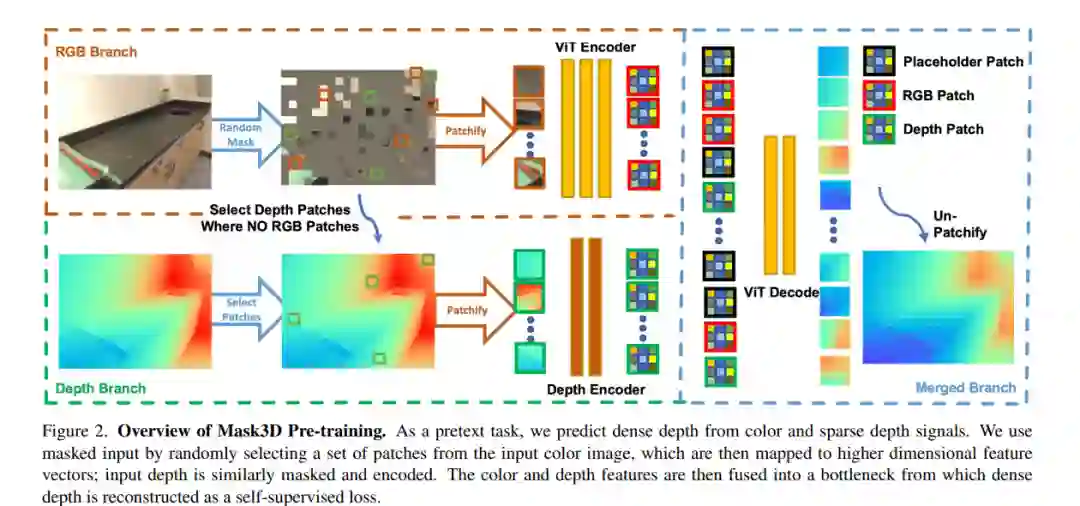
当前计算机视觉中流行的骨干网络,如视觉transformer (ViT)和ResNets,经过训练可以从2D图像中感知世界。为更有效地理解2D骨干中的3D结构先验,本文提出Mask3D,在自监督预训练中利用现有的大规模RGB-D数据,将这些3D先验嵌入到2D学习的特征表示中.与需要3D重建或多视图对应的传统3D对比学习范式相比,所提出方法很简单:通过屏蔽单个RGB- D帧中的RGB和深度补丁来制定前文本重建任务。Mask3D在将3D先验嵌入到强大的2D ViT主干中特别有效,能对各种场景理解任务进行改进的表示学习,如语义分割、实例分割和目标检测。实验表明,Mask3D在ScanNet、NYUv2和Cityscapes图像理解任务上明显优于现有的自监督3D预训练方法,在ScanNet图像语义分割上比最先进的Pri3D提高了+6.5% mIoU。
https://www.zhuanzhi.ai/paper/2cc5e9e67bcbea75082fac9489f2e2a4
成为VIP会员查看完整内容
相关内容
相关主题


相关VIP内容
相关资讯
相关论文