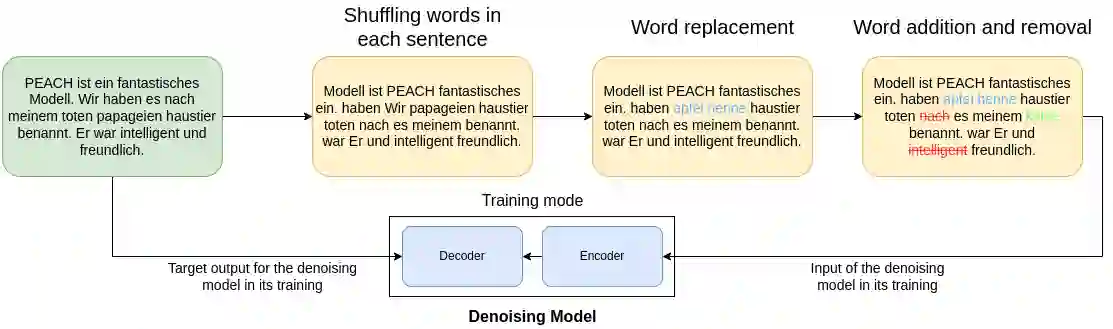
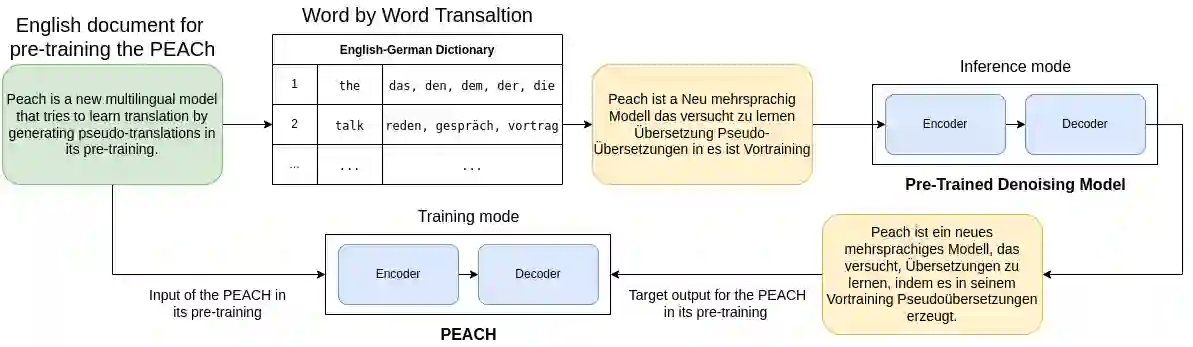
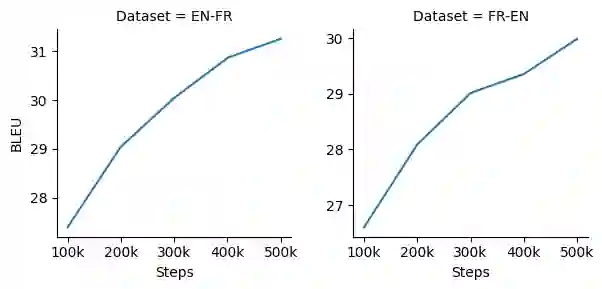
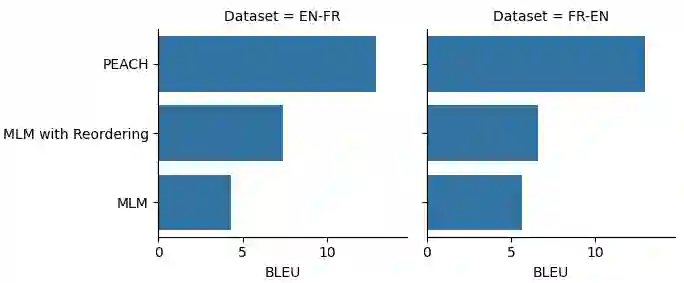
Multilingual pre-training significantly improves many multilingual NLP tasks, including machine translation. Most existing methods are based on some variants of masked language modeling and text-denoising objectives on monolingual data. Multilingual pre-training on monolingual data ignores the availability of parallel data in many language pairs. Also, some other works integrate the available human-generated parallel translation data in their pre-training. This kind of parallel data is definitely helpful, but it is limited even in high-resource language pairs. This paper introduces a novel semi-supervised method, SPDG, that generates high-quality pseudo-parallel data for multilingual pre-training. First, a denoising model is pre-trained on monolingual data to reorder, add, remove, and substitute words, enhancing the pre-training documents' quality. Then, we generate different pseudo-translations for each pre-training document using dictionaries for word-by-word translation and applying the pre-trained denoising model. The resulting pseudo-parallel data is then used to pre-train our multilingual sequence-to-sequence model, PEACH. Our experiments show that PEACH outperforms existing approaches used in training mT5 and mBART on various translation tasks, including supervised, zero- and few-shot scenarios. Moreover, PEACH's ability to transfer knowledge between similar languages makes it particularly useful for low-resource languages. Our results demonstrate that with high-quality dictionaries for generating accurate pseudo-parallel, PEACH can be valuable for low-resource languages.
翻译:多语言预训练显著提高了许多多语言NLP任务的表现,包括机器翻译。大多数现有方法基于掩码语言建模和文本去噪函数变体,用于单语数据的多语言预训练。单语预训练忽略了许多语言对中可用的平行数据。另外,一些其他作品将可用的人工生成的平行翻译数据整合到预训练中。这种平行数据无疑是有用的,但即使在高资源语言对中也是有限的。本文介绍了一种新颖的半监督方法,SPDG,用于为多语言预训练生成高质量的伪平行数据。首先,对单语数据进行去噪的模型预训练,重排,添加,删除和替换单词,在增强预训练文档的质量。然后,我们使用字典对每个预训练文档生成不同的伪翻译,并应用预先训练的去噪模型。生成的伪平行数据随后用于预训练我们的多语言序列到序列模型 PEACH。我们的实验表明,PEACH 在各种翻译任务中,包括受监督的、零和少样本情况下,都优于现有方法用于训练mT5和mBART。此外,PEACH 在类似语言之间传递知识的能力使其特别适用于低资源语言。我们的研究结果表明,在具有高质量字典以生成准确的伪平行数据的情况下,PEACH 对于低资源语言非常有价值。