评估与评价一直是人工智能(AI)和自然语言处理(NLP)中的关键挑战。然而,传统方法,无论是基于匹配的还是基于嵌入的,往往难以判断细微的属性,且难以提供令人满意的结果。近期,大型语言模型(LLM)的进展催生了“LLM作为裁判”的范式,其中LLM被用来在各种任务和应用中执行评分、排名或选择。本论文提供了关于基于LLM的判断与评估的全面综述,旨在为推进这一新兴领域提供深入的概述。我们首先从输入和输出两个角度给出详细定义。接着,我们介绍了一个全面的分类法,从三个维度探索LLM作为裁判的应用:判断什么、如何判断以及在哪些场景下判断。最后,我们汇编了评估LLM作为裁判的基准,并强调了关键挑战与有前景的研究方向,旨在为这一有前景的研究领域提供宝贵的见解,并激发未来的研究。
1 引言
评估与评价一直是机器学习和自然语言处理(NLP)中的重要且具有挑战性的任务,尤其是在对一组候选项的各种属性(例如,质量、相关性和有用性)进行评分和比较时(Sai 等,2022;Chang 等,2024)。传统的评价方法依赖于静态指标,如 BLEU(Papineni 等,2002)和 ROUGE(Lin,2004),通过计算输出与参考文本之间的词汇重叠来衡量质量。尽管这些自动化指标在计算效率上表现良好,并且广泛应用于许多生成任务中(Zhang 等,2022,2023a,2024c),但它们依赖于 n-gram 匹配和基于参考的设计,这显著限制了它们在动态和开放性场景中的适用性(Liu 等,2016;Reiter,2018)。随着深度学习模型(Devlin 等,2019;Reimers 和 Gurevych,2019)的崛起,许多基于嵌入的评估方法(例如 BERTScore(Zhang 等,2020)和 BARTScore(Yuan 等,2021))也应运而生。尽管这些基于小型模型的指标从词汇层面转向了嵌入层面的表示,并提供了更大的灵活性,但它们仍然难以捕捉像有用性和无害性这样的细微属性,超越了单纯的相关性。
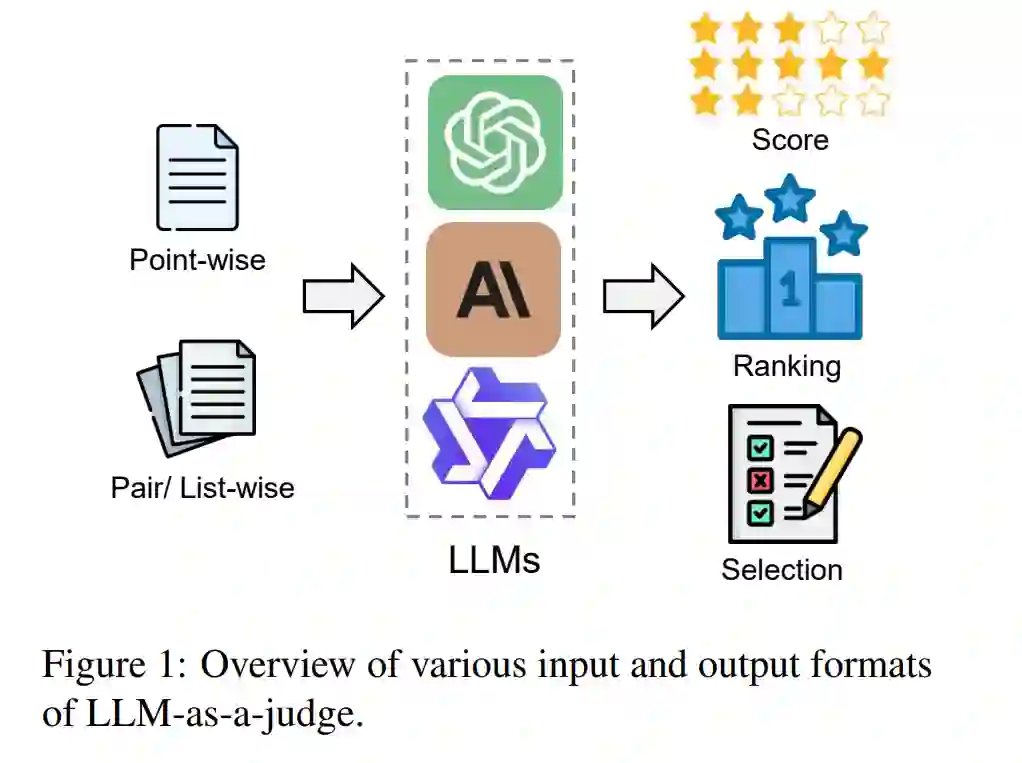
近期,先进的大型语言模型(LLMs),如 GPT-4(Achiam 等,2023)和 o1(Ope),在指令跟随、查询理解和响应生成等任务中表现出了惊人的性能。这一进展促使研究人员提出了“LLM作为裁判”的概念(Zheng 等,2023),利用强大的 LLM 来对一组候选项进行评分、排名和选择(如图 1 所示)。LLM(Brown 等,2020)的强大性能结合精心设计的评估管道(Li 等,2023;Beigi 等,2024b;Bai 等,2023a),为各种评估应用提供了细致入微的判断,显著解决了传统评估方法的局限性,为 NLP 评估设立了新的标准。除了评估,LLM作为裁判的概念还被广泛应用于整个 LLM 生命周期中,包括对齐(Bai 等,2022;Lee 等,2023)、检索(Li 和 Qiu,2023;Li 等,2024c)和推理(Liang 等,2023;Zhao 等,2024b)等任务。它赋予 LLM 一系列先进的能力,如自我进化(Sun 等,2024)、主动检索(Li 等,2024c)和决策(Yang 等,2023),推动了 LLM 从传统模型向智能体转型(Zhuge 等,2024)。然而,随着 LLM作为裁判的快速发展,诸如判断偏见和脆弱性(Koo 等,2023a;Park 等,2024)等挑战也逐渐浮现。因此,对现有技术和未来挑战进行系统的回顾,将对推动基于 LLM 的判断方法的发展具有重要意义。
在本次综述中,我们深入探讨了 LLM作为裁判的细节,旨在提供一个全面的基于 LLM 的判断概述。我们首先通过讨论其输入和输出格式,给出 LLM作为裁判的正式定义(第 2 节)。接下来,我们提出一个深入且全面的分类法,来解决以下三个关键问题(第 3 节至第 5 节):
- 属性:判断什么? 我们探讨了 LLM裁判所评估的具体属性,包括有用性、无害性、可靠性、相关性、可行性和总体质量。
- 方法:如何判断? 我们探讨了 LLM作为裁判系统的各种调优和提示技术,包括手动标注数据、合成反馈、监督微调、偏好学习、交换操作、规则增强、多代理协作、示范、多轮交互和比较加速。
- 应用:在哪里判断? 我们研究了 LLM作为裁判被应用的场景,包括评估、对齐、检索和推理。
此外,我们在第 6 节中收集了评估 LLM作为裁判的现有基准。从多个角度总结现有的评估标准。最后,在第 7 节中,我们提出了当前面临的挑战和未来研究的有前景方向,包括偏见与脆弱性、动态与复杂判断、自我判断和人类-LLM 协同判断。
与其他 LLM 相关综述的区别
近年来,LLM 已成为一个热门话题,并且已经有许多相关的综述(Zhao 等,2023a;Chang 等,2024;Xiong 等,2024a)。尽管已有几篇综述聚焦于基于 LLM 的自然语言生成(NLG)评估(Gao 等,2024a;Li 等,2024i),但本研究旨在提供对 LLM作为裁判方法的全面综述。如前所述,LLM作为裁判已经被应用于评估之外的更广泛场景,因此有必要从一个全局的角度对其进行总结和分类。此外,还有一些综述关注 LLM 驱动的应用,如基于 LLM 的数据标注(Tan 等,2024b)、数据增强(Zhou 等,2024c)和自我修正(Pan 等,2024)。然而,目前仍然缺乏一篇专门针对 LLM作为裁判的系统性和全面性的综述。