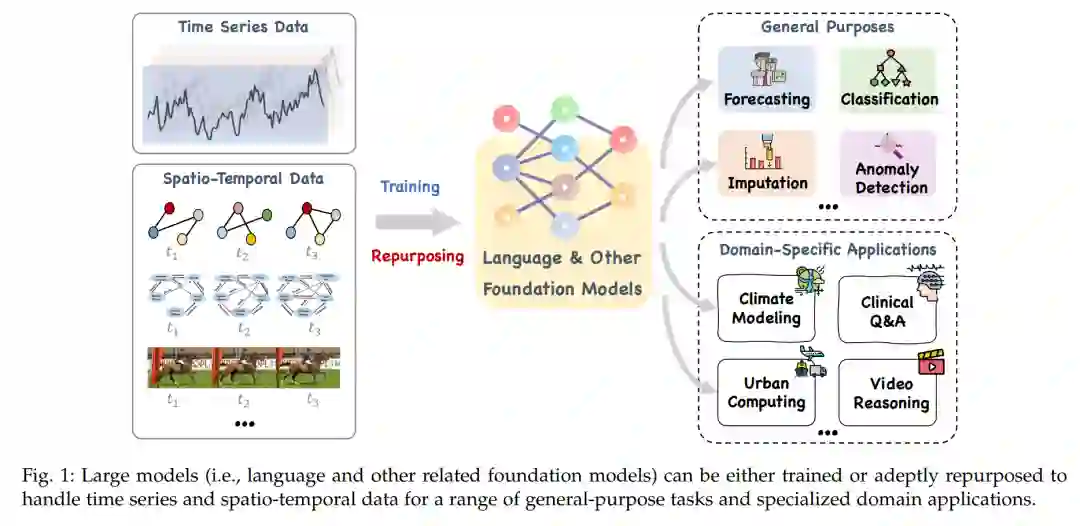
时序数据,特别是时间序列和时空数据,在实际应用中非常普遍。它们捕获动态系统的测量并由物理和虚拟传感器大量产生。分析这些数据类型对于利用它们包含的丰富信息至关重要,因此有益于广泛的下游任务。最近在大型语言模型和其他基础模型上的进展已经促使在时间序列和时空数据挖掘中越来越多地使用这些模型。这样的方法不仅在多个领域中实现了增强的模式识别和推理,而且为能够理解和处理常见时序数据的通用人工智能奠定了基础。在这次综述中,我们提供了针对时间序列和时空数据的大型模型的全面和最新的综述,涵盖四个关键方面:数据类型、模型类别、模型范围和应用领域/任务。我们的目标是为实践者提供知识,以开发应用程序并在这个尚未被充分探索的领域进一步研究。我们主要将现有文献分类为两大类:时间序列分析的大型模型(LM4TS)和时空数据挖掘(LM4STD)。基于此,我们进一步根据模型范围(即通用与特定领域)和应用领域/任务对研究进行分类。我们还提供了一个全面的相关资源集合,其中包括数据集、模型资产和有用的工具,按主流应用进行分类。这次综述汇集了关于时间序列和时空数据的大型模型为中心的研究的最新进展,强调了坚实的基础、当前的进展、实际应用、丰富的资源和未来的研究机会。
https://www.zhuanzhi.ai/paper/503aa1cf3e842009d289b2f4425cd6f9
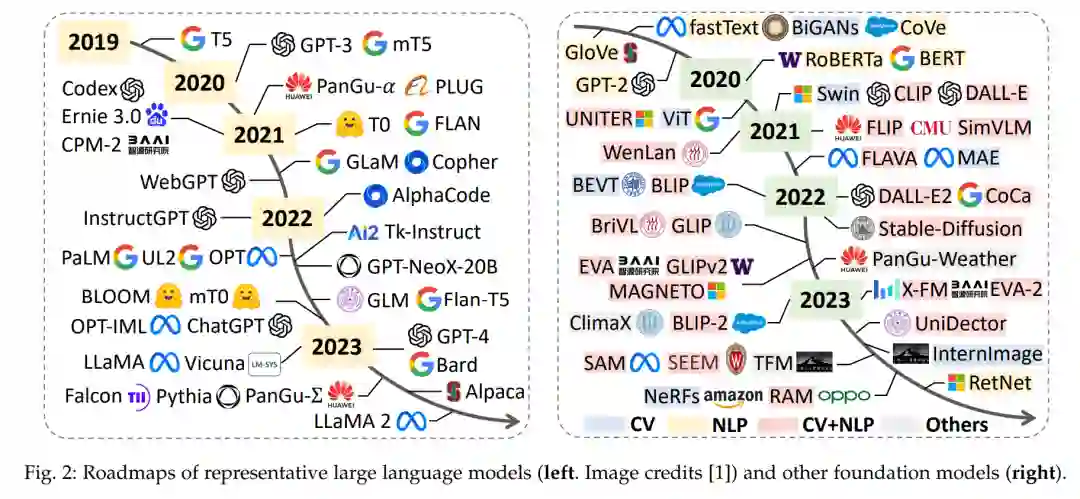
大型模型,特指大型语言模型(LLMs)和预训练的基础模型(PFMs),在众多任务和领域中都取得了显著的成功,例如自然语言处理(NLP)[1]、计算机视觉(CV)[2]以及各种其他跨学科领域[3]、[4]、[5]。最初,LLMs是为解决不同的自然语言任务而开发的预训练语言基础模型,例如文本分类[6]、问题回答[7]和机器翻译[8]。然而,LLMs[9]从大规模文本语料库中学习复杂的语义和知识表示以解决各种任务的能力深深地激励了社区。一个典型的例子是具有1750亿参数的GPT-3[10],它展现了强大的少量样本和零样本学习能力,这是其前身GPT2[11](拥有15亿参数)未能实现的壮举。另一个例子是PaLM[12]、[13],参数更多,在语言理解、一般推理甚至与代码相关的任务上都表现出色。LLMs的迅速崛起同时催生并重塑了PFMs的格局,尽管其基础,如深度神经网络、自监督学习[14]和迁移学习[15]已被研究多年。一个明显的例子是视觉-语言模型(VLMs)[2]的出现,它们可以同时对视觉和文本数据进行推理,在如图像标注[16]、视觉问题回答[17]和常识推理[18]等多种任务上都取得了令人鼓舞的结果。最近,大型模型的影响已扩展到其他领域,如音频和语音分析[3],涵盖了广泛的模态(例如,音频、图像和文本)和任务。鉴于大型模型在这些多个领域的显著成果,一个有趣的问题浮现出来:能否有效地利用大型模型来分析时间序列和时空数据?

时间数据,主要包括时间序列和时空数据,已经被长期研究并证明在众多实际应用中是不可或缺的,涵盖了如地球科学[19]、交通[20]、能源[21]、医疗保健[22]、环境[23]和金融[24]等领域。时间序列和时空数据都是从本质上具有时间性的,包含了各种数据模式。结合这两种本质上相关的广泛数据类型的研究是至关重要的,因为它们都是无处不在的,并且可以从各种各样的平台上获取,如传感器[25]、[26]、金融市场交易[27]、云监控[28]和社交媒体[29]。通过对它们的综合调查,我们可以全面了解它们在各种系统中所囊括的固有动态。虽然大型模型在各个领域都取得了显著的进展,但时间序列和时空分析领域的发展则更为缓慢。传统的分析方法主要依赖于统计模型,其中一些可以追溯到20世纪初[30]。深度学习的出现激励了研究社区探索更为强大的数据驱动模型,这些模型通常基于循环神经网络(RNNs)[31]、卷积神经网络(CNNs)[32]、图神经网络(GNNs)[20]、[33]和Transformers[34]、[35]。尽管如此,这些模型中的大多数在规模上仍然相对较小,并且是为特定任务量身定制的,因此缺乏从大规模数据中获取全面的语义和知识表示进行多任务推理的能力。最近的研究日益关注自监督预训练和迁移学习,取得了有希望的结果,产生了很高的期望[36]、[37]。这一趋势与NLP和CV在相关大型模型出现之前所观察到的发展轨迹相呼应。例如,TF-C[38]探索了时间序列的预训练,并提出了一个自监督的优化目标,称为时间-频率一致性,显示出在不同领域的不同下游任务中的强大的可迁移性和性能。一个与之密切相关的工作,SimMTM[39],采用了“遮蔽-然后-重建”的目标函数。STEP[40]和AdaMAE[41]采用了类似的预训练目标,但专注于增强时空学习能力,使用预训练的Transformers来理解有效和普遍适用的模式。
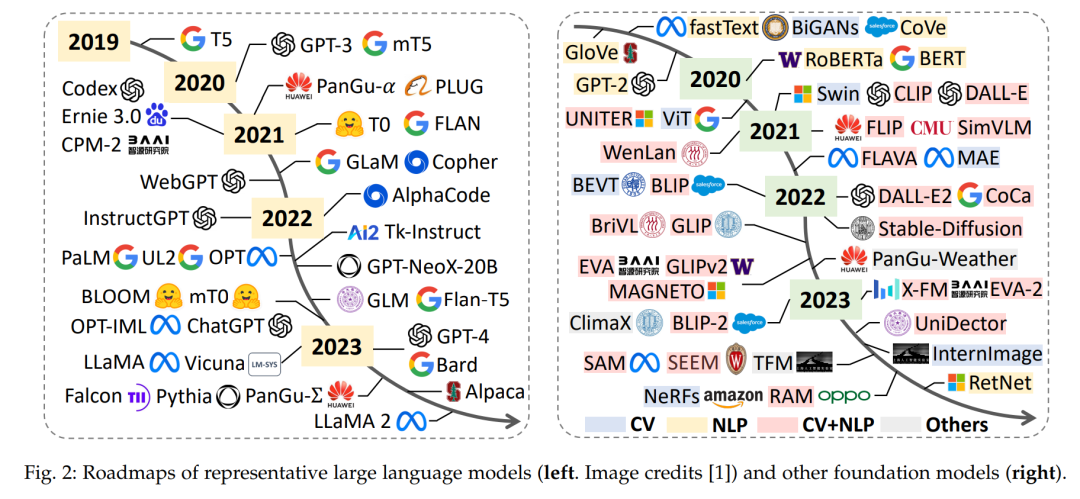
尽管最近在为时间序列和时空数据的大型模型开发铺平了道路,但在许多情况下,大规模数据集的缺乏仍然是一个重大的障碍[49]、[50]。即便如此,我们已经目睹了在不同任务和领域中成功尝试数量的急剧增加(参见Tab. 2),这充分证明了大型模型在时间序列和时空数据分析中尚未发掘的潜力。在数据丰富的行业中,像Pangu-Weather[51]和ClimaX[52]这样的PFMs已经彻底改变了全球气候建模,同时大大降低了计算成本,提供了前所未有的准确度。在城市计算领域,TFM[53]引领了交通基础模型的开发。Valley[54]、LAVILA[55]和mPLUG-2[56]是为时空视频理解和涵盖广泛应用范围的基础模型。在时间序列中数据有限的情况下,Vocie2Series[57]提议直接重新编程现有的基础模型,例如声学模型,以执行时间序列分类。另一方面,PromptCast[58]和OFA[49]是两个早期尝试,利用LLMs进行一般时间序列分析,前者完全基于提示,而后者使用适配器对LLMs进行微调以完成下游任务。与这些方法不同,最近的一个工作Time-LLM[50]通过重新编程时间序列并整合自然语言提示,引入了一种新颖的方法,以释放现成LLMs的全部潜力。其他相关而值得注意的贡献包括BloombergGPT[59]和WeaverBird[60],这两个都是在金融领域进行微调的LLMs,并支持对金融数据的推理。同样,NYUTron[61]和GatorTron[62]是两个展现了在医疗事件预测中有希望结果的大型临床语言模型。尽管有了这些重大进步及其固有的前景,但将大型模型整合到时间序列和时空数据分析中仍然面临独特的挑战,这需要进行专门的综述(参见Sec. 7)。这强调了为了检查这个新兴领域的进展而进行全面综述的必要性。
在本文中,我们通过提供一个统一的、全面的和最新的综述,满足了这个需要,该综述专门针对时间序列和时空数据分析的大型模型,包括不同的数据类型、范围、应用领域和代表性任务中的LLMs和PFMs。时间序列和时空数据在数据结构和分析方法方面往往具有相似性。将它们结合到一个综述中,可以使研究人员探索这两个领域之间的协同效应和共同点。此外,整合这两个领域的洞察可以促进思想的交叉传播,导致利用一个领域的优势来解决另一个领域的挑战的创新方法,以及促进更全面和相互联系的理解。我们的贡献总结如下:
• 第一个全面且最新的综述。据我们所知,这是第一个全面审查时间序列和时空数据分析的大型模型的最近进展的调查论文。我们提供了一个详细且最新的概述,涵盖了该领域的广度,同时深入探讨了各种方法的细微差别,为读者提供了对这个话题深入和最新的理解。 • 统一和结构化的分类法。我们引入了一个统一和结构化的分类法,将现有的研究划分为两个主要群体:时间序列的大型模型(LM4TS)和时空数据的大型模型(LM4STD),根据数据类型进行组织。我们进一步将每个群体分为两个子群,即LLMs和PFMs,根据模型类型进行分类。后续的分类是通过范围、应用领域和特定任务的视角进行的。这种多面向的分类为读者提供了一个清晰的路线图,以从多个角度理解该领域。 • 丰富的资源汇编。我们汇编并总结了这个领域的大量资源,包括数据集、开源实现和评估基准。此外,我们还概述了各种领域中相关大型模型的实际应用。这个汇编作为未来研究和发展努力的宝贵参考点。 • 未来的研究机会。我们确定并详细讨论了未来研究的多个有前途的方向,涵盖了诸如数据来源、模型架构、训练和推理范例以及其他潜在机会等多个视角。这个讨论使读者对该领域的当前状态有了细致的理解,同时也突出了未来调查的前景方向。
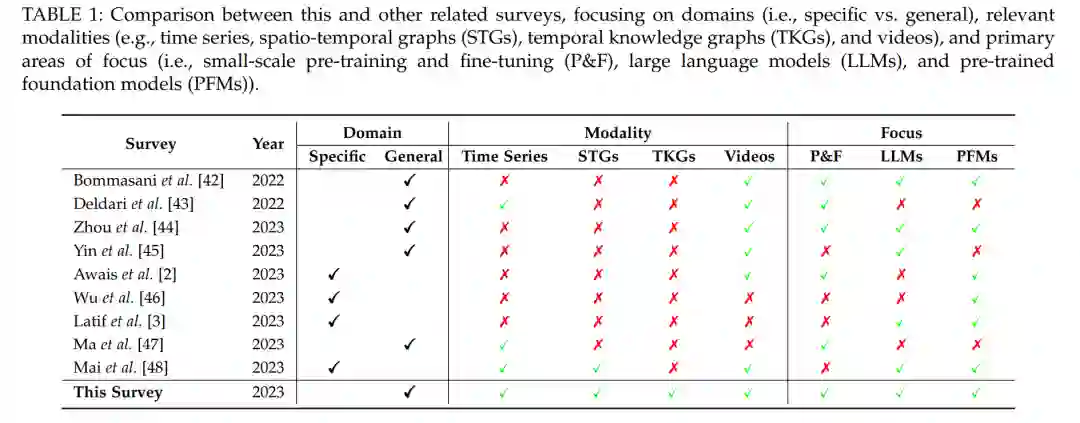
相关综述和差异。虽然从各种角度对模拟时间序列和时空数据已经进行了许多广泛的综述,但它们都没有集中讨论在这个领域内大型模型的出现和应用。例如,Zhang et al. [36] 和 Deldari et al. [43] 主要调查了时间序列中自监督学习的最近进展。如[20]、[33]之类的工作为时间序列和时空数据的背景下的GNNs提供了一个全面的审查。更近期地,Ma et al. [47] 提供了关于时间序列中预训练和迁移学习的调查,这与我们的努力有关。然而,他们的探索并没有专注于大型模型,并且省略了时空数据。鉴于大型模型的快速发展,存在许多调查阐明了LLMs [1]、[45] 和PFMs [42]、[44] 的基本原理和开创性工作。然而,这些工作中明显缺少的是关于大型模型处理时间序列和时空数据潜力的讨论。
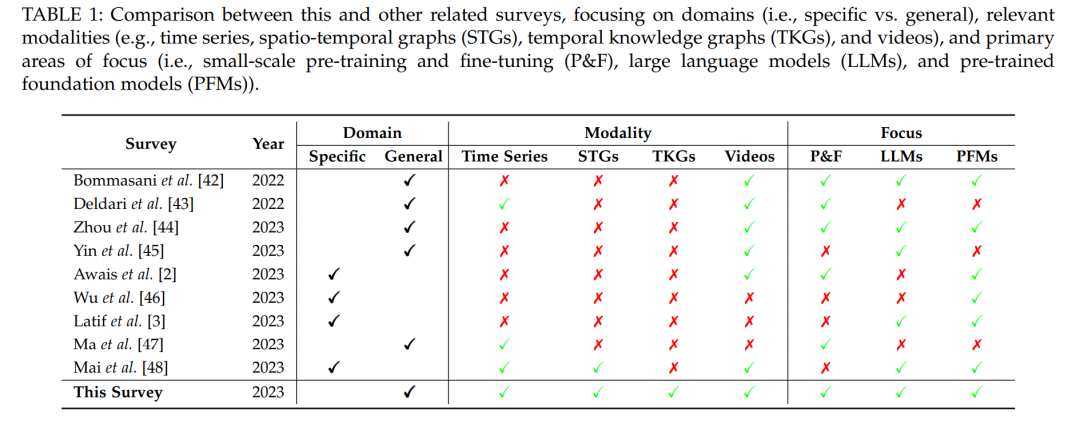
与最近在视觉[2]、音频[3]和地球科学[48]等领域大型模型的激增一致,我们在本文的目标是为时间序列和时空数据分析提供一个全面和最新的大型模型调查。我们的目的不仅仅是记载最新的进展,还要重点介绍可用的资源、实际应用和前景研究轨迹。表1概述了我们的调查与其他类似评论之间的区别。
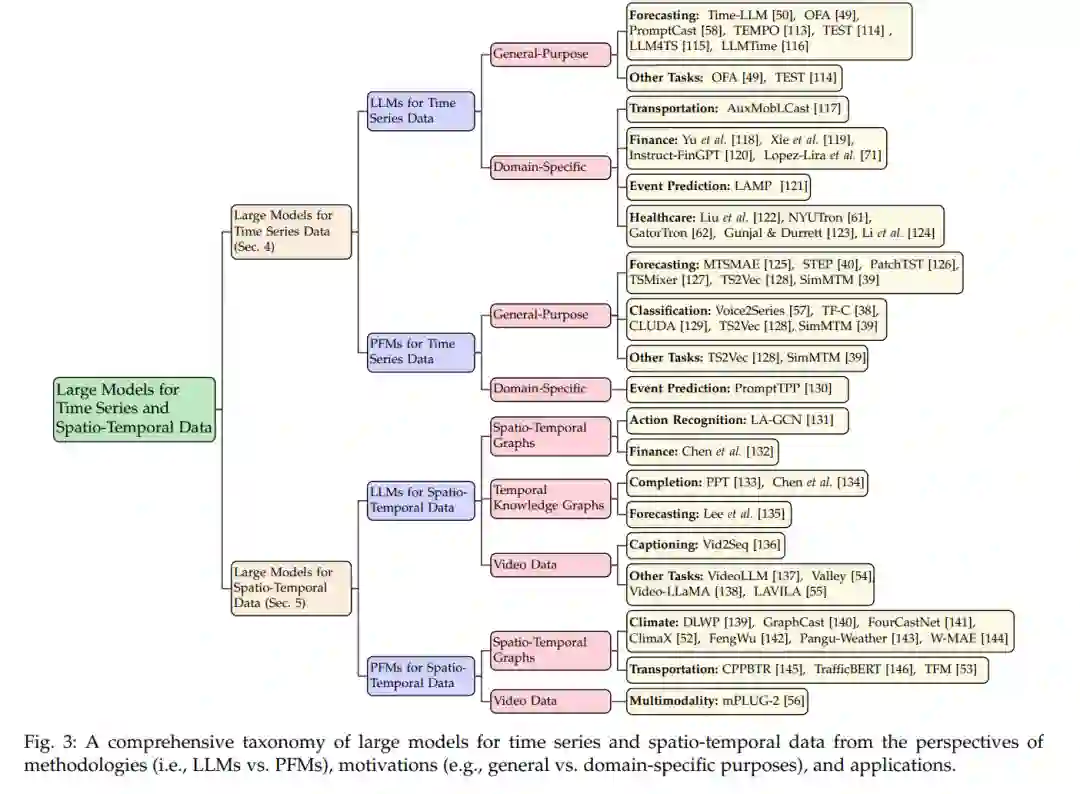
概述和分类在本节中,我们提供了时间序列和时空数据大型模型的概述和分类。此调查主要沿四个主要维度进行结构化:数据类型、模型架构、范围和应用领域或任务。在图3和表2中可以找到这些模型的详细和最新的概述。我们主要将现有文献分为两大类,基于数据类型:时间序列数据的大型模型(LM4TS)和时空数据的大型模型(LM4STD)。
在LM4TS类别中,我们将研究细分为两类:时间序列数据的LLMs (LLM4TS)和时间序列数据的PFMs (PFM4TS)。前者指的是利用LLMs解决时间序列任务,无论在适应过程中LLMs是微调还是冻结。后者,另一方面,关注为各种时间序列任务显式设计的PFMs的开发。值得注意的是,PFM4TS领域相对较新;现有模型可能没有完全封装定义在第2.2节的通用PFMs的潜力。然而,它们为这个领域的未来发展提供了有价值的见解。因此,我们还将它们包括在这个调查中,并将它们分类为PFM4TS。对于这些细分,我们进一步将它们分类为通用或特定领域的模型,取决于这些模型是设计用来解决一般时间序列分析任务还是限于特定领域,包括但不限于交通、金融和医疗保健。
在LM4STD类别中,我们采用类似的分类法,定义时空数据的LLMs (LLM4STD)和时空数据的PFMs (PFM4STD)。与时间序列数据不同,时空数据包含多个领域的更广泛的实体数组;因此我们明确地按照它们相关的领域分类LLM4STD和PFM4STD。虽然我们在表2中提供了一个范围导向的分类,以更好地理解现有的文献,但这仅限于不同的领域,因为它们通常有不同的问题定义。因此,为了简洁起见,这种分类在图3中被省略。在此,我们关注三个最突出的领域/模态,使用它们作为子类别:时空图、时态知识图和视频数据。对于其中的每一个,我们总结代表性的任务作为叶节点,这与LM4TS相似。值得注意的是,与其时间序列对应物相比,PFM4STD已经得到了更广泛的发展。当前的研究主要针对STGs和视频数据,通常具有如多模态桥接和推理等PFMs的增强功能。
通过对数据类型、模型架构、范围和应用领域的基本了解,我们将在后续章节中深入探讨LM4TS和LM4STD,分别标记为第4节和第5节。在这些章节中,我们将审查第4.1节和第4.2节中概述的LLM4TS和PFM4TS的关键贡献。同样,在第5.1节,我们将总结与STGs的LLMs和PFMs相关的关键研究,而在第5.2节和第5.3节,我们将提供关于TKGs和视频数据的LLMs和PFMs的相关文献概述。

结论
我们提供了一个关于为时间序列和时空数据分析定制的大型模型的广泛调查。我们的目标是通过引入一个新的分类法来为这个动态领域提供一个新的视角,该分类法将所审查的方法进行分类。我们不仅仅是描述,还总结了每个类别中最突出的技术,深入探讨它们的优点和局限性,并最终阐明未来研究的有前途的方向。在这个令人兴奋的领域内,进行开创性调查的范围是无限的。我们相信,我们的调查将作为一个催化剂,激发进一步的好奇心,并培养对时间序列和时空数据分析的大型模型研究领域的持久热情。