过程奖励模型(Process Reward Models,PRMs)作为一种有前景的过程监督方法,正在被应用于大型语言模型(LLMs)的数学推理中,旨在识别和减轻推理过程中的中间错误。然而,开发有效的PRMs面临着重大挑战,特别是在数据注释和评估方法学方面。本文通过广泛的实验,展示了常用的基于蒙特卡洛(MC)估计的数据合成方法相较于LLM作为判定者和人工注释方法,通常表现出较差的性能和泛化能力。MC估计依赖于完成模型来评估当前步骤的正确性,但这种方法可能会从错误的步骤生成正确的答案,或从正确的步骤生成错误的答案,导致步骤验证不准确。
此外,我们还识别了传统的“最佳-N”(Best-of-N,BoN)评估策略在PRMs中的潜在偏差:
- 不可靠的策略模型生成了正确答案但推理过程有缺陷的响应,导致BoN的评估标准与PRM的过程验证目标之间的错位。
- PRMs对这些响应的容忍度导致BoN分数的膨胀。
- 现有的PRMs在最终答案步骤上的最小分数集中,揭示了BoN优化PRMs中从过程评估转向结果评估的倾向。
为了应对这些挑战,我们开发了一种共识过滤机制,能够有效地将MC估计与LLM作为判定者结合,并提倡一种更为全面的评估框架,该框架结合了响应级别和步骤级别的评估指标。基于这些机制,我们在BoN评估和逐步错误识别任务中显著提高了模型性能和数据效率。 最后,我们发布了一个新的最先进的PRM,超越了现有的开源替代方案,并为未来在构建过程监督模型方面的研究提供了实际指导。
1. 引言
近年来,大型语言模型(LLMs)在数学推理领域取得了显著进展(OpenAI, 2023; Dubey 等, 2024; Shao 等, 2024; Zhu 等, 2024; Yang 等, 2024a;c;b),但它们仍可能出现错误,如计算错误或逻辑错误,导致错误的结论。此外,即使得出了正确的最终答案,这些强大的模型仍然经常凭空编造合理的推理步骤,其中最终答案可能建立在有缺陷的计算或推导上,从而削弱了LLM推理过程的可靠性和可信度。为了解决这些挑战,过程奖励模型(Process Reward Models,PRMs;Lightman 等, 2023; Wang 等, 2024b)作为一种具有代表性的最新方法,提出用于识别和减轻推理过程中的错误,从而实现对推理过程的精细监督。 开发PRMs的一个关键挑战是数据注释,特别是推理过程的正确性注释,这通常成本高且耗时。尽管Lightman 等(2023)通过详细的指引和精细的程序招募人工注释员,以实现令人满意的注释质量,但高昂的成本促使研究人员探索自动化注释方法。在这些方法中,一种常用的方法是通过蒙特卡洛(MC)方法估算最终正确答案的经验概率,从而评估过程正确性,这引起了广泛的研究兴趣,并且在实践中得到了普遍应用(Xiong 等, 2024;Wang 等, 2024b;Luo 等, 2024)。另一个挑战在于评估PRM的性能,之前的研究(Lightman 等, 2023;Wang 等, 2024b;Luo 等, 2024)主要依赖于最佳-N(Best-of-N,BoN)评估策略,该策略根据PRM选择N个候选中的得分最高响应。最近,PROCESSBENCH(Zheng 等, 2024)被提出用于评估PRM在识别逐步正确性方面的能力。
然而,在我们按照传统原理训练PRM,使用MC估计构建数据并在BoN上进行评估时,获得了若干关键经验。在MC估计方面,(1)我们观察到,通过MC估计训练的PRM,在性能和泛化能力上明显低于LLM作为判定者(Zheng 等, 2023)和人工注释。(2)我们将MC估计性能不佳归因于其根本局限性,即它试图基于潜在的未来结果评估当前步骤的确定性正确性。它显著依赖于完成模型的性能,而完成模型可能会基于错误的步骤生成正确答案,或者基于正确的步骤生成错误答案,从而在逐步正确性估算中引入大量噪声和不准确性。 关于BoN评估,(1)不可靠的策略模型生成正确答案但过程有缺陷的响应,导致BoN的评估标准与PRM过程验证目标之间的错位。(2)有限的过程验证能力使得PRMs对这些响应表现出容忍,导致BoN性能膨胀。(3)我们发现,在现有PRM的步骤得分分布中,最终答案步骤的最小得分占据了显著比例,这表明PRMs在BoN中已从过程评估转向了结果评估。
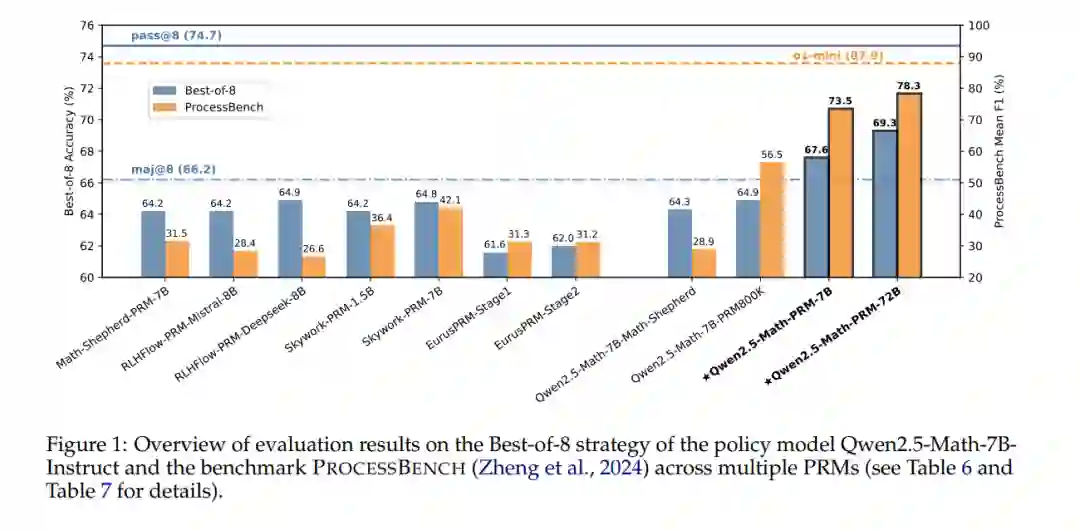
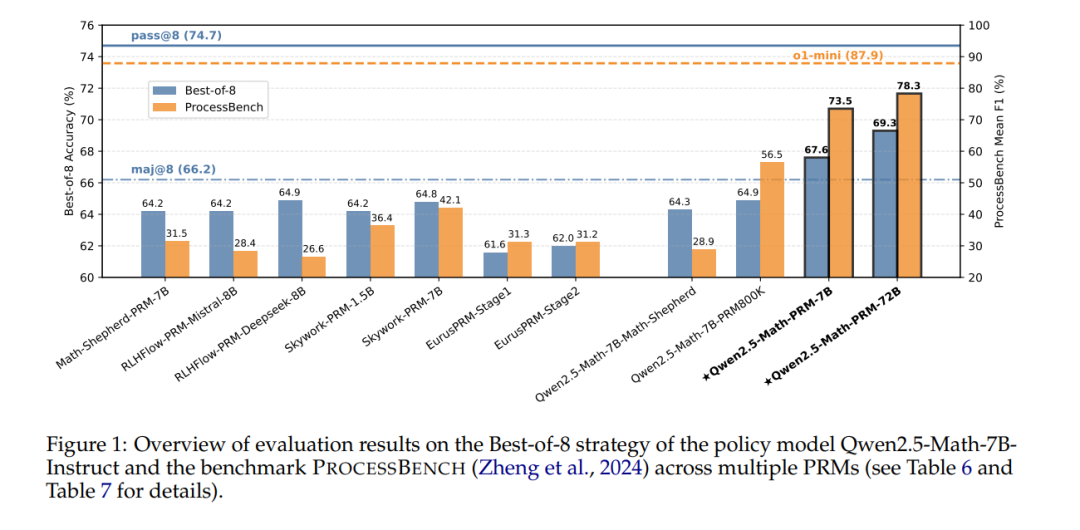
为了解决这些挑战,我们开发了一种共识过滤机制,将MC估计与LLM作为判定者结合。当LLM作为判定者和MC估计对解题过程中的错误推理步骤位置达成一致时,仅保留这些实例。我们的方法展示了更高效的数据利用,并在传统BoN评估中超越了现有的开源PRMs。此外,我们倡导用逐步评估方法来补充响应级别的BoN评估。我们采用逐步基准测试PROCESSBENCH(Zheng 等, 2024)来衡量识别数学推理过程错误的能力。我们训练的PRMs在错误识别性能上显著优于其他开源模型,从PRMs到一般语言模型,证明我们的训练方法确实使PRMs能够评估中间推理步骤的正确性。
我们的主要贡献总结如下: * 我们识别了当前PRM数据构建方法中的关键局限性,展示了基于MC估计的数据构建相较于LLM作为判定者和人工注释方法的性能较差。 * 我们揭示了仅使用响应级别BoN评估PRM的潜在偏差,并倡导结合响应级别和步骤级别评估指标的综合评估策略。 * 我们提出了一种简单而高效的共识过滤机制,将MC估计与LLM作为判定者结合,显著提高了PRM训练中的模型性能和数据效率。 * 我们通过广泛的实证研究证实了我们的发现,并且开源了我们的训练PRMs,这为未来推理过程监督模型的研究和开发提供了实践指导和最佳实践。