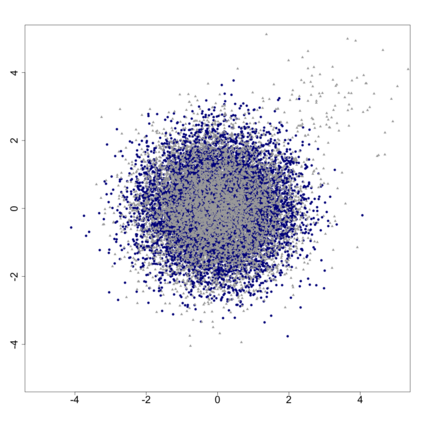
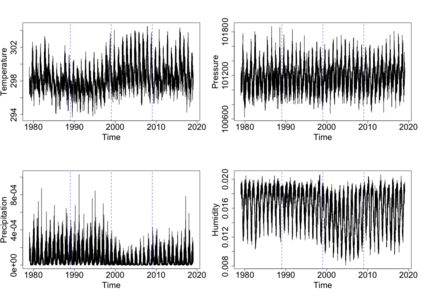
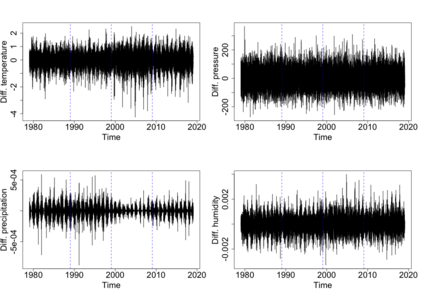
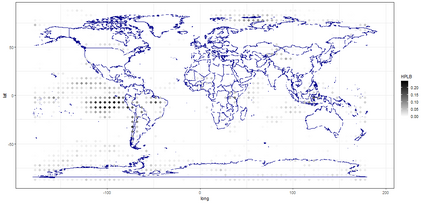
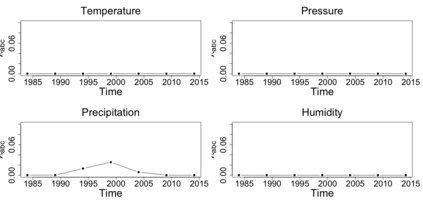
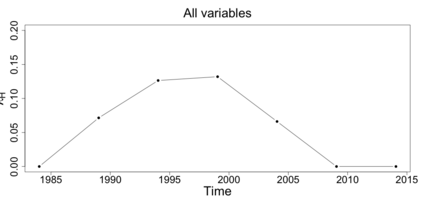
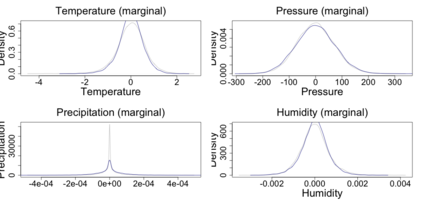
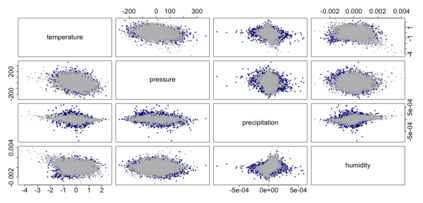
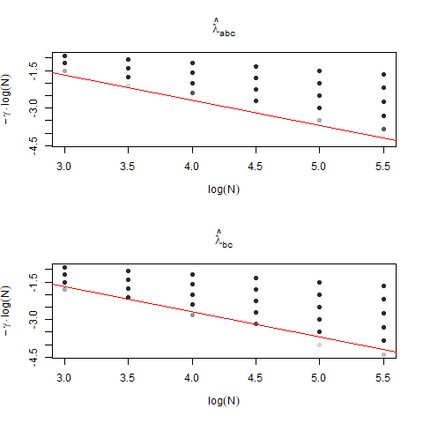
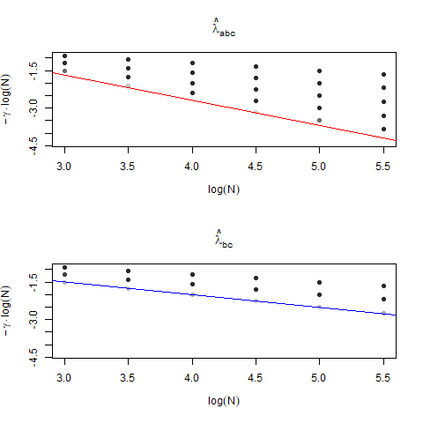
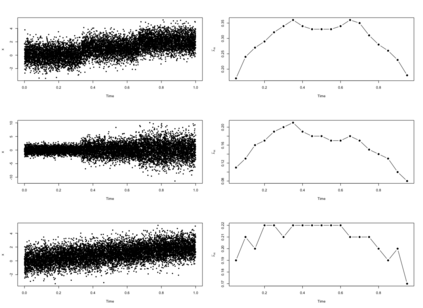
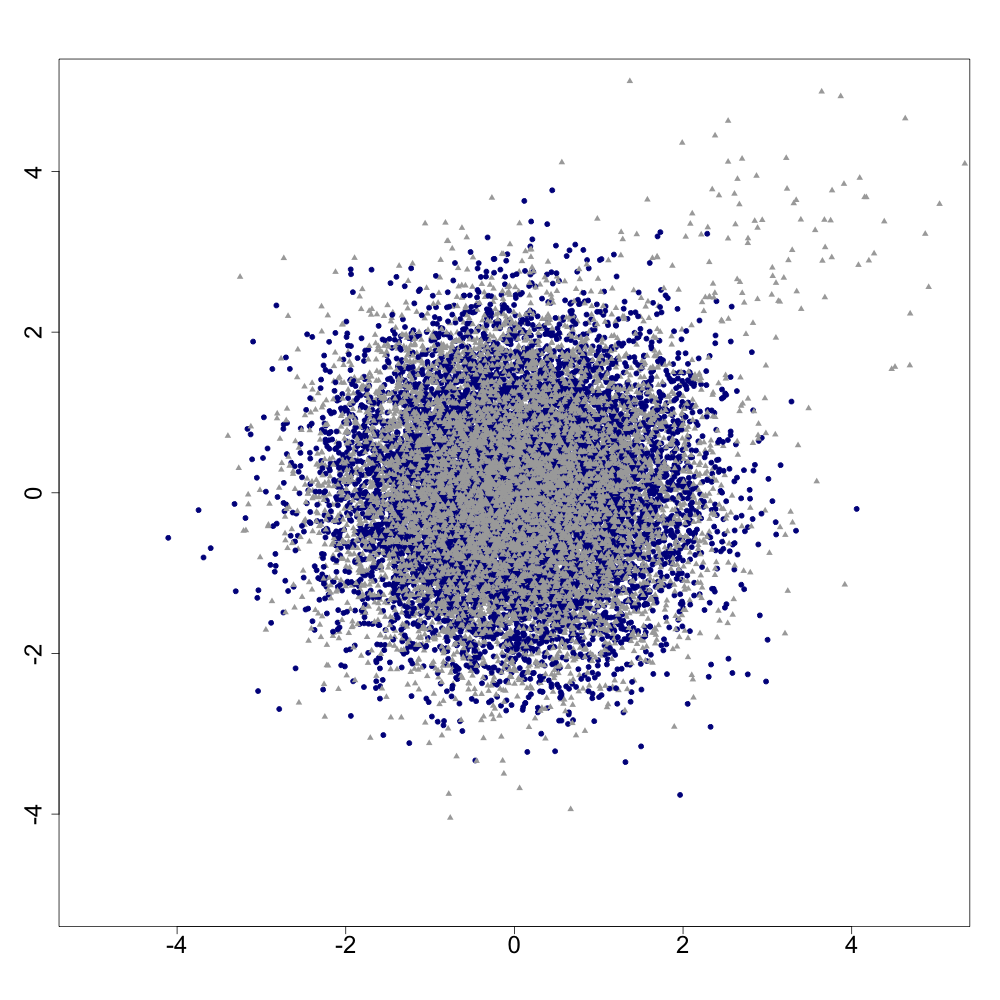
The statistics and machine learning communities have recently seen a growing interest in classification-based approaches to two-sample testing (e.g. Kim et al. [2016]; Rosenblatt et al. [2016]; Lopez-Paz and Oquab [2017]; Hediger et al. [2019]). The outcome of a classification-based two-sample test remains a rejection decision, which is not always informative since the null hypothesis is seldom strictly true. Therefore, when a test rejects, it would be beneficial to provide an additional quantity serving as a refined measure of distributional difference. In this work, we introduce a framework for the construction of high-probability lower bounds on the total variation distance. These bounds are based on a one-dimensional projection, such as a classification or regression method, and can be interpreted as the minimal fraction of samples pointing towards a distributional difference. We further derive asymptotic power and detection rates of two proposed estimators and discuss potential uses through an application to a reanalysis climate dataset.
翻译:最近,统计和机器学习界对基于分类的两样样测试方法(例如Kim等人([2016];Rosenblatt等人([2016];Lopez-Paz和Oquab[2017]);Hediger等人([2019]))的兴趣日益浓厚。基于分类的两样样样测试的结果仍然是拒绝决定,这并非总能提供信息,因为完全无效的假设很少是绝对的。因此,当测试被拒绝时,最好提供额外数量,作为精确的分布差异衡量尺度。在这项工作中,我们引入了一个框架,用于构建全变异距离的高概率下限。这些界限以单维预测为基础,如分类或回归方法,可被解释为指向分布差异的样本的最小部分。我们进一步从两个拟议估算器的微量能量和检测率中提取,并通过对气候数据集进行再分析来讨论潜在用途。