【论文推荐】最新六篇视频分类相关论文—教师学生网络、表观-关系、Charades-Ego、视觉数据合成、图蒸馏、细粒度视频分类
【导读】专知内容组为大家推出最新六篇视频分类(Video Classification)相关论文,欢迎查看!
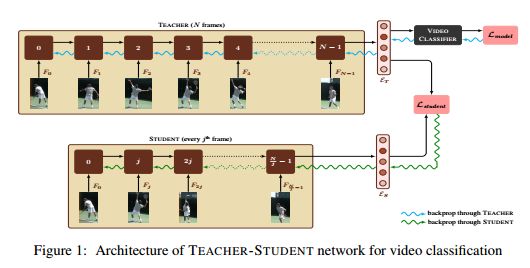
1.I Have Seen Enough: A Teacher Student Network for Video Classification Using Fewer Frames(I Have Seen Enough:利用教师学生网络使用更少的帧进行视频分类)
作者:Shweta Bhardwaj,Mitesh M. Khapra
CVPR Workshop on Brave New Ideas for Video Understanding (BIVU)
摘要:Over the past few years, various tasks involving videos such as classification, description, summarization and question answering have received a lot of attention. Current models for these tasks compute an encoding of the video by treating it as a sequence of images and going over every image in the sequence. However, for longer videos this is very time consuming. In this paper, we focus on the task of video classification and aim to reduce the computational time by using the idea of distillation. Specifically, we first train a teacher network which looks at all the frames in a video and computes a representation for the video. We then train a student network whose objective is to process only a small fraction of the frames in the video and still produce a representation which is very close to the representation computed by the teacher network. This smaller student network involving fewer computations can then be employed at inference time for video classification. We experiment with the YouTube-8M dataset and show that the proposed student network can reduce the inference time by upto 30% with a very small drop in the performance
期刊:arXiv, 2018年5月12日
网址:
http://www.zhuanzhi.ai/document/2e238a793c8db4a8aa0e57020adc17e6
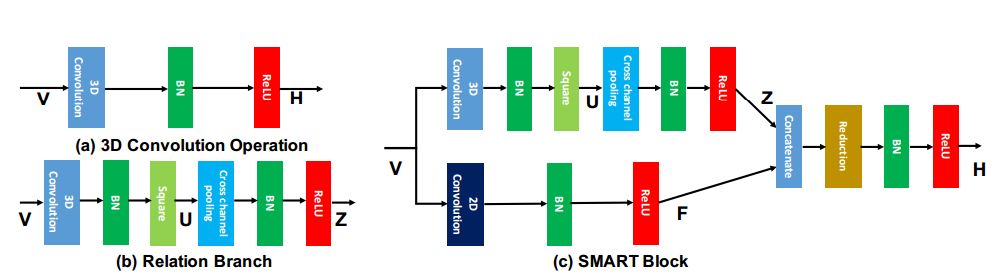
2.Appearance-and-Relation Networks for Video Classification(表观-关系视频分类网络)
作者:Limin Wang,Wei Li,Wen Li,Luc Van Gool
CVPR18 camera-ready version. Code & models available at https://github.com/wanglimin/ARTNet
机构:, Nanjing University
摘要:Spatiotemporal feature learning in videos is a fundamental problem in computer vision. This paper presents a new architecture, termed as Appearance-and-Relation Network (ARTNet), to learn video representation in an end-to-end manner. ARTNets are constructed by stacking multiple generic building blocks, called as SMART, whose goal is to simultaneously model appearance and relation from RGB input in a separate and explicit manner. Specifically, SMART blocks decouple the spatiotemporal learning module into an appearance branch for spatial modeling and a relation branch for temporal modeling. The appearance branch is implemented based on the linear combination of pixels or filter responses in each frame, while the relation branch is designed based on the multiplicative interactions between pixels or filter responses across multiple frames. We perform experiments on three action recognition benchmarks: Kinetics, UCF101, and HMDB51, demonstrating that SMART blocks obtain an evident improvement over 3D convolutions for spatiotemporal feature learning. Under the same training setting, ARTNets achieve superior performance on these three datasets to the existing state-of-the-art methods.
期刊:arXiv, 2018年5月6日
网址:
http://www.zhuanzhi.ai/document/c945693806904a2b6c3c3bcf021acca8
3.Charades-Ego: A Large-Scale Dataset of Paired Third and First Person Videos(Charades-Ego:由配对的第三人称和第一人称视频组成的一个大型数据集)
作者:Gunnar A. Sigurdsson,Abhinav Gupta,Cordelia Schmid,Ali Farhadi,Karteek Alahar
摘要:In Actor and Observer we introduced a dataset linking the first and third-person video understanding domains, the Charades-Ego Dataset. In this paper we describe the egocentric aspect of the dataset and present annotations for Charades-Ego with 68,536 activity instances in 68.8 hours of first and third-person video, making it one of the largest and most diverse egocentric datasets available. Charades-Ego furthermore shares activity classes, scripts, and methodology with the Charades dataset, that consist of additional 82.3 hours of third-person video with 66,500 activity instances. Charades-Ego has temporal annotations and textual descriptions, making it suitable for egocentric video classification, localization, captioning, and new tasks utilizing the cross-modal nature of the data.

期刊:arXiv, 2018年5月1日
网址:
http://www.zhuanzhi.ai/document/b3d218000dc923a6a5900bacdafd5772
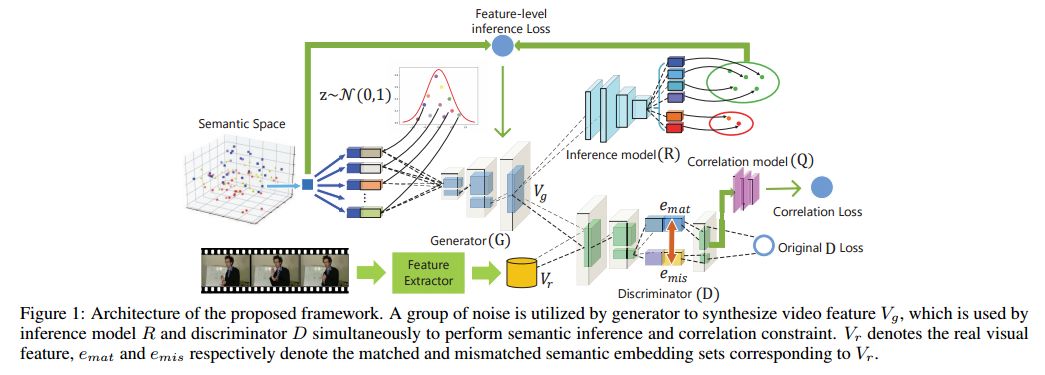
4.Visual Data Synthesis via GAN for Zero-Shot Video Classification(通过GAN进行视觉数据合成进行视频零样本分类)
作者:Chenrui Zhang,Yuxin Peng
accepted by International Joint Conference on Artificial Intelligence (IJCAI) 2018
机构:Peking University
摘要:Zero-Shot Learning (ZSL) in video classification is a promising research direction, which aims to tackle the challenge from explosive growth of video categories. Most existing methods exploit seen-to-unseen correlation via learning a projection between visual and semantic spaces. However, such projection-based paradigms cannot fully utilize the discriminative information implied in data distribution, and commonly suffer from the information degradation issue caused by "heterogeneity gap". In this paper, we propose a visual data synthesis framework via GAN to address these problems. Specifically, both semantic knowledge and visual distribution are leveraged to synthesize video feature of unseen categories, and ZSL can be turned into typical supervised problem with the synthetic features. First, we propose multi-level semantic inference to boost video feature synthesis, which captures the discriminative information implied in joint visual-semantic distribution via feature-level and label-level semantic inference. Second, we propose Matching-aware Mutual Information Correlation to overcome information degradation issue, which captures seen-to-unseen correlation in matched and mismatched visual-semantic pairs by mutual information, providing the zero-shot synthesis procedure with robust guidance signals. Experimental results on four video datasets demonstrate that our approach can improve the zero-shot video classification performance significantly.
期刊:arXiv, 2018年4月26日
网址:
http://www.zhuanzhi.ai/document/4ea8bdde291c58c698466e51a8d24c11
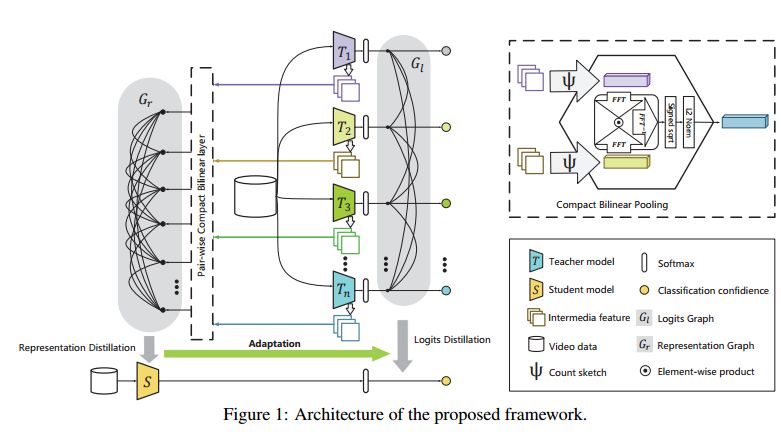
5.Better and Faster: Knowledge Transfer from Multiple Self-supervised Learning Tasks via Graph Distillation for Video Classification(Better and Faster:知识从多个自监督学习任务通过图蒸馏转移到视频分类)
作者:Chenrui Zhang,Yuxin Peng
accepted by International Joint Conference on Artificial Intelligence (IJCAI) 2018
机构:Peking University
摘要:Video representation learning is a vital problem for classification task. Recently, a promising unsupervised paradigm termed self-supervised learning has emerged, which explores inherent supervisory signals implied in massive data for feature learning via solving auxiliary tasks. However, existing methods in this regard suffer from two limitations when extended to video classification. First, they focus only on a single task, whereas ignoring complementarity among different task-specific features and thus resulting in suboptimal video representation. Second, high computational and memory cost hinders their application in real-world scenarios. In this paper, we propose a graph-based distillation framework to address these problems: (1) We propose logits graph and representation graph to transfer knowledge from multiple self-supervised tasks, where the former distills classifier-level knowledge by solving a multi-distribution joint matching problem, and the latter distills internal feature knowledge from pairwise ensembled representations with tackling the challenge of heterogeneity among different features; (2) The proposal that adopts a teacher-student framework can reduce the redundancy of knowledge learnt from teachers dramatically, leading to a lighter student model that solves classification task more efficiently. Experimental results on 3 video datasets validate that our proposal not only helps learn better video representation but also compress model for faster inference.
期刊:arXiv, 2018年4月26日
网址:
http://www.zhuanzhi.ai/document/ac2c40c7a76dc3f1495f0981c6f8affd
6.Fine-grained Video Classification and Captioning(细粒度视频分类和描述生成)
作者:Farzaneh Mahdisoltani,Guillaume Berger,Waseem Gharbieh,David Fleet,Roland Memisevic
机构:University of Toronto
摘要:We describe a DNN for fine-grained action classification and video captioning. It gives state-of-the-art performance on the challenging Something-Something dataset, with over 220, 000 videos and 174 fine-grained actions. Classification and captioning on this dataset are challenging because of the subtle differences between actions, the use of thousands of different objects, and the diversity of captions penned by crowd actors. The model architecture shares features for classification and captioning, and is trained end-to-end. It performs much better than the existing classification benchmark for Something-Something, with impressive fine-grained results, and it yields a strong baseline on the new Something-Something captioning task. Our results reveal that there is a strong correlation between the degree of detail in the task and the ability of the learned features to transfer to other tasks.

期刊:arXiv, 2018年4月25日
网址:
http://www.zhuanzhi.ai/document/3bcf0f7c4788e02c8c9fd5459803465b
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取。欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知


