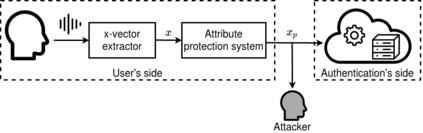
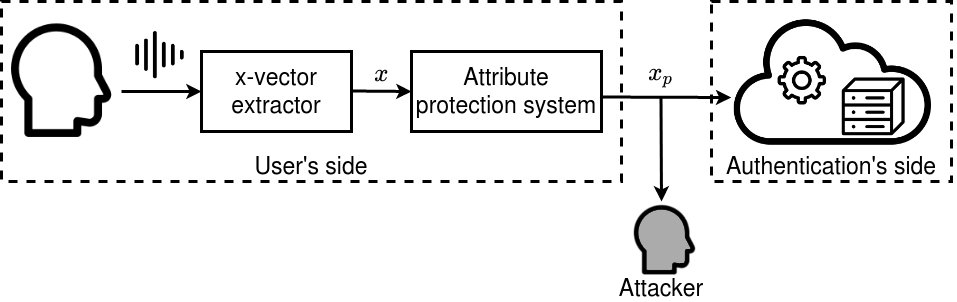
In speech technologies, speaker's voice representation is used in many applications such as speech recognition, voice conversion, speech synthesis and, obviously, user authentication. Modern vocal representations of the speaker are based on neural embeddings. In addition to the targeted information, these representations usually contain sensitive information about the speaker, like the age, sex, physical state, education level or ethnicity. In order to allow the user to choose which information to protect, we introduce in this paper the concept of attribute-driven privacy preservation in speaker voice representation. It allows a person to hide one or more personal aspects to a potential malicious interceptor and to the application provider. As a first solution to this concept, we propose to use an adversarial autoencoding method that disentangles in the voice representation a given speaker attribute thus allowing its concealment. We focus here on the sex attribute for an Automatic Speaker Verification (ASV) task. Experiments carried out using the VoxCeleb datasets have shown that the proposed method enables the concealment of this attribute while preserving ASV ability.
翻译:在语言技术中,许多应用软件,如语音识别、语音转换、语音合成和显然用户认证,都使用了发言者的语音代表,现代发言者的语音代表基于神经嵌入。除了有针对性的信息外,这些代表通常包含关于发言者的敏感信息,如年龄、性别、身体状态、教育水平或族裔等。为了让用户选择需要保护的信息,我们在本文件中引入了语音代表中以属性驱动的隐私保护概念。它允许一个人向潜在的恶意截取器和应用提供者隐藏一个或多个个人方面。作为这一概念的第一个解决方案,我们提议使用对抗性自动编码方法,在特定发言者的语音代表属性中解密,从而允许隐藏该属性。我们在此侧重于自动语音验证任务的性别属性。使用VoxCeleb数据集进行的实验表明,拟议方法有助于隐藏这一属性,同时保持ASV的能力。