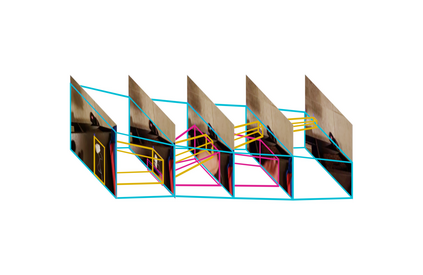
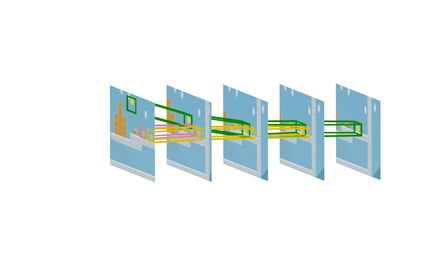
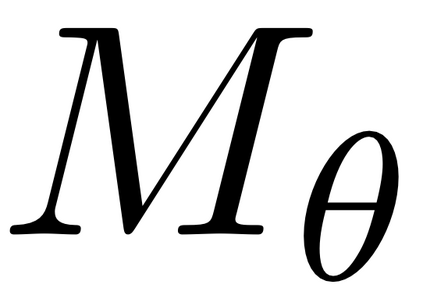We propose LASER, a neuro-symbolic approach to learn semantic video representations that capture rich spatial and temporal properties in video data by leveraging high-level logic specifications. In particular, we formulate the problem in terms of alignment between raw videos and spatio-temporal logic specifications. The alignment algorithm leverages a differentiable symbolic reasoner and a combination of contrastive, temporal, and semantics losses. It effectively and efficiently trains low-level perception models to extract fine-grained video representation in the form of a spatio-temporal scene graph that conforms to the desired high-level specification. In doing so, we explore a novel methodology that weakly supervises the learning of video semantic representations through logic specifications. We evaluate our method on two datasets with rich spatial and temporal specifications: 20BN-Something-Something and MUGEN. We demonstrate that our method learns better fine-grained video semantics than existing baselines.
翻译:暂无翻译