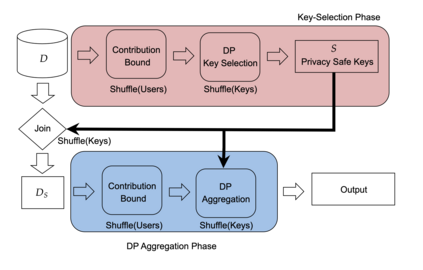
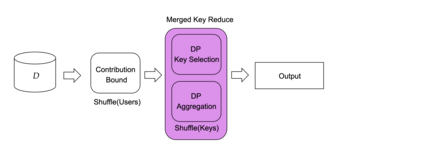
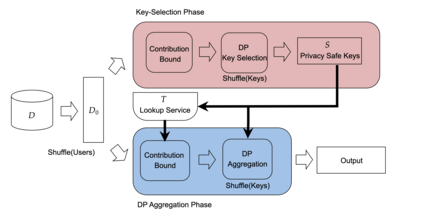
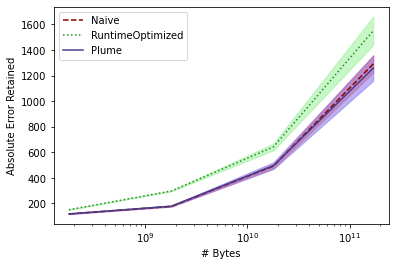
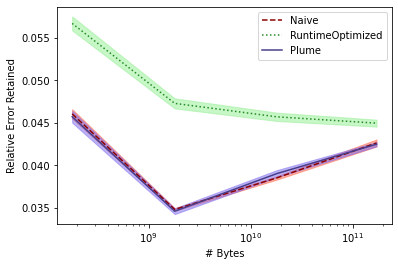
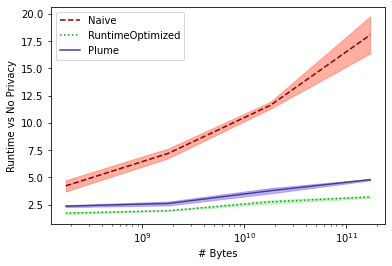
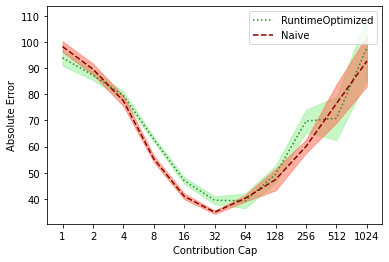
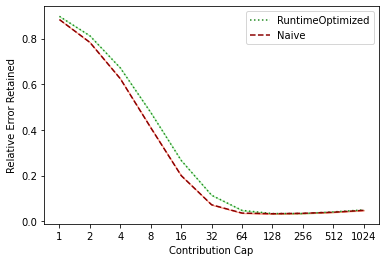
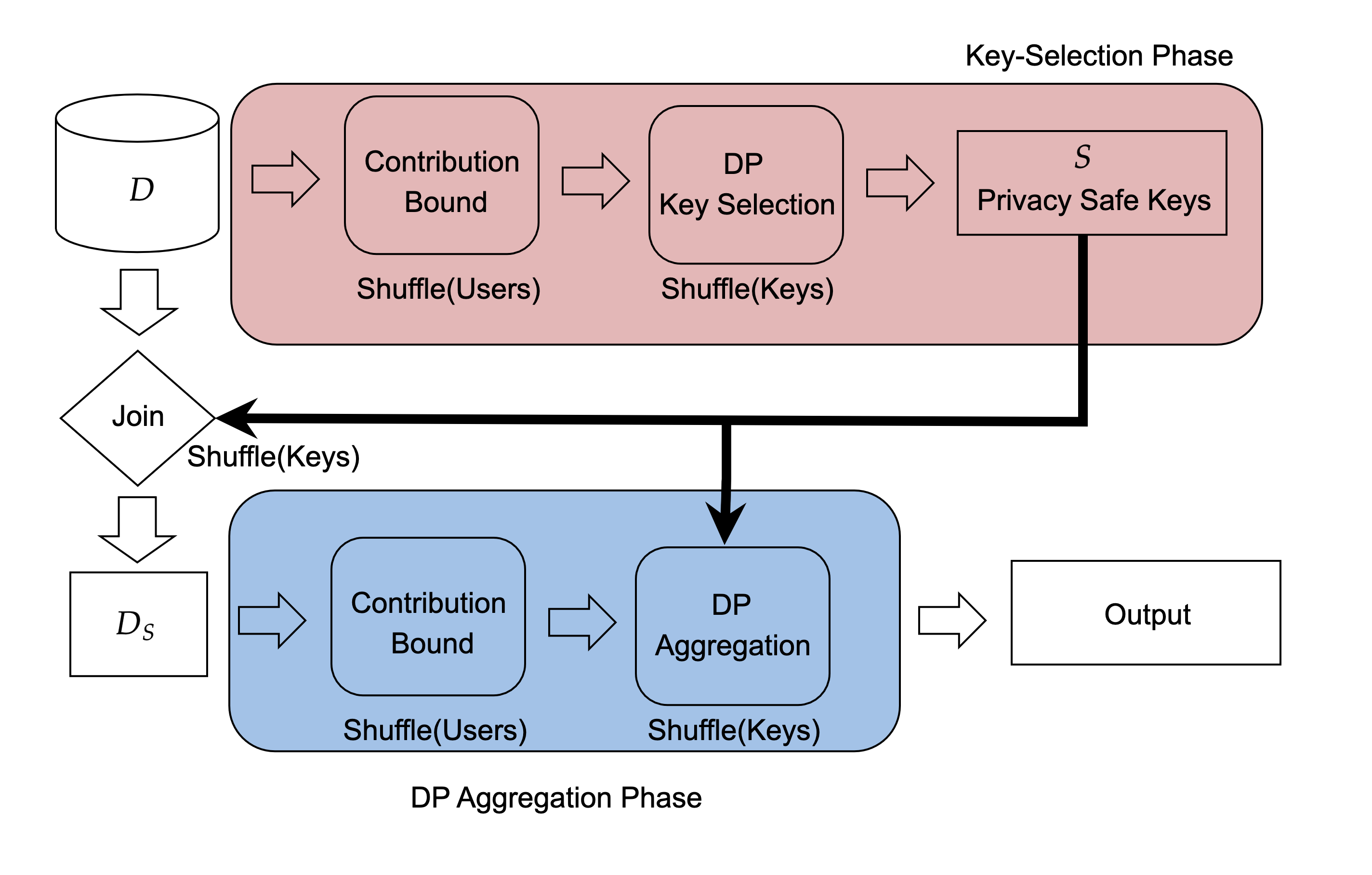
Differential privacy has become the standard for private data analysis, and an extensive literature now offers differentially private solutions to a wide variety of problems. However, translating these solutions into practical systems often requires confronting details that the literature ignores or abstracts away: users may contribute multiple records, the domain of possible records may be unknown, and the eventual system must scale to large volumes of data. Failure to carefully account for all three issues can severely impair a system's quality and usability. We present Plume, a system built to address these problems. We describe a number of sometimes subtle implementation issues and offer practical solutions that, together, make an industrial-scale system for differentially private data analysis possible. Plume is currently deployed at Google and is routinely used to process datasets with trillions of records.
翻译:隐私差异已成为私人数据分析的标准,大量文献现在为各种各样的问题提供了不同的私人解决方案。然而,将这些解决方案转化为实际系统往往需要正面的细节,而文献忽略或摘录这些细节:用户可以提供多种记录,可能的记录领域可能未知,最终的系统必须扩大到大量数据。如果不对所有这三个问题进行仔细的核算,就会严重损害系统的质量和可用性。我们介绍了普卢姆,这是一个为解决这些问题而建立的系统。我们描述了一些有时微妙的执行问题,并提供实用的解决办法,共同使工业规模的系统能够进行差异性私人数据分析。普卢目前部署在谷歌,并经常用于处理带有数万亿个记录的数据集。