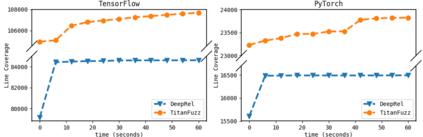
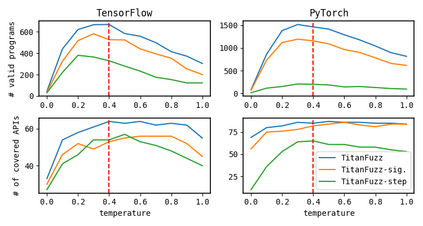
Detecting bugs in Deep Learning (DL) libraries (e.g., TensorFlow/PyTorch) is critical for almost all downstream DL systems in ensuring effectiveness/safety for end users. Meanwhile, traditional fuzzing techniques can be hardly effective for such a challenging domain since the input DL programs need to satisfy both the input language (e.g., Python) syntax/semantics and the DL API input/shape constraints for tensor computations. To address these limitations, we propose TitanFuzz - the first approach to directly leveraging Large Language Models (LLMs) to generate input programs for fuzzing DL libraries. LLMs are titanic models trained on billions of code snippets and can auto-regressively generate human-like code snippets. Our key insight is that modern LLMs can also include numerous code snippets invoking DL library APIs in their training corpora, and thus can implicitly learn both language syntax/semantics and intricate DL API constraints for valid DL program generation. More specifically, we use both generative and infilling LLMs (e.g., Codex/InCoder) to generate and mutate valid/diverse input DL programs for fuzzing. Our experimental results demonstrate that TitanFuzz can achieve 30.38%/50.84% higher code coverage than state-of-the-art fuzzers on TensorFlow/PyTorch. Furthermore, TitanFuzz is able to detect 65 bugs, with 41 already confirmed as previously unknown bugs. This paper demonstrates that modern titanic LLMs can be leveraged to directly perform both generation-based and mutation-based fuzzing studied for decades, while being fully automated, generalizable, and applicable to domains challenging for traditional approaches (such as DL systems). We hope TitanFuzz can stimulate more work in this promising direction of LLMs for fuzzing.
翻译:深学习( DL) 库( 例如, TensorFlow/ PyTorrch) 的检测错误对于几乎所有下游 DL 系统确保终端用户的效能/安全至关重要。 同时, 传统的模糊技术对于如此具有挑战性的域来说几乎难以有效, 因为输入 DL 程序需要既满足输入语言( 例如 Python) 的语法/ 语法和 DL ASI 输入/ shape 限制来计算 。 为解决这些限制, 我们建议 TitanFuzz - 直接利用大语言模型( LLMS) 来生成输入程序, 用于为 DL 库创建 florm 。 更具体地说, 输入 IMLMS 是要在数据库中直接使用许多代码片断, 引用 DL 库 API 的语法, 并且可以隐含地将语言的语法化/ URPI 的语法和复杂的 DLPI 限制用于有效的 DLDL 程序生成。 IMD 。 更具体地说, 我们既要同时使用磁性地使用磁体,,, 也用LDLDMs 。</s>