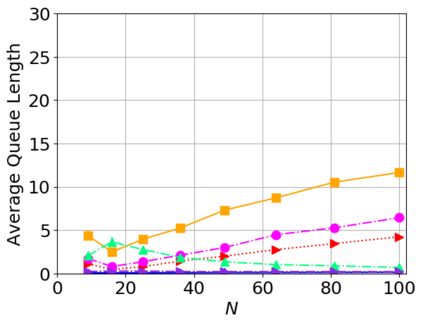
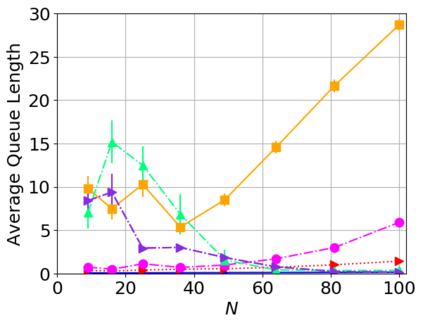
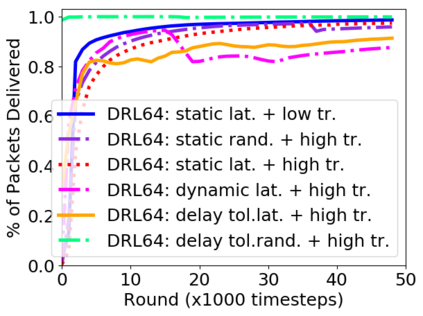
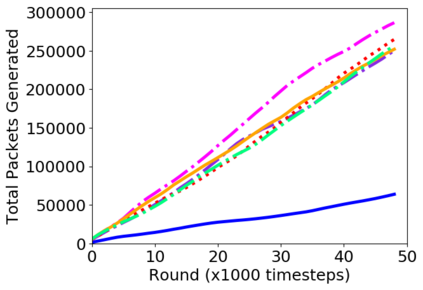
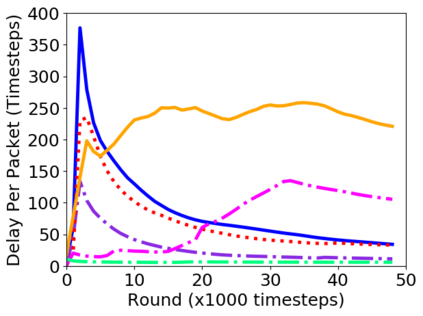
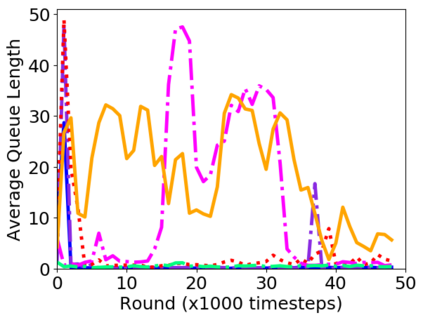
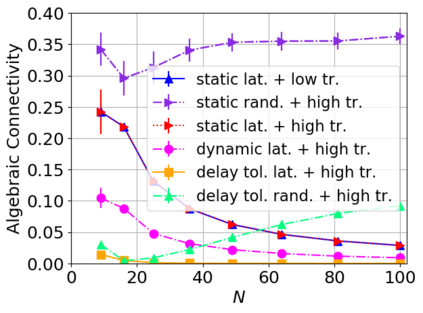
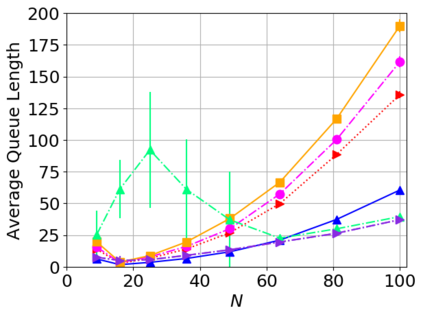
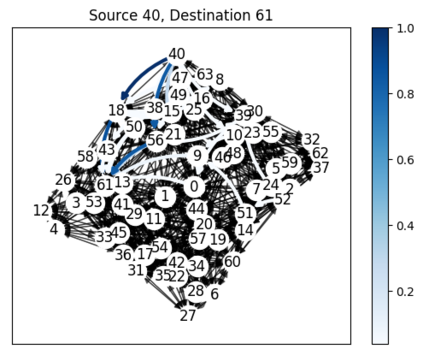
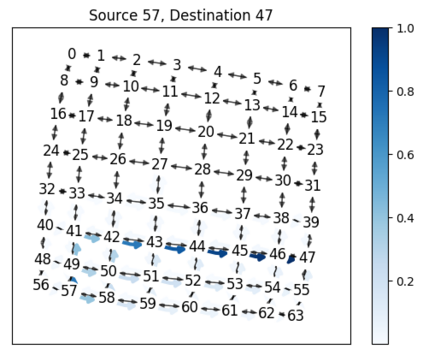
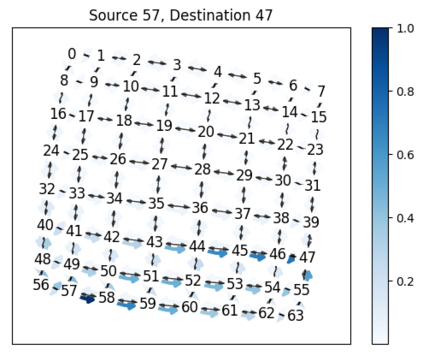
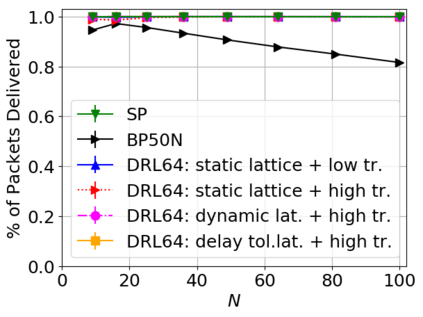
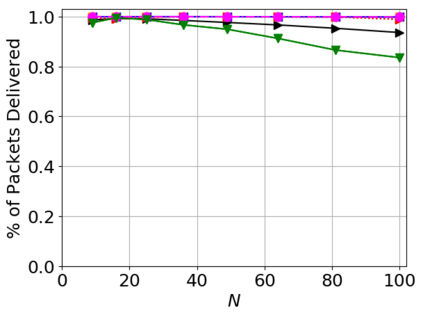
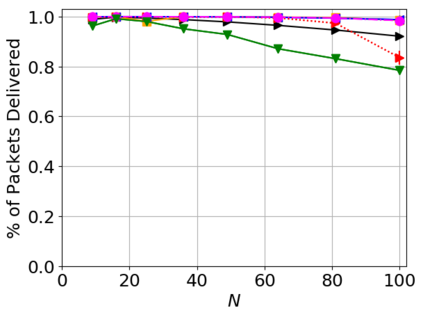
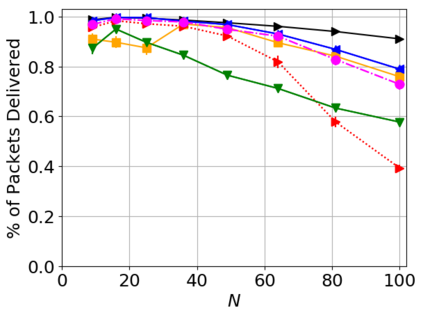
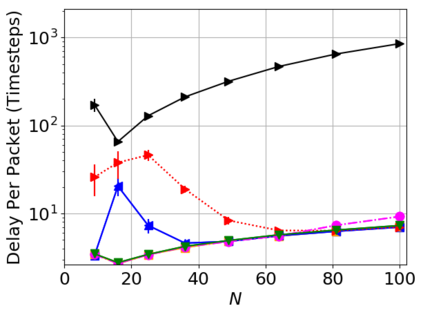
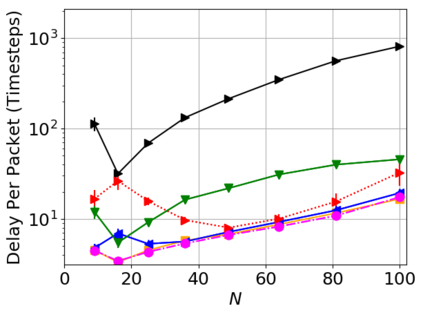
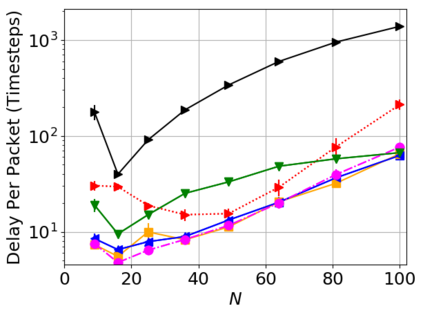
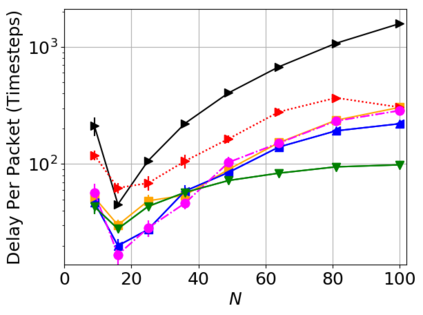
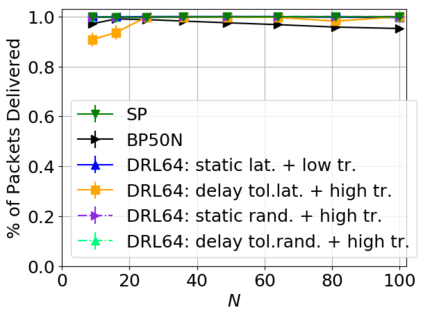
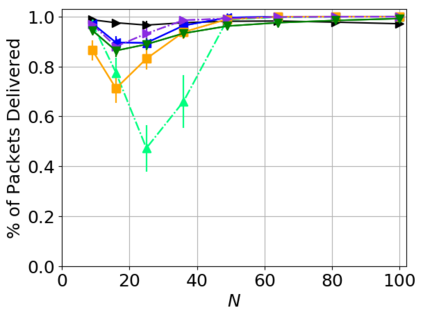
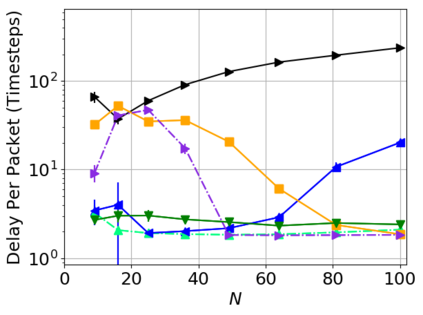
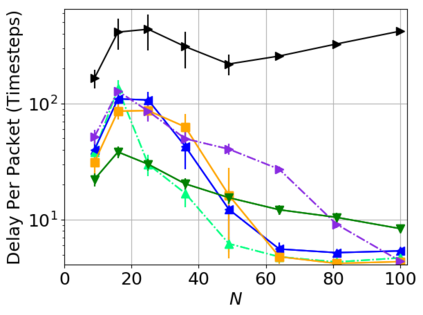
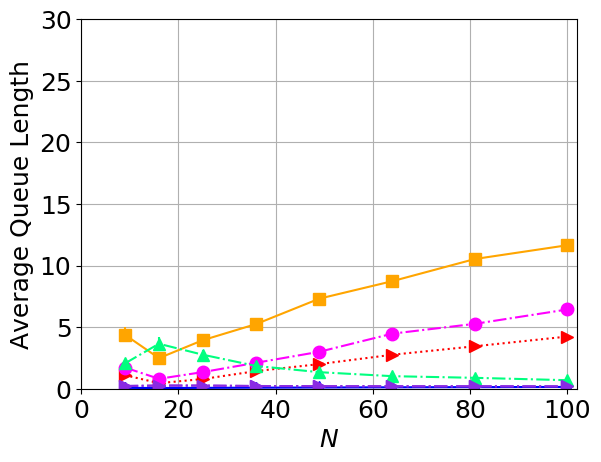
While routing in wireless networks has been studied extensively, existing protocols are typically designed for a specific set of network conditions and so cannot accommodate any drastic changes in those conditions. For instance, protocols designed for connected networks cannot be easily applied to disconnected networks. In this paper, we develop a distributed routing strategy based on deep reinforcement learning that generalizes to diverse traffic patterns, congestion levels, network connectivity, and link dynamics. We make the following key innovations in our design: (i) the use of relational features as inputs to the deep neural network approximating the decision space, which enables our algorithm to generalize to diverse network conditions, (ii) the use of packet-centric decisions to transform the routing problem into an episodic task by viewing packets, rather than wireless devices, as reinforcement learning agents, which provides a natural way to propagate and model rewards accurately during learning, and (iii) the use of extended-time actions to model the time spent by a packet waiting in a queue, which reduces the amount of training data needed and allows the learning algorithm to converge more quickly. We evaluate our routing algorithm using a packet-level simulator and show that the policy our algorithm learns during training is able to generalize to larger and more congested networks, different topologies, and diverse link dynamics. Our algorithm outperforms shortest path and backpressure routing with respect to packets delivered and delay per packet.
翻译:虽然对无线网络的路线进行了广泛的研究,但现有的协议通常是为了特定的一组网络条件而设计的,因此无法适应这些条件的任何急剧变化。例如,为连接网络设计的协议无法轻易地应用于断开的网络。在本文件中,我们根据深度强化学习,制定了分布式路线战略,它概括了不同的交通模式、拥堵水平、网络连通性和链接动态。我们在设计中做了以下关键创新:(一) 将关系特征用作与决定空间相近的深层神经网络的投入,使我们的算法能够概括到不同的网络条件,(二) 使用包心型决定将路径问题转化为一个附带的任务,办法是查看包包,而不是无线设备,作为强化学习工具,提供自然的方式在学习期间传播和模型准确奖励,以及(三) 使用延长时间行动模拟等待的包包所花的时间,从而减少了所需的培训数据数量,并使学习算法能够更快地结合我们不同的网络,我们用更大型的、更多样化的、更多样化的分类的、更多样化的机算法来评估我们的路运算,在一般的、更多样化的机率上学习更能的路径和显示过程中,在一般的机上,我们用更多样化的机能的机能和显示和显示中,以学习一个更精制的机学。