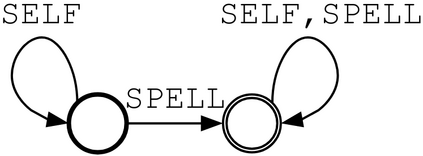
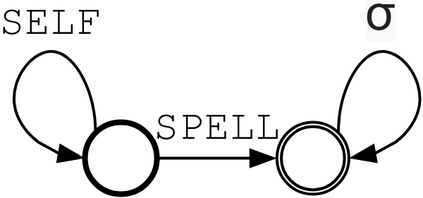
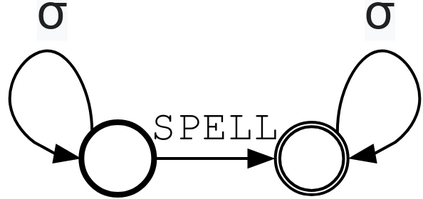
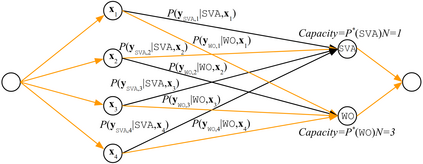
Synthetic data generation is widely known to boost the accuracy of neural grammatical error correction (GEC) systems, but existing methods often lack diversity or are too simplistic to generate the broad range of grammatical errors made by human writers. In this work, we use error type tags from automatic annotation tools such as ERRANT to guide synthetic data generation. We compare several models that can produce an ungrammatical sentence given a clean sentence and an error type tag. We use these models to build a new, large synthetic pre-training data set with error tag frequency distributions matching a given development set. Our synthetic data set yields large and consistent gains, improving the state-of-the-art on the BEA-19 and CoNLL-14 test sets. We also show that our approach is particularly effective in adapting a GEC system, trained on mixed native and non-native English, to a native English test set, even surpassing real training data consisting of high-quality sentence pairs.
翻译:合成数据生成广为人知,可以提高神经语法错误校正系统(GEC)的准确性,但现有方法往往缺乏多样性,或过于简单,无法产生人类作家造成的广泛的语法错误。在这项工作中,我们使用诸如ERRANT等自动注解工具的错误类型标记来指导合成数据生成。我们比较了能够产生非语法句的几种模型,给出了干净的句子和差错类型标记。我们用这些模型来建立一个新的大型培训前合成数据集,配有与特定开发数据集相匹配的错误标签频率分布。我们的合成数据集产生大量一致的成果,改善了BEA-19和CONLLL-14测试集上的最新工艺。我们还表明,我们的方法特别有效,将GEC系统(受过本地和非本地混合英语培训)与本地英语测试集相适应,甚至超过了由高质量词组组成的真正培训数据。