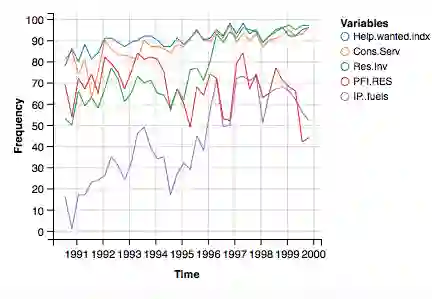
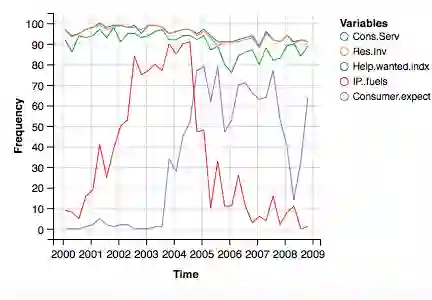
Interpretability and stability are two important features that are desired in many contemporary big data applications arising in economics and finance. While the former is enjoyed to some extent by many existing forecasting approaches, the latter in the sense of controlling the fraction of wrongly discovered features which can enhance greatly the interpretability is still largely underdeveloped in the econometric settings. To this end, in this paper we exploit the general framework of model-X knockoffs introduced recently in Cand\`{e}s, Fan, Janson and Lv (2018), which is nonconventional for reproducible large-scale inference in that the framework is completely free of the use of p-values for significance testing, and suggest a new method of intertwined probabilistic factors decoupling (IPAD) for stable interpretable forecasting with knockoffs inference in high-dimensional models. The recipe of the method is constructing the knockoff variables by assuming a latent factor model that is exploited widely in economics and finance for the association structure of covariates. Our method and work are distinct from the existing literature in that we estimate the covariate distribution from data instead of assuming that it is known when constructing the knockoff variables, our procedure does not require any sample splitting, we provide theoretical justifications on the asymptotic false discovery rate control, and the theory for the power analysis is also established. Several simulation examples and the real data analysis further demonstrate that the newly suggested method has appealing finite-sample performance with desired interpretability and stability compared to some popularly used forecasting methods.
翻译:解释性和稳定性是当代经济和金融领域许多大数据应用中所希望的两个重要特点。虽然许多现有预测方法在某种程度上享有前者,但后者是指控制错误发现的、可大大提高可解释性的特征的一小部分,在计量经济学环境中,这些特征在很大程度上仍然不够完善。为此,在本文件中,我们利用最近在Cand ⁇ e}s、Fan、Janson和Lv(2018年)引入的模型-X决裂总框架,这是可复制的大尺度推断的非常规,因为该框架完全没有使用P值进行重大预测,而后者是指控制那些可大大加强解释性特征的错误发现特征的分数;为此,我们利用最近在Cand ⁇ e}s、Fan、Janson和Lv(2018年)引入的模型-X决裂总框架,这个框架是非常规的,它与现有的文献不同,因为我们从数据中估算可互换性值的分布完全不使用P-值进行重大预测,而从中提出了一种相互交织的概率因素的新方法(IPAD)的新方法,而我们则认为,在构建精确的模型分析时,我们并不需要解释任何精确的精确的精确的模型,因此需要解释。