

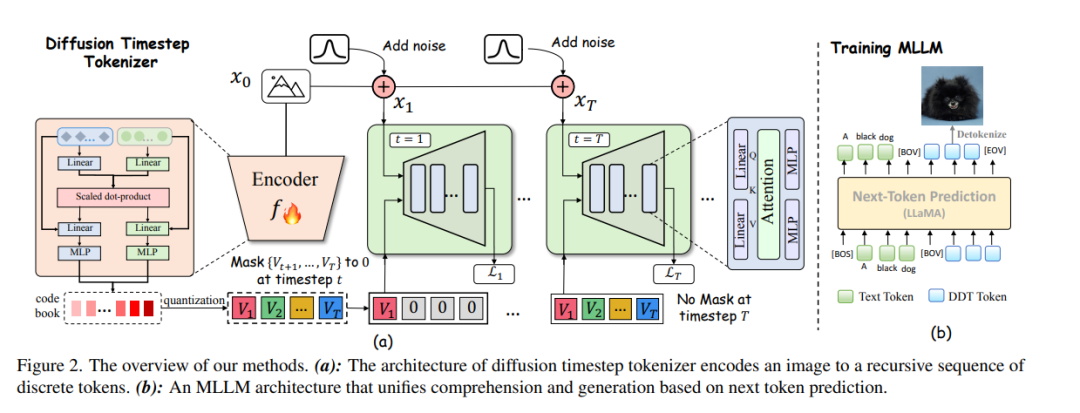
近期在多模态大型语言模型(MLLMs)领域的研究致力于通过结合大型语言模型(LLM)与扩散模型(分别在各自任务中处于最先进水平),实现视觉理解与生成的统一。现有方法通常依赖于空间视觉令牌,即将图像块编码后按照空间顺序(例如光栅扫描顺序)排列。然而,我们指出,空间令牌缺乏语言中固有的递归结构,因此形成了一种大型语言模型难以掌握的“不可学习语言”。 在本文中,我们通过利用扩散时间步来学习离散的、递归的视觉令牌,从而构建了一种合适的视觉语言。我们提出的视觉令牌能够递归地补偿在噪声图像中随时间步增加而逐步丧失的属性,使扩散模型能够在任意时间步重建原始图像。这一方法使我们能够有效整合大型语言模型在自回归推理方面的优势与扩散模型在精确图像生成方面的优势,在统一框架内实现无缝的多模态理解与生成。 大量实验表明,我们在多模态理解与生成任务上同时达到了优于其他MLLMs的方法性能。项目页面:https://DDTLLaMA.github.io/
成为VIP会员查看完整内容
相关内容
Arxiv
38+阅读 · 2023年4月19日
Arxiv
205+阅读 · 2023年4月7日
Arxiv
20+阅读 · 2023年3月21日
相关VIP内容
相关资讯
相关论文
Arxiv
38+阅读 · 2023年4月19日
Arxiv
205+阅读 · 2023年4月7日
Arxiv
20+阅读 · 2023年3月21日