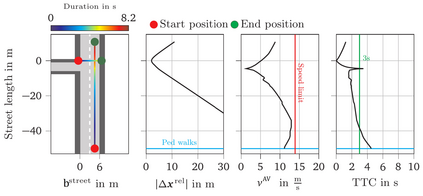
Reliable pedestrian crash avoidance mitigation (PCAM) systems are crucial components of safe autonomous vehicles (AVs). The sequential nature of the vehicle-pedestrian interaction, i.e., where immediate decisions of one agent directly influence the following decisions of the other agent, is an often neglected but important aspect. In this work, we model the corresponding interaction sequence as a Markov decision process (MDP) that is solved by deep reinforcement learning (DRL) algorithms to define the PCAM system's policy. The simulated driving scenario is based on an AV acting as a DRL agent driving along an urban street, facing a pedestrian at an unmarked crosswalk who tries to cross. Since modeling realistic crossing behavior of the pedestrian is challenging, we introduce two levels of intelligent pedestrian behavior: While the baseline model follows a predefined strategy, our advanced model captures continuous learning and the inherent uncertainty in human behavior by defining the pedestrian as a second DRL agent, i.e., we introduce a deep multi-agent reinforcement learning (DMARL) problem. The presented PCAM system with different levels of intelligent pedestrian behavior is benchmarked according to the agents' collision rate and the resulting traffic flow efficiency. In this analysis, our focus lies on evaluating the influence of observation noise on the decision making of the agents. The results show that the AV is able to completely mitigate collisions under the majority of the investigated conditions and that the DRL-based pedestrian model indeed learns a more human-like crossing behavior.
翻译:可靠的避免行人碰撞系统(PCAM)是安全自主车辆(AV)的关键组成部分。车辆行人互动的顺序性质,即一个代理商直接直接影响到另一代理商的下列决定,是一个往往被忽视但重要的方面。在这项工作中,我们将相应的互动序列建为Markov决策程序(MDP),通过深强化学习算法(DRL)算法来界定CASM系统的政策来解决。模拟驾驶假方案的基础是AV作为DRL代理商在城市街道上驾驶的DRL代理商,面对一个在无标志十字路口的行人,试图跨越。由于模拟行人的现实过境行为具有挑战性,我们引入了两个层次的智能行人行为:虽然基线模型遵循预先确定的战略,但我们的先进模型通过将行人定义为第二个DRM(DR)代理商(DR)算算法来解决,即我们引入了一种深层次多剂强化学习(DMARL)问题。我们介绍的具有不同层次智能行人行为的系统,其智能行人行为标准是根据代理商的跨行人行为速度速度速度速度速度速度比率,从而评估AL的轨道测量结果。