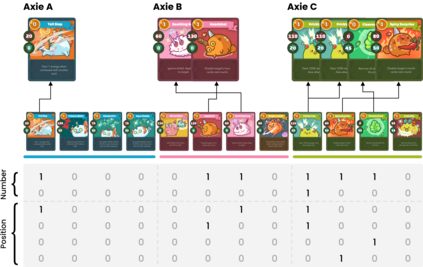
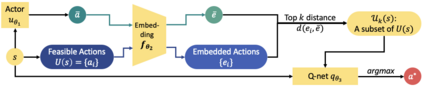
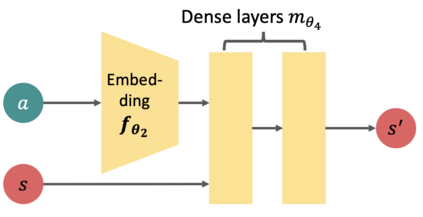
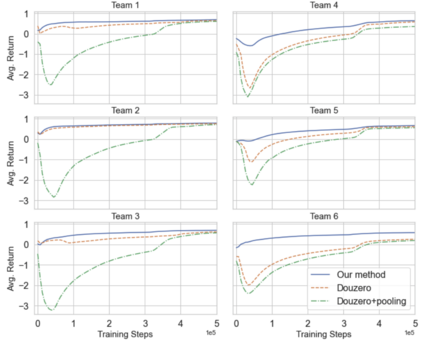
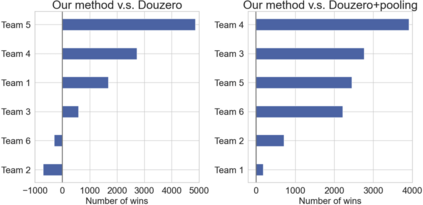
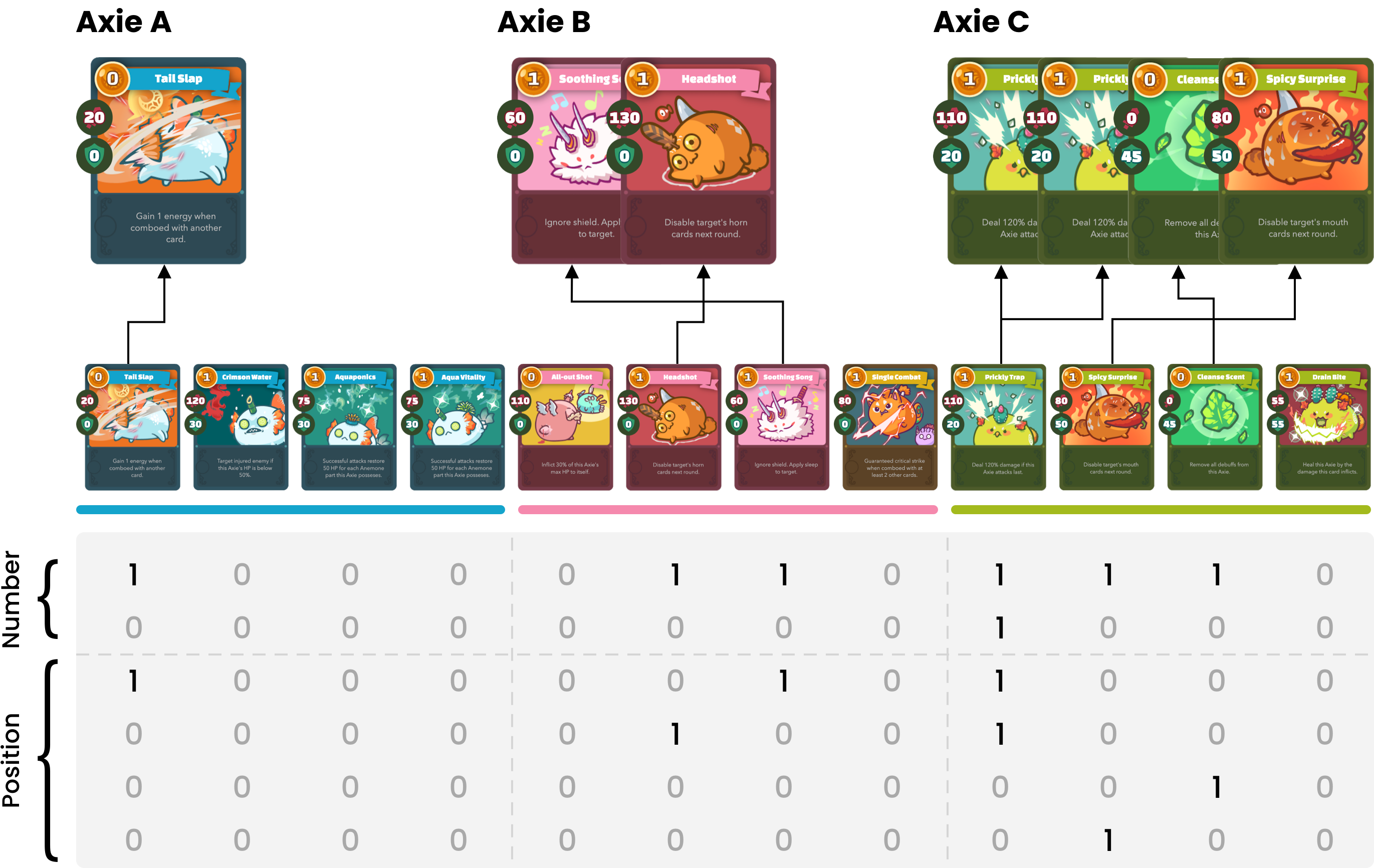
Axie infinity is a complicated card game with a huge-scale action space. This makes it difficult to solve this challenge using generic Reinforcement Learning (RL) algorithms. We propose a hybrid RL framework to learn action representations and game strategies. To avoid evaluating every action in the large feasible action set, our method evaluates actions in a fixed-size set which is determined using action representations. We compare the performance of our method with the other two baseline methods in terms of their sample efficiency and the winning rates of the trained models. We empirically show that our method achieves an overall best winning rate and the best sample efficiency among the three methods.
翻译:轴无穷是一个复杂的纸牌游戏,具有巨大的行动空间。 这使得使用通用的加强学习算法难以解决这一挑战。 我们提议了一个混合的RL框架, 学习行动表现和游戏策略。 为避免评估大型可行行动组合中的每一项行动, 我们的方法用固定规模来评价行动, 固定规模由行动表示法决定。 我们比较了我们的方法与其他两种基线方法的性能, 从其抽样效率和经过培训的模式的得分率来看。 我们的经验显示,我们的方法在三种方法中取得了总体最佳的胜出率和最佳的抽样效率。