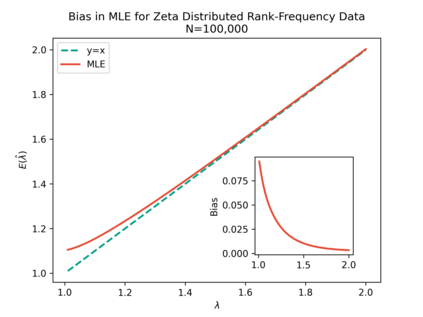
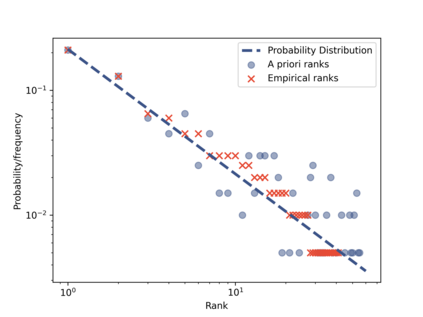
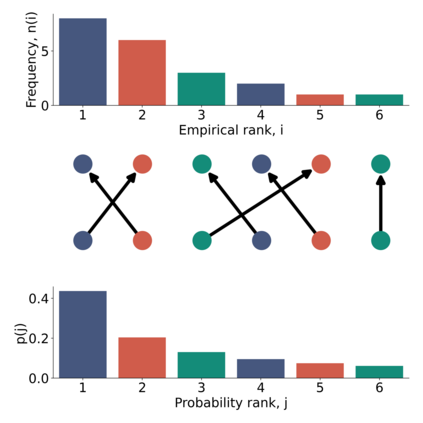
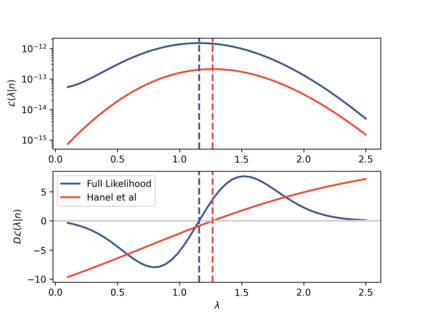
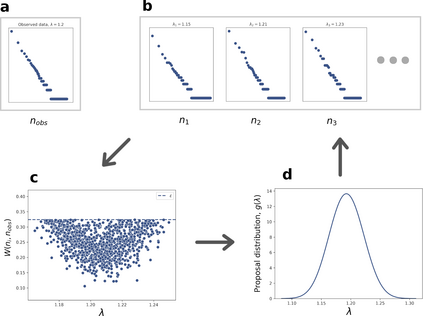
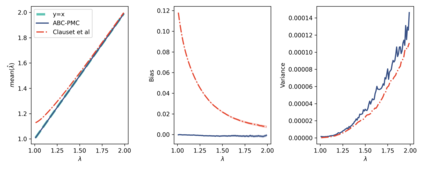
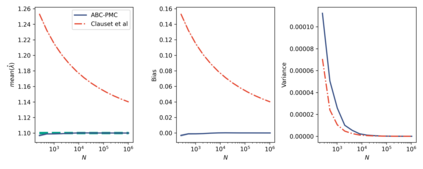
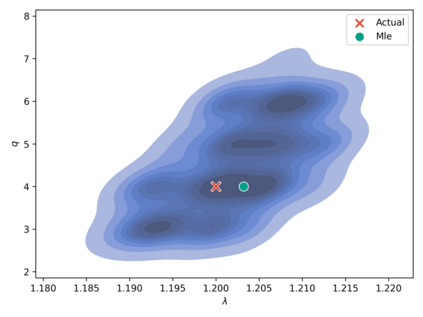
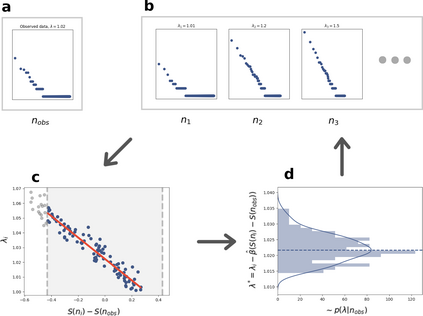
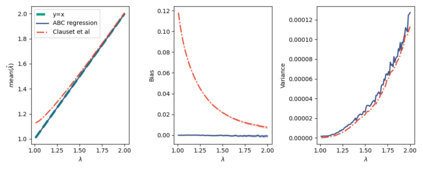
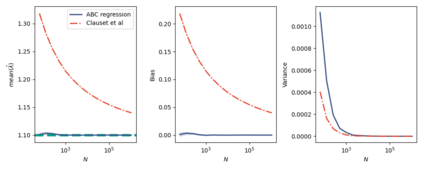
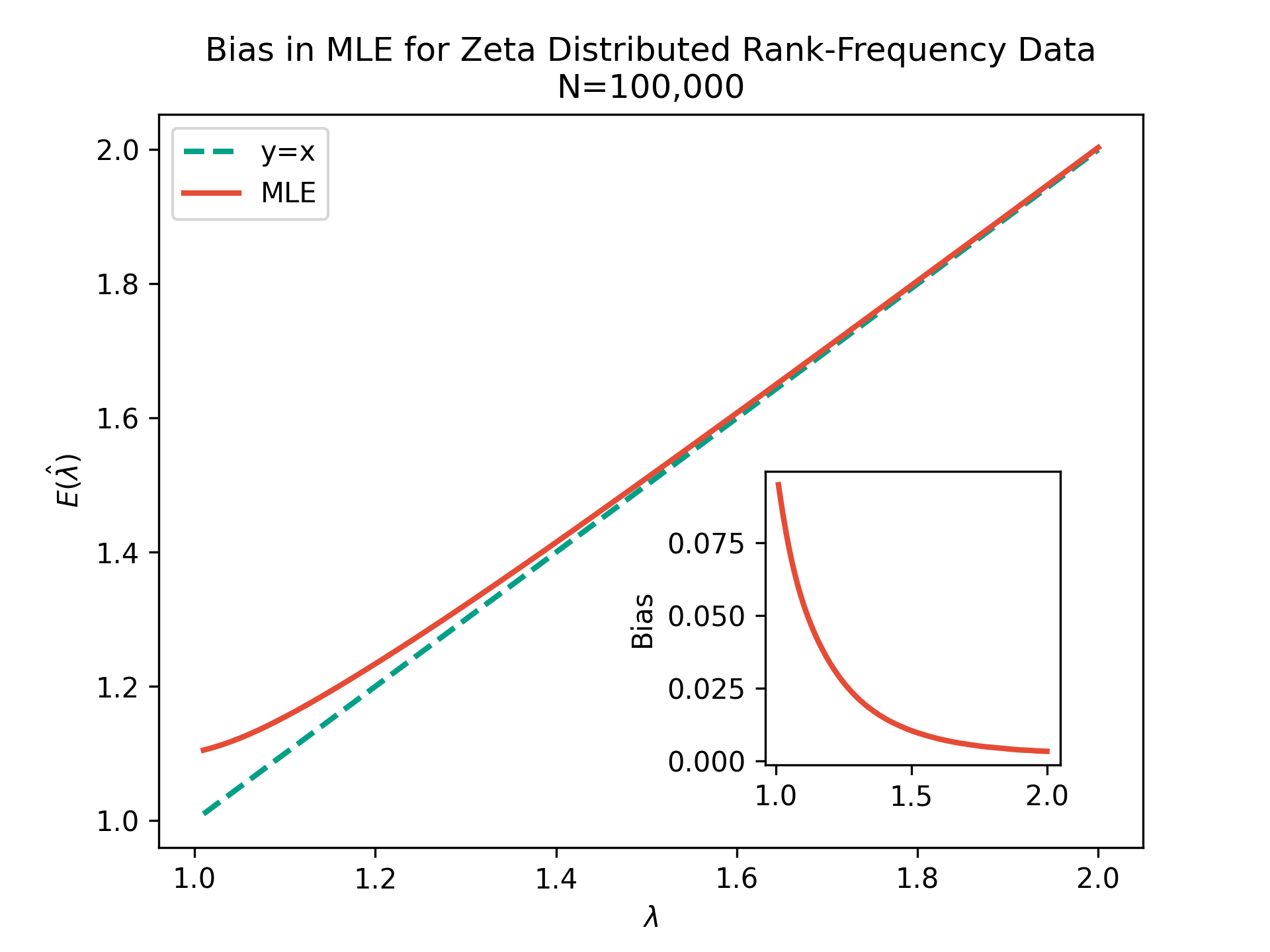
The prevailing maximum likelihood estimators for inferring power law models from rank-frequency data are biased. The source of this bias is an inappropriate likelihood function. The correct likelihood function is derived and shown to be computationally intractable. A more computationally efficient method of approximate Bayesian computation (ABC) is explored. This method is shown to have less bias for data generated from idealised rank-frequency Zipfian distributions. However, the existing estimators and the ABC estimator described here assume that words are drawn from a simple probability distribution, while language is a much more complex process. We show that this false assumption leads to continued biases when applying any of these methods to natural language to estimate Zipf exponents. We recommend caution when applying maximum likelihood estimation to investigate power laws in rank-frequency data, and suggest that researchers instead consider using graphical methods such as ordinary least squares and/or transform the data to a frequency-size representation.
翻译:从等级频率数据推算权力法模型的通用最大概率估计值存在偏差。 这种偏差的来源是一个不适当的概率函数。 正确的概率函数被衍生出来, 并显示是难以计算性的。 探索一种更符合计算效率的贝叶斯计算方法( ABC ) 。 这种方法被证明对于从理想的等级频率Zipfian分布中生成的数据而言, 其偏差较小。 但是, 这里描述的现有估计值和ABC估计值假定, 单词是从简单的概率分布中提取的, 而语言则是一个复杂得多的过程。 我们表明, 在将任何这些方法应用于自然语言以估计Zipf 提示值时, 错误假设会导致持续的偏差。 我们建议, 在使用最大可能性估计来调查等级频率数据中的权力法时, 要小心谨慎, 并建议研究人员考虑使用图形方法, 如普通最小平方和( 或) 将数据转换为频率大小表示法 。