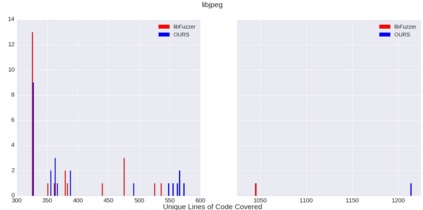
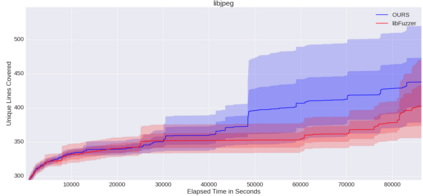
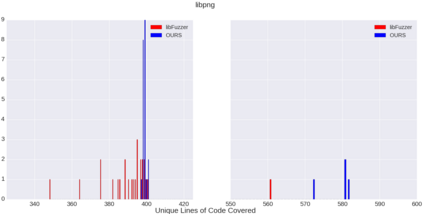
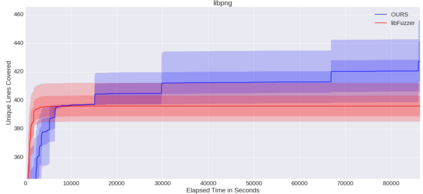
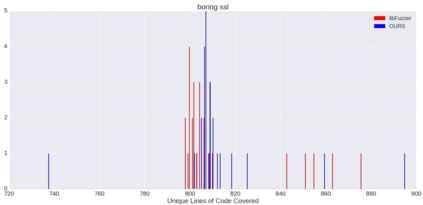
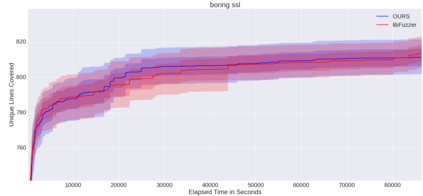
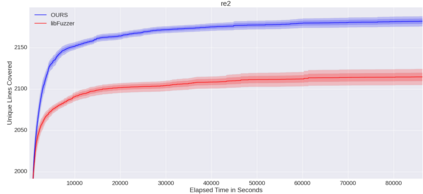
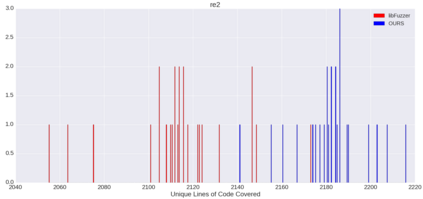
Fuzzing is a commonly used technique designed to test software by automatically crafting program inputs. Currently, the most successful fuzzing algorithms emphasize simple, low-overhead strategies with the ability to efficiently monitor program state during execution. Through compile-time instrumentation, these approaches have access to numerous aspects of program state including coverage, data flow, and heterogeneous fault detection and classification. However, existing approaches utilize blind random mutation strategies when generating test inputs. We present a different approach that uses this state information to optimize mutation operators using reinforcement learning (RL). By integrating OpenAI Gym with libFuzzer we are able to simultaneously leverage advancements in reinforcement learning as well as fuzzing to achieve deeper coverage across several varied benchmarks. Our technique connects the rich, efficient program monitors provided by LLVM Santizers with a deep neural net to learn mutation selection strategies directly from the input data. The cross-language, asynchronous architecture we developed enables us to apply any OpenAI Gym compatible deep reinforcement learning algorithm to any fuzzing problem with minimal slowdown.
翻译:模糊是一种常用的技术,用来通过自动编造程序输入来测试软件。 目前,最成功的模糊算法强调简单、低管战略,能够在实施过程中有效监测程序状态。 通过编译时间仪,这些方法可以使用程序状态的诸多方面,包括覆盖范围、数据流和各种故障的检测和分类。 但是,现有的方法在生成测试输入时使用盲随机突变策略。我们提出了一种不同的方法,使用这种状态信息来利用强化学习优化突变操作员。通过将 OpenAI Gym 和 libFuzzer 结合在一起,我们可以同时利用强化学习方面的进步和模糊,以达到不同基准的更深度覆盖。我们的技术将LLLVM Santizers 提供的丰富、高效的程序监测器与一个深层神经网连接起来,以便直接从输入数据中学习突变选择战略。我们开发的跨语言、交错结构使我们能够在任何模糊且减速的问题中应用任何 OpenAI Gym兼容的深度增强学习算法。