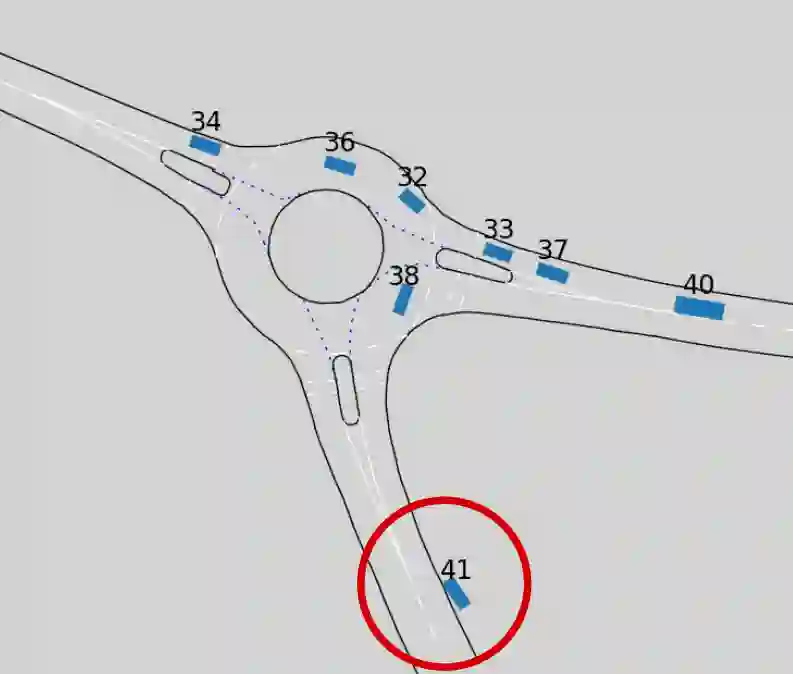
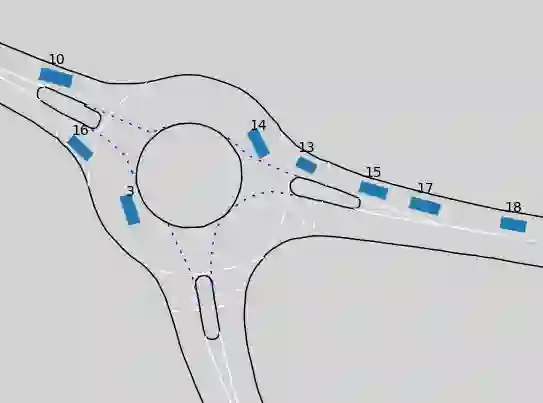
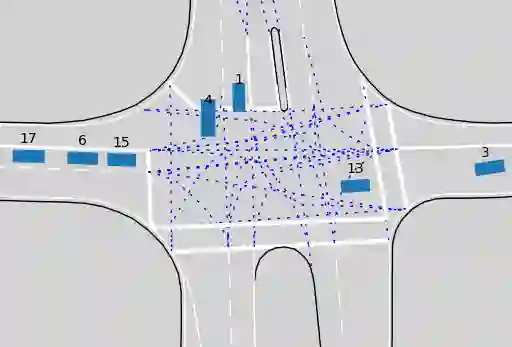
For the classification of traffic scenes, a description model is necessary that can describe the scene in a uniform way, independent of its domain. A model to describe a traffic scene in a semantic way is described in this paper. The description model allows to describe a traffic scene independently of the road geometry and road topology. Here, the traffic participants are projected onto the road network and represented as nodes in a graph. Depending on the relative location between two traffic participants with respect to the road topology, semantically classified edges are created between the corresponding nodes. For concretization, the edge attributes are extended by relative distances and velocities between both traffic participants with regard to the course of the lane. An important aspect of the description is that it can be converted easily into a machine-readable format. The current description focuses on dynamic objects of a traffic scene and considers traffic participants, such as pedestrians or vehicles.
翻译:为了对交通场景进行分类,必须有一个描述模型,能够以统一的方式描述现场,独立于其领域。本文描述了用语义方式描述交通场景的模型。描述模型可以描述交通场景,独立于道路几何和道路地形。这里,交通参与者被投射到公路网络上,在图中以节点表示。根据两个交通参与者在道路地形方面的相对位置,在相应的节点之间建立了语义分类边缘。对于混凝土而言,边缘特征是按交通参与者之间相对距离和速度在航道上的延伸的。描述的一个重要方面是,交通参与者可以很容易地转换成机器可读的格式。目前的描述侧重于交通场的动态物体,并考虑行人或车辆等交通参与者。