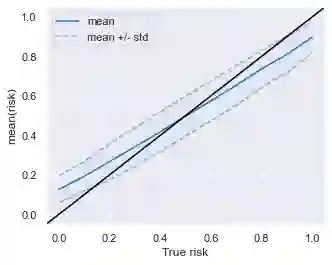
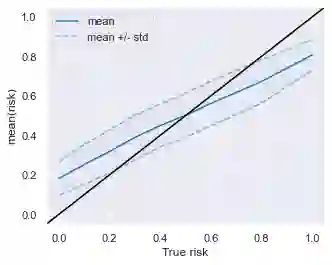
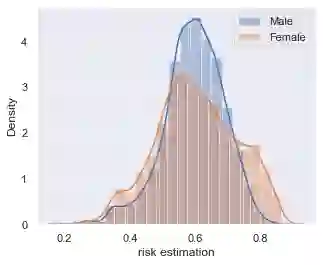
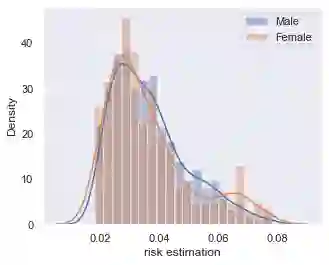
Data owners face increasing liability for how the use of their data could harm under-priviliged communities. Stakeholders would like to identify the characteristics of data that lead to algorithms being biased against any particular demographic groups, for example, defined by their race, gender, age, and/or religion. Specifically, we are interested in identifying subsets of the feature space where the ground truth response function from features to observed outcomes differs across demographic groups. To this end, we propose FORESEE, a FORESt of decision trEEs algorithm, which generates a score that captures how likely an individual's response varies with sensitive attributes. Empirically, we find that our approach allows us to identify the individuals who are most likely to be misclassified by several classifiers, including Random Forest, Logistic Regression, Support Vector Machine, and k-Nearest Neighbors. The advantage of our approach is that it allows stakeholders to characterize risky samples that may contribute to discrimination, as well as, use the FORESEE to estimate the risk of upcoming samples.
翻译:利益攸关方希望确定导致算法偏向任何特定人口群体(例如按种族、性别、年龄和(或)宗教界定的种族、年龄和(或)宗教)的数据特征。具体地说,我们有兴趣确定地貌空间的子集,在这些子集中,地面真相反应从特征到观察到的结果在不同的人口群体中产生不同的作用。为此,我们建议FORESEE,这是决定TREES算法的先导,它产生一个分数,可以捕捉到一个人的反应可能因敏感属性的不同而不同的可能性。我们发现,我们的方法使我们能够确定最有可能被数个分类者错误分类的个人,包括随机森林、后勤支助、支持矢量机器和k-Nearest Nieghbors。我们的方法的好处是,它允许利益攸关方对可能导致歧视的风险样品进行定性,并使用FORESEEE来估计即将到的样品的风险。