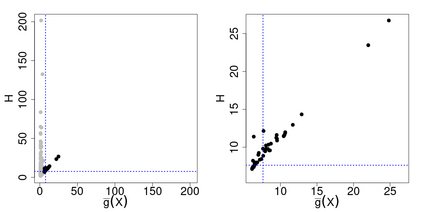
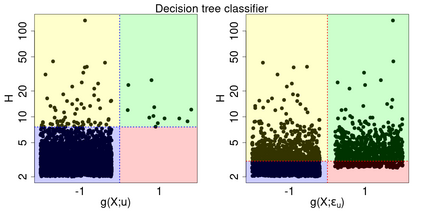
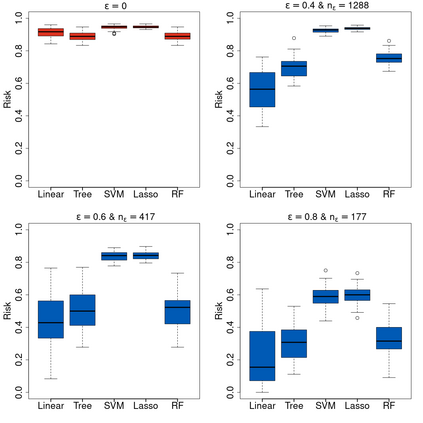
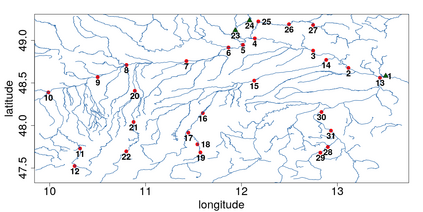
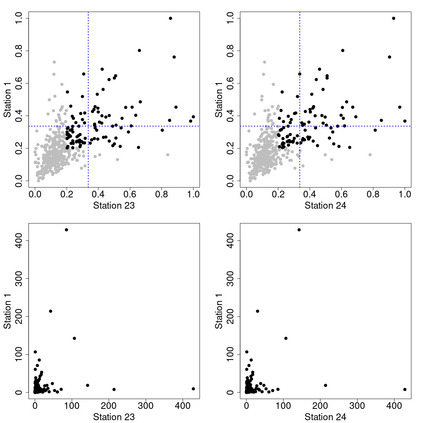
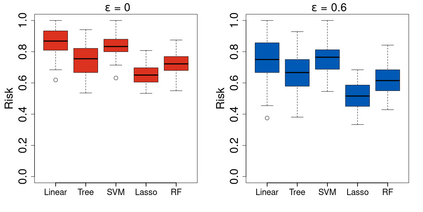
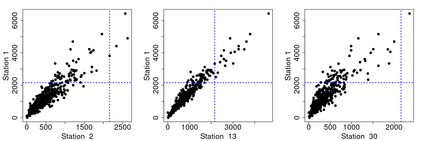
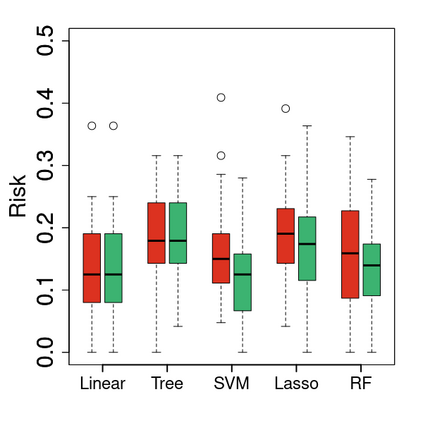
Machine learning classification methods usually assume that all possible classes are sufficiently present within the training set. Due to their inherent rarities, extreme events are always under-represented and classifiers tailored for predicting extremes need to be carefully designed to handle this under-representation. In this paper, we address the question of how to assess and compare classifiers with respect to their capacity to capture extreme occurrences. This is also related to the topic of scoring rules used in forecasting literature. In this context, we propose and study a risk function adapted to extremal classifiers. The inferential properties of our empirical risk estimator are derived under the framework of multivariate regular variation and hidden regular variation. A simulation study compares different classifiers and indicates their performance with respect to our risk function. To conclude, we apply our framework to the analysis of extreme river discharges in the Danube river basin. The application compares different predictive algorithms and test their capacity at forecasting river discharges from other river stations. As a byproduct, we study the special class of linear classifiers, show that the optimisation of our risk function leads to a consistent solution and we identify the explanatory variables that contribute the most to extremal behavior.
翻译:机械学习分类方法通常假定,所有可能的班级在培训中都有足够的存在。极端事件由于其固有的差异性,其代表性总是不足,为预测极端事件而专门设计的分类师需要仔细设计,才能处理这种代表性不足的问题。在本文件中,我们处理如何评估和比较分类员捕捉极端事件的能力的问题。这也与预测文献中使用的评分规则的主题有关。在这方面,我们提议并研究一种适应极端分类员的风险功能。我们的经验风险估计员的推论性特性来自多变常变常变和隐藏的经常变异的框架。模拟研究比较了不同的分类员,并表明他们在我们的风险功能方面的表现。结论是,我们运用我们的框架来分析多瑙河河流域极端河流排放的情况。应用不同的预测算法并测试他们从其他河流站预测河流排放的能力。作为副产品,我们研究线性分类员的特殊类别,显示我们风险函数的优化导致一个一致的解决方案,我们找出最有助于极端行为的解释变量。