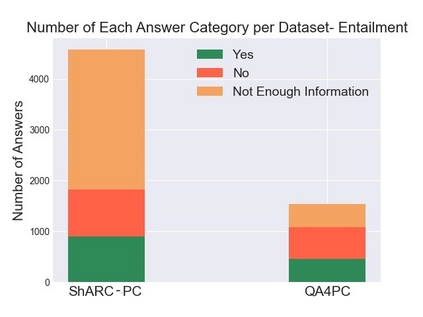
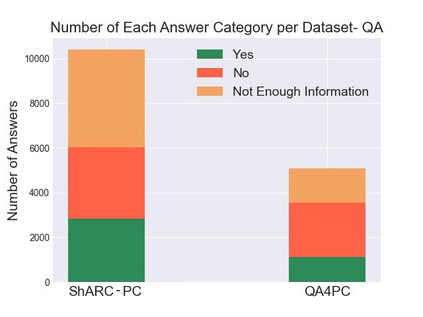
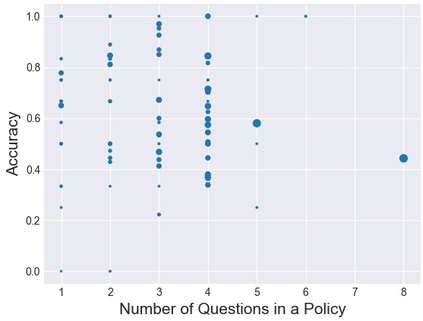
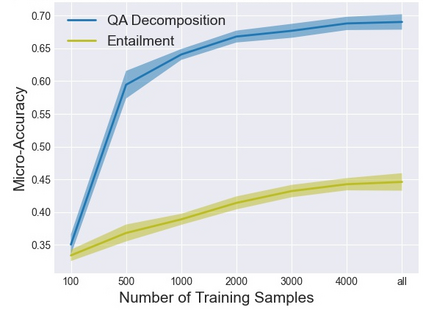
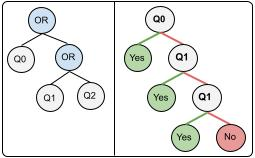
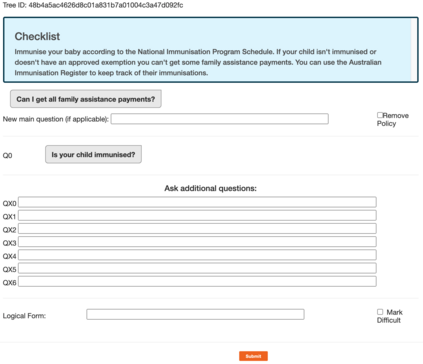
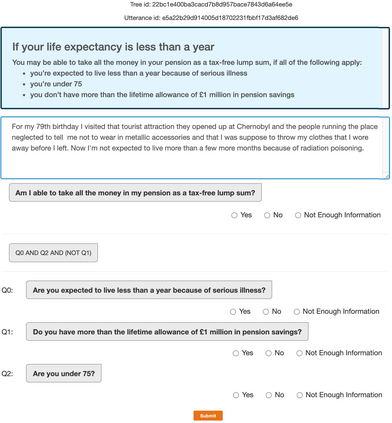
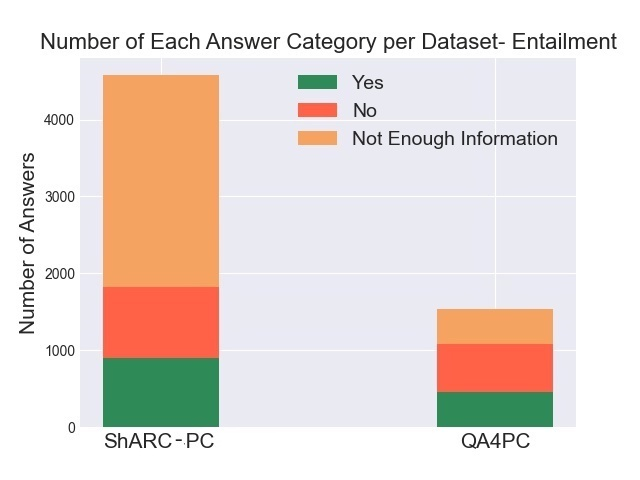
Policy compliance detection is the task of ensuring that a scenario conforms to a policy (e.g. a claim is valid according to government rules or a post in an online platform conforms to community guidelines). This task has been previously instantiated as a form of textual entailment, which results in poor accuracy due to the complexity of the policies. In this paper we propose to address policy compliance detection via decomposing it into question answering, where questions check whether the conditions stated in the policy apply to the scenario, and an expression tree combines the answers to obtain the label. Despite the initial upfront annotation cost, we demonstrate that this approach results in better accuracy, especially in the cross-policy setup where the policies during testing are unseen in training. In addition, it allows us to use existing question answering models pre-trained on existing large datasets. Finally, it explicitly identifies the information missing from a scenario in case policy compliance cannot be determined. We conduct our experiments using a recent dataset consisting of government policies, which we augment with expert annotations and find that the cost of annotating question answering decomposition is largely offset by improved inter-annotator agreement and speed.
翻译:政策合规性检测的任务是确保一种情景符合政策(例如,根据政府规则或在线平台中的职位符合社区准则,索赔是有效的),这项任务以前曾被作为文字要求的形式即刻起,由于政策的复杂性,导致不准确。在本文件中,我们提议通过将政策合规性检测分解成问题解答来解决政策合规性检测问题,在这些问题中,检查政策中所述条件是否适用于该情景,而表达式树结合了获取标签的答案。尽管最初的预先说明费用很高,但我们证明,在培训中看不到测试期间的政策的跨政策设置中,这一方法的准确性更高。此外,它使我们能够利用现有的问题解答模式,事先对现有的大型数据集进行了培训。最后,它明确指出了在政策合规性无法确定的情况下从假设中缺失的信息。我们用一个由政府政策组成的最新数据集进行实验,我们用专家说明来补充了这些数据,并且发现,用更好的内部协议和速度来抵消了说明解析问题的成本。