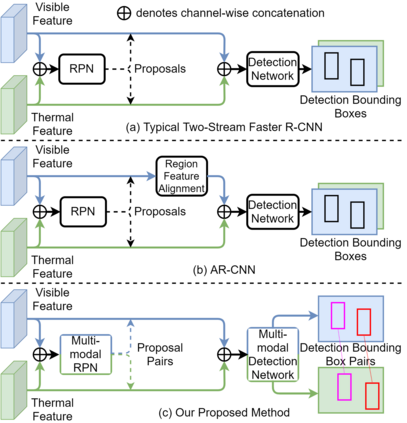
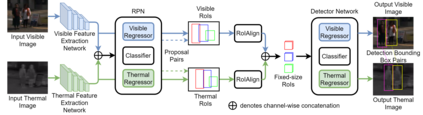
The combined use of multiple modalities enables accurate pedestrian detection under poor lighting conditions by using the high visibility areas from these modalities together. The vital assumption for the combination use is that there is no or only a weak misalignment between the two modalities. In general, however, this assumption often breaks in actual situations. Due to this assumption's breakdown, the position of the bounding boxes does not match between the two modalities, resulting in a significant decrease in detection accuracy, especially in regions where the amount of misalignment is large. In this paper, we propose a multi-modal Faster-RCNN that is robust against large misalignment. The keys are 1) modal-wise regression and 2) multi-modal IoU for mini-batch sampling. To deal with large misalignment, we perform bounding box regression for both the RPN and detection-head with both modalities. We also propose a new sampling strategy called "multi-modal mini-batch sampling" that integrates the IoU for both modalities. We demonstrate that the proposed method's performance is much better than that of the state-of-the-art methods for data with large misalignment through actual image experiments.
翻译:结合使用多种模式,可以使用这些模式的高可见度区域,在照明条件差的情况下对行人进行准确的探测。混合使用的关键假设是两种模式之间没有或只是微弱的不匹配。但一般而言,这种假设往往在实际情况下打破。由于这一假设的崩溃,捆绑箱的位置与这两种模式不匹配,导致检测准确性显著下降,特别是在不匹配程度大的区域。在本文中,我们建议采用一种多式的快速加速-RCNNN,能够抵御大不匹配。关键是:(1) 模式性回归和(2) 用于微型批量取样的多式IOU。要处理大不匹配,我们用两种模式对RPN和检测头都进行捆绑式的回归。我们还提出一个新的取样战略,称为“多式微型批量取样”,将IOU结合到两种模式。我们证明,拟议方法的性能比用实际图像对大错位数据进行实验的状态方法要好得多。