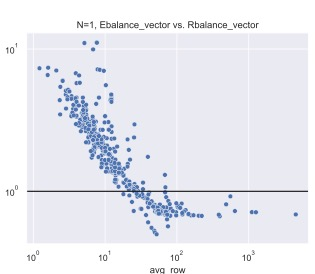
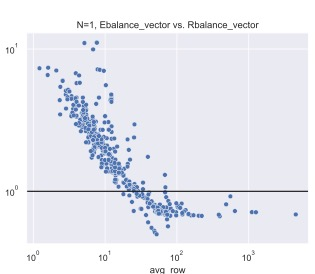
Sparse matrix-vector and matrix-matrix multiplication (SpMV and SpMM) are fundamental in both conventional (graph analytics, scientific computing) and emerging (sparse DNN, GNN) domains. Workload-balancing and parallel-reduction are widely-used design principles for efficient SpMV. However, prior work fails to resolve how to implement and adaptively use the two principles for SpMV/MM. To overcome this obstacle, we first complete the implementation space with optimizations by filling three missing pieces in prior work, including: (1) We show that workload-balancing and parallel-reduction can be combined through a segment-reduction algorithm implemented with SIMD-shuffle primitives. (2) We show that parallel-reduction can be implemented in SpMM through loading the dense-matrix rows with vector memory operations. (3) We show that vectorized loading of sparse rows, being a part of the benefit of parallel-reduction, can co-exist with sequential-reduction in SpMM through temporally caching sparse-matrix elements in the shared memory. In terms of adaptive use, we analyze how the benefit of two principles change with two characteristics from the input data space: the diverse sparsity pattern and dense-matrix width. We find the benefit of the two principles fades along with the increased total workload, i.e. the increased dense-matrix width. We also identify, for SpMV and SpMM, different sparse-matrix features that impact workload-balancing effectiveness. Our design consistently exceeds cuSPARSE by 1.07-1.57x on different GPUs and dense matrix width, and the kernel selection rules involve 5-12% performance loss compared with optimal choices. Our kernel is being integrated into popular graph learning frameworks to accelerate GNN training.
翻译:在常规领域(分析、科学计算)和新兴领域(Smarse DNN、GNN),工作平衡和平行减少是高效 SmMV广泛采用的设计原则。然而,先前的工作未能解决如何实施和适应SpMV/MM的两种原则。为了克服这一障碍,我们首先通过填补先前工作中的三个缺失部分来优化执行空间,包括:(1) 我们表明,工作量平衡和平行减少可以通过与SIMD-Scream-Sweal Sheldle Friminal执行的减少段数算法相结合。(2) 我们表明,通过将密度匹配行与矢量存储操作加载,可以实现平行减少。(3) 我们表明,稀释行的矢量加载是平行减少的一个好处,通过在共享记忆中时间缓缓缓缓流的普通部分,通过适应性使用,我们分析两项原则的效益是如何通过SMMD-S-real-real-realal-loral-loral-lvacal-lvical sal-lview lax mess dreal lax dal lax dal lax dal lax dal lax dal dal lax lax lax lax lax lax lax lax lax laut lax lax lax laut lax lax laut laut le le le lex lex lex lex lex lex lex legal lex lex legal lex legal lex lax lax lax lax lax lax lax lax le lax lax lax le le le le le le le le le le le le ladal lex labalal le) labal ladal lax lax lax lax lax lax lax lax lax lax lax lacal lacal lax lax lax lax le le