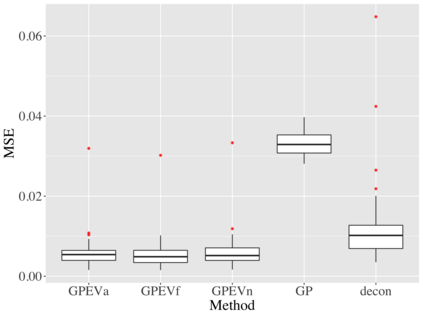
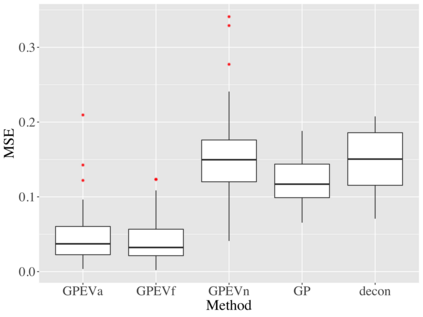
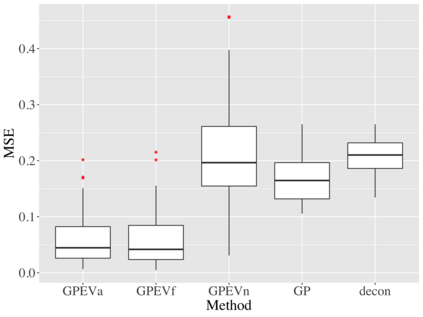
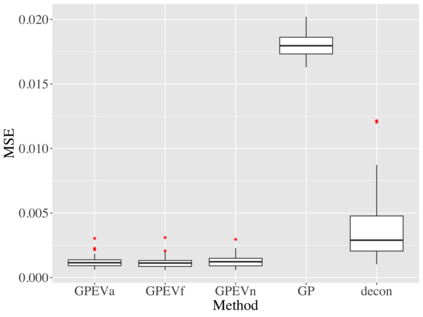
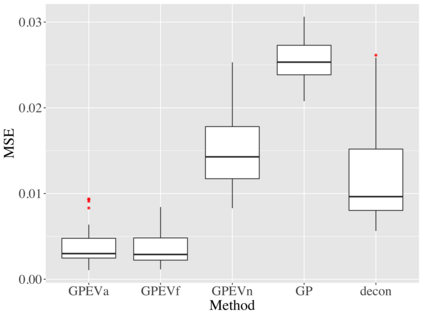
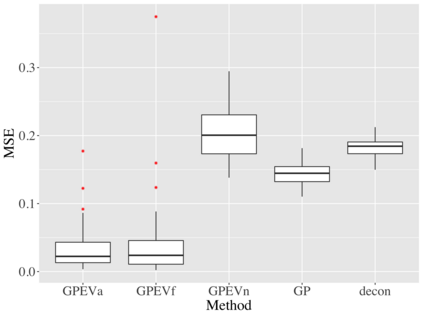
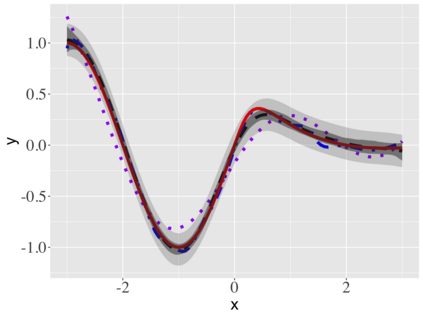
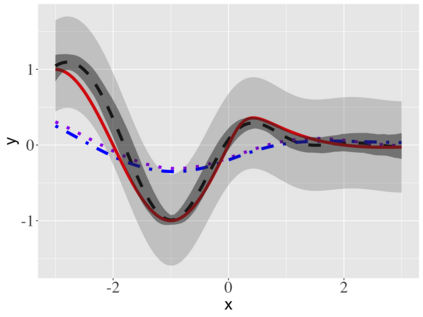
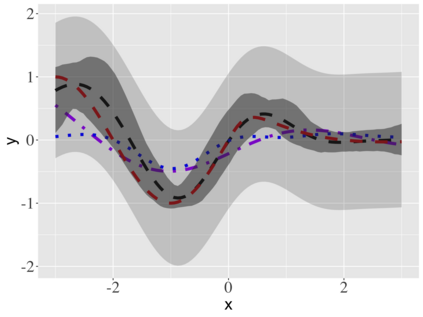
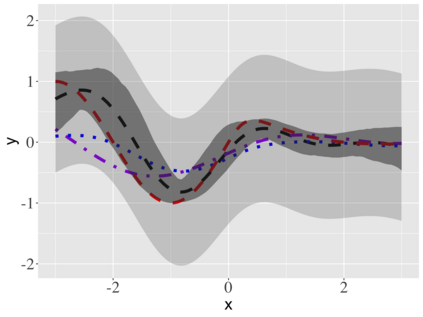
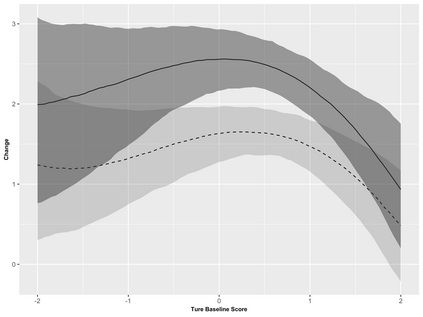
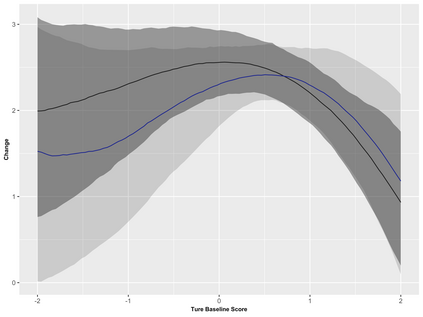
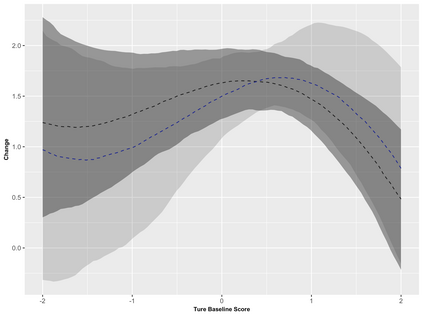
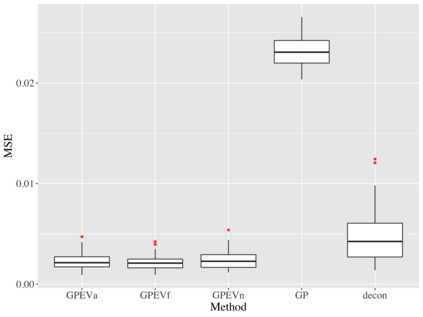
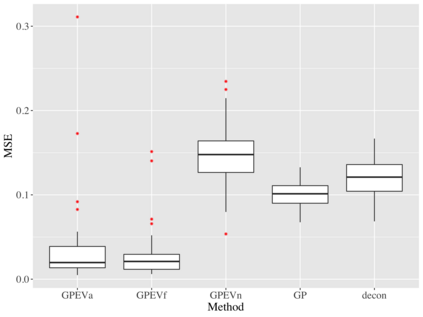
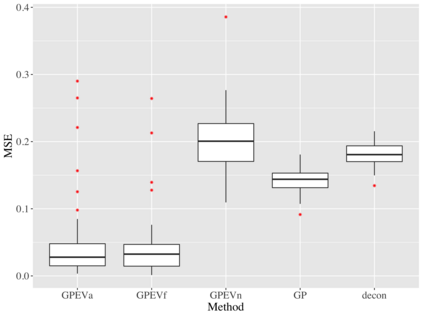
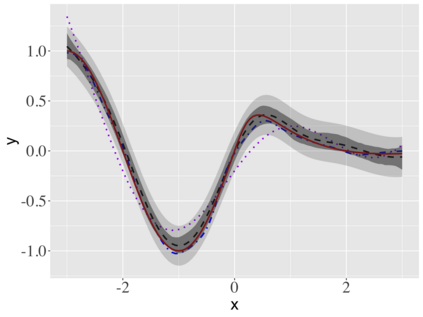
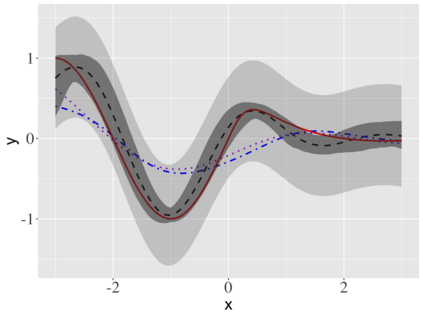
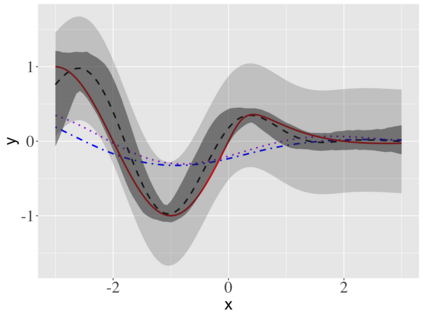
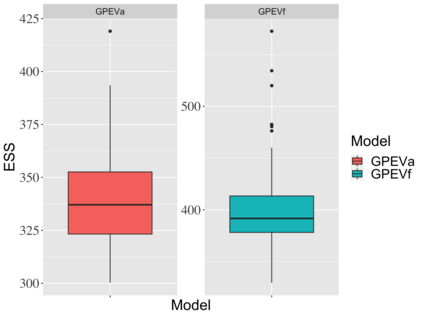
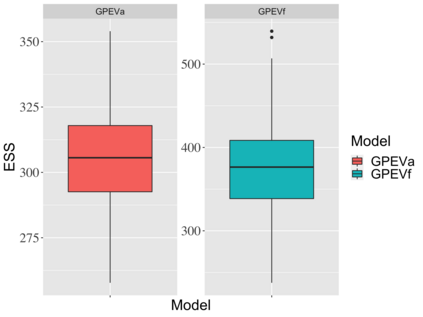
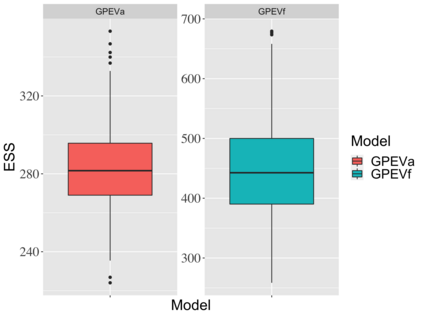
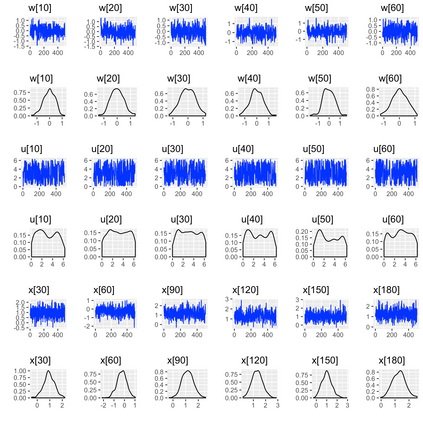
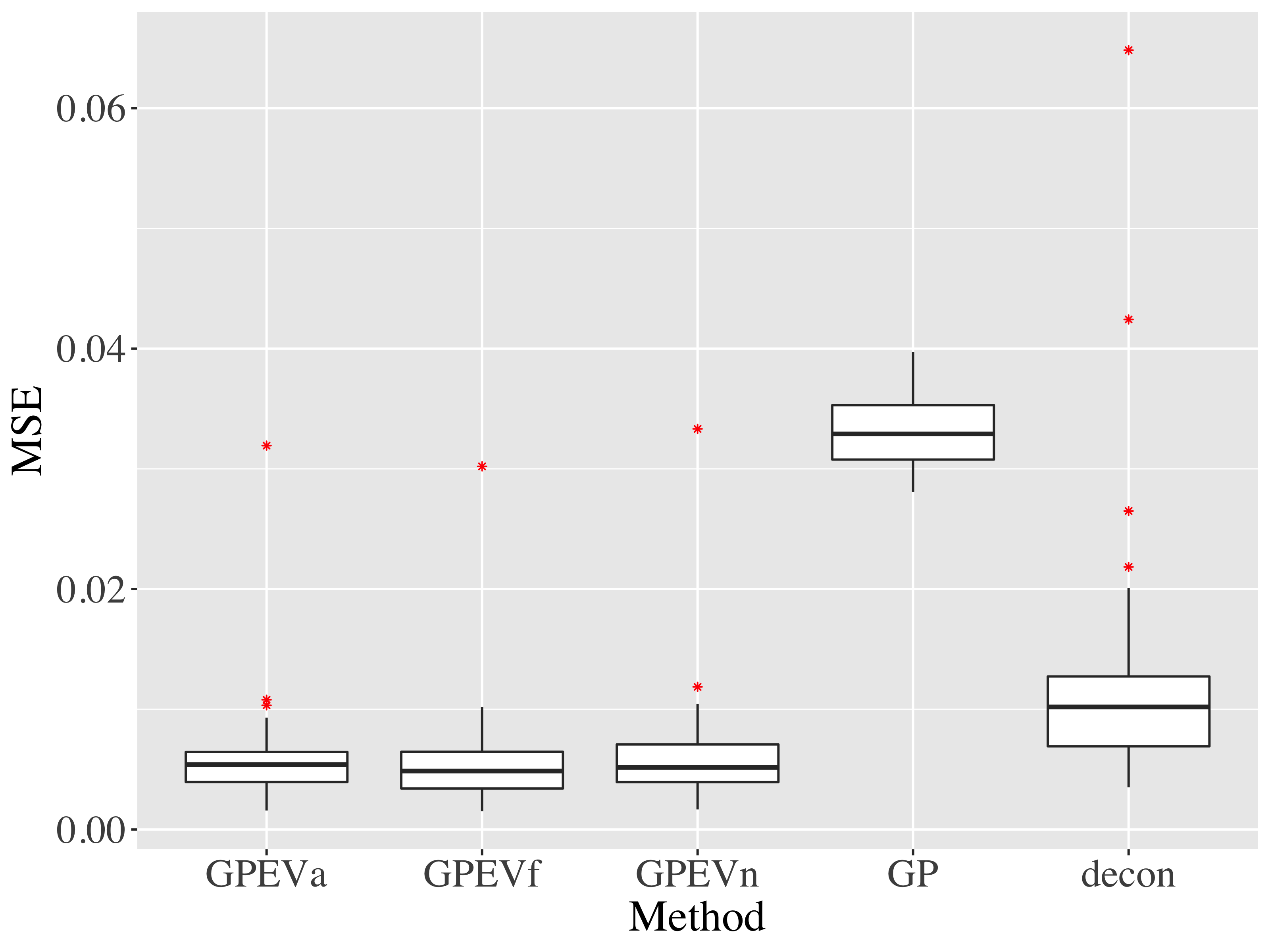
Covariate measurement error in nonparametric regression is a common problem in nutritional epidemiology and geostatistics, and other fields. Over the last two decades, this problem has received substantial attention in the frequentist literature. Bayesian approaches for handling measurement error have only been explored recently and are surprisingly successful, although the lack of a proper theoretical justification regarding the asymptotic performance of the estimators. By specifying a Gaussian process prior on the regression function and a Dirichlet process Gaussian mixture prior on the unknown distribution of the unobserved covariates, we show that the posterior distribution of the regression function and the unknown covariates density attain optimal rates of contraction adaptively over a range of H\"{o}lder classes, up to logarithmic terms. This improves upon the existing classical frequentist results which require knowledge of the smoothness of the underlying function to deliver optimal risk bounds. We also develop a novel surrogate prior for approximating the Gaussian process prior that leads to efficient computation and preserves the covariance structure, thereby facilitating easy prior elicitation. We demonstrate the empirical performance of our approach and compare it with competitors in a wide range of simulation experiments and a real data example.
翻译:在非参数回归中的共变测量误差是营养流行病学和地理统计学以及其他领域的一个常见问题。 在过去20年中,这个问题在经常文献中受到大量关注。 贝伊斯处理测量误差的方法最近才被探索过,而且令人惊讶地取得成功, 尽管对于估算器的无参数性能缺乏适当的理论依据。 在回归函数和 Dirichlet 进程之前,在未观测的 Covarite 和 Dirichlet 之前指定一个高斯进程, Gaussian 混合物, 在未观测的 Covarite 的未知分布之前,我们发现,回归函数的后方分布和未知的共变密度在一系列H\"{o}lder类中达到最佳收缩率,达到对数术语的调和率。这改进了现有的古典的经常现象性结果,需要了解基本功能的平稳性能,才能提供最佳的风险界限。 我们还开发了一个新型的代位模型, 之前可以导致高效的计算并保存共变性结构,从而便利了先前的变异性结构, 从而便于进行真正的模拟实验。 我们用真实的实验性试验, 。