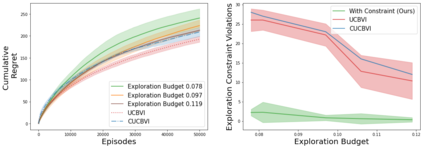
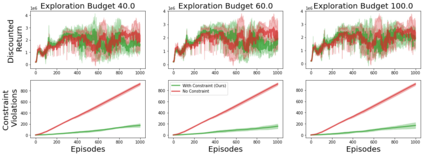
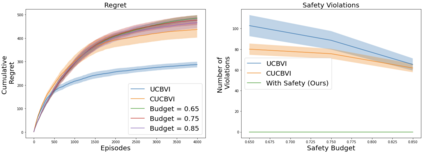
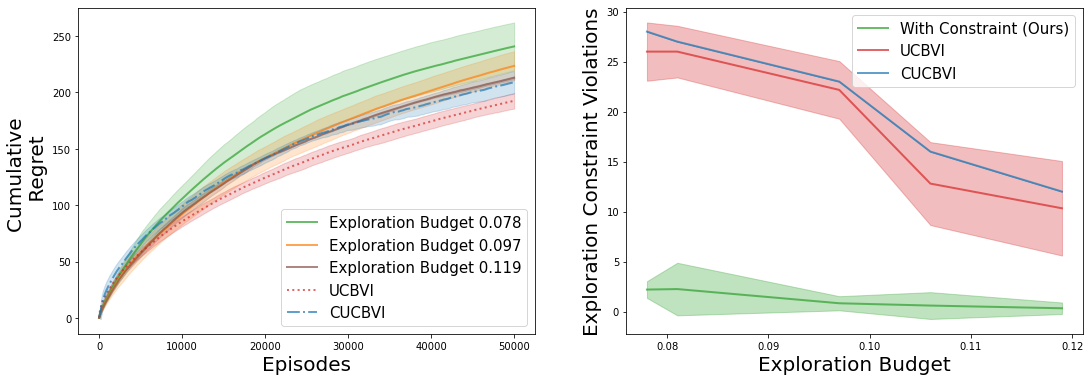
A key challenge to deploying reinforcement learning in practice is avoiding excessive (harmful) exploration in individual episodes. We propose a natural constraint on exploration -- \textit{uniformly} outperforming a conservative policy (adaptively estimated from all data observed thus far), up to a per-episode exploration budget. We design a novel algorithm that uses a UCB reinforcement learning policy for exploration, but overrides it as needed to satisfy our exploration constraint with high probability. Importantly, to ensure unbiased exploration across the state space, our algorithm adaptively determines when to explore. We prove that our approach remains conservative while minimizing regret in the tabular setting. We experimentally validate our results on a sepsis treatment task and an HIV treatment task, demonstrating that our algorithm can learn while ensuring good performance compared to the baseline policy for every patient; the latter task also demonstrates that our approach extends to continuous state spaces via deep reinforcement learning.
翻译:在实践中运用强化学习的关键挑战是避免在个别情况下进行过度(有害)的探索。我们提议对勘探实行自然限制 -- -- \ textit{unformactly} 优于保守政策(根据迄今所观察到的所有数据进行估算),达到每个元素的勘探预算。我们设计了一种新型算法,在勘探时使用UCB强化学习政策,但根据需要,以极有可能的方式取代它,以满足我们的勘探限制。重要的是,为了确保在州空间进行无偏见的探索,我们的算法在适应性地决定了何时进行探索。我们证明我们的方法仍然保守,同时在表格设置中尽量减少遗憾。我们实验验证了我们关于浸泡剂治疗任务和艾滋病毒治疗任务的结果,表明我们的算法可以学习,同时确保每个患者与基线政策相比取得良好的业绩;后一项任务还表明,我们的方法通过深强化学习延伸到连续状态空间。</s>